在计算机视觉和自然语言处理的交叉领域,图像描述(image captioning)一直是一项核心挑战,尤其是如何为图像中的特定区域生成精确、详细的描述。
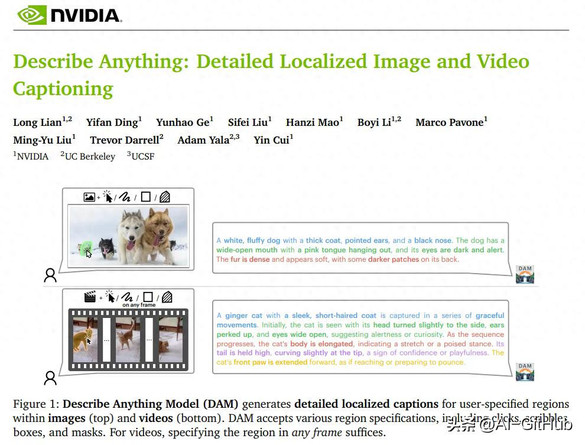
前段时间,来自英伟达、UC伯克利等机构的研究者推出了“描述一切模型”DAM(Describe Anything Model),这是一个革命性的多模态大语言模型,能够针对用户指定的图像或视频区域,生成丰富的上下文描述。
功能特征:
DAM是一个强大的视觉语言模型(VLM),专为生成图像或视频中特定区域的详细描述而设计。用户可以通过点、框、涂鸦或蒙版等方式指定区域,模型会输出包含细微属性(如纹理、颜色、形状)的丰富描述。
例如,在视频中指定一头母牛的区域,DAM能捕捉其动态姿态:
“一头身披深棕色皮毛、臀部有一块浅色斑块的母牛,正以一系列动作展现其姿态。起初,母牛略微低着头,展现出平静的神态。随着画面的推进,母牛开始向前移动,双腿舒展,步态稳健而有节奏……”

类似地,在静态图像中指定一只猫的区域,模型也能生成精准描述:
“一只白色的猫,有着浅橙色的耳朵和粉红色的鼻子。这只猫表情放松,眼睛微微闭合,身上覆盖着柔软的白色毛发。”

详细的本地化字幕:为图像中用户指定的区域生成详细的本地化描述。DAM 接受各种用户输入以进行区域规范,包括点击、涂鸦、框和蒙版。
高度详细的图像和视频字幕:通过平衡焦点区域的清晰度与全局上下文,该模型可以突出细微的特征,例如复杂的图案或不断变化的纹理,远远超出一般图像级字幕所提供的范围。

指令控制字幕:无论是需要简短的总结还是冗长而复杂的叙述,模型都可以调整其输出。这种灵活性有利于从快速标记任务到深入专家分析的各种用例。

零样本区域 QA:除了描述之外,模型还可以回答有关指定区域的问题,而无需额外的训练数据。用户可以询问该地区的属性,该模型会利用其对本地化的理解来提供准确的、上下文驱动的答案。此功能增强了自然的交互式用例。

性能对比:
DAM在局部图像与视频描述任务中表现卓越,能够支持多粒度输出(包括关键词、短语及详细描述),并在7个领域内基准测试和零样本基准测试中均达到SOTA。
在 object-level LVIS和part-level PACO数据集上进行测试,DAM取得了最佳性能。
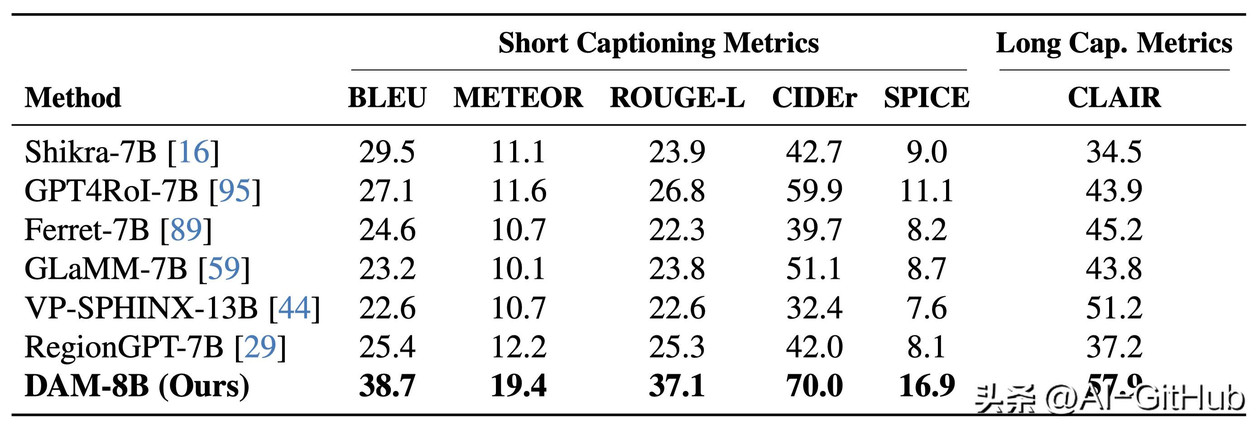
DAM在详细的本地化字幕方面优于以前的纯API模型、开原模型和特定于区域的VLM。
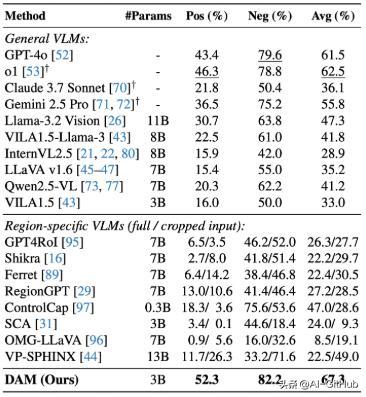
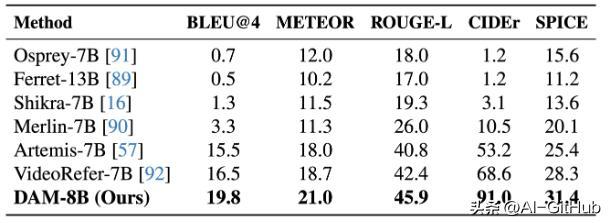
DAM在详细的本地化视频字幕方面优于以前的模型。
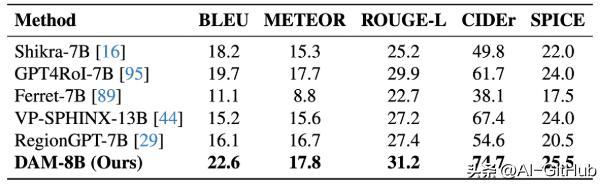
短语级数据集Flickr30k实体的零样本评估。该模型比之前的最佳水平平均相对提高了7.34%。
DAM代表了局部图像和视频描述技术的重大进步,未来有望在医疗、安防和内容创作等领域发挥更大作用。
GitHub:https://github.com/NVlabs/describe-anything
#AI开源项目推荐##github##AI技术##分割一切##图像描述#英伟达开源#DAM







