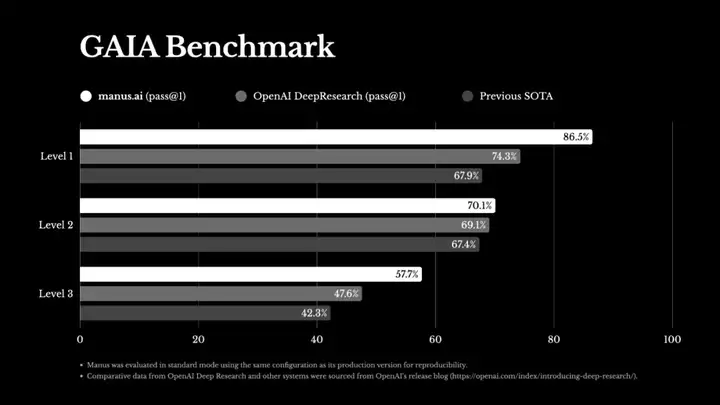
开源的风吹到视频生成:阿里开源登顶VBench的万相大模型,一手实测来了!
千问Qwen+万相Wan,阿里已实现全模态开源。当很多 AI 公司还就是否该走开源路线而感到左右为难时,阿里的技术团队又开源了一个新的模型 —— 万相(Wan)视频生成大模型(包括全部推理代码和权重,最宽松的开源协议)。经常玩视频生成模型的同学应该知道,当前的很多模型仍然面临多方面挑战,比如难以还原复杂的人物动作,处理不好物体交互时的物理变化,遇到长文本指令就「选择性遵循」等。如果三个方面都做得