最近谷歌发布了Gemini 2.0 Flash的图像生成模型,可以通过自然语言与AI沟通,达成各种生图功能。

一、使用方法
目前可以通过谷歌Ai Studio登录,免费使用(需要畅通的网络):

登录之后在模型下拉菜单中,选择Gemini 2.0 Flash (Image Generation) Experimental即可:

二、实测
1、局部重绘+风格重绘
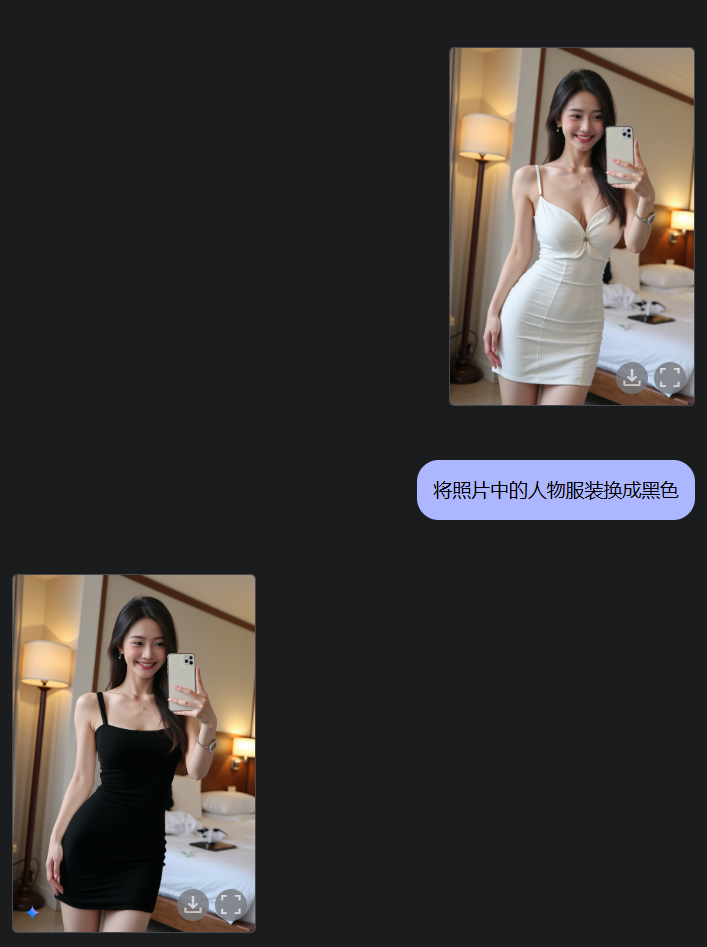
首先文生图,并要求AI对人物换装(局部重绘)。可以看到,人物的原形保持很好:

在旁边增加新的人物(局部重绘),并摆出不同的姿势(角色参考):

Gemini 2.0 Flash支持修改本地(上传)图片,换装(局部重绘)同样很顺利:
改变图像画风(风格重绘),实测这个功能对提示词的准确度要求较高,经过几次尝试,成功:

2、扩图
要求AI将图像画幅扩大(扩图),结果完美:

3、光影控制
对光线进行修改(光影控制),之前可能要用到IC-Light之类的专门工具,现在就是一句话的工夫:

继续尝试其它光照效果,AI对提示词的遵从度确实比较高:

替换场景(局部重绘)+改变光照(光影控制):

上面的复合功能都能做到,改变人物也就是小菜一碟:

4、分镜头生成
AI绘画,如何保持一致性是个大的挑战。这里我们尝试改变照片视角:

基于原来的场景,进一步改变角度和动作(分镜),效果比较满意:

再尝试用女明星照片,多个角度测试,结论是,AI确实理解并贯彻了人物的外形特征:


在此基础上,进一步改变景别:

相比前面的案例,这里AI的“脑补”能力进一步得到体现:

基于这样强大的功能,AI视频创作中的一致性问题将逐渐得到解决。
三、结论:
1、Gemini 2.0 Flash未必能一次得出满意的效果,但支持连续对话,最终也能达到良好的效果。
2、自然语言(无门槛)的交互方式+“大一统”生图功能,Gemini 2.0 Flash或许是给未来的AI生图工具树立了新的标杆。
3、AI工具越来越强,Photoshop的市场会被进一步压缩了!