

本文作者来自北京邮电大学、腾讯微信、清华大学。共同第一作者为北京邮电大学博士生乔润祺与硕士生谭秋纳,其共同完成的代表性工作 We-Math 于 ACL 2025 发表,并曾在 CVPR、ACL、ICLR、AAAI、ACM MM 等多个顶会中有论文发表。本文的通讯作者为博士生导师张洪刚与微信视觉技术中心李琛,We-Math 系列工作为乔润祺在微信实习期间完成。

- 论文标题:We-Math 2.0: A Versatile MathBook System for Incentivizing Visual Mathematical Reasoning
- 论文链接:https://arxiv.org/abs/2508.10433
- 主页链接:https://we-math2.github.io/
- 代码链接:https://github.com/We-Math/We-Math2.0
- 数据集链接:https://huggingface.co/datasets/We-Math/We-Math2.0-Standard
近期,多模态大模型在图像问答与视觉理解等任务中进展迅速。随着 Vision-R1 、MM-Eureka 等工作将强化学习引入多模态推理,数学推理也得到了一定提升。然而,在逻辑性与知识系统性要求极高的数学任务中,模型仍然达不到像人类一样进行严密推理的水平,这一问题仍然是开放性难题。
对此,我们仍然认为理想的学习范式应该是让模型先掌握所需的知识,再进一步提升泛化能力。基于这一思考,我们提出了 We-Math2.0:
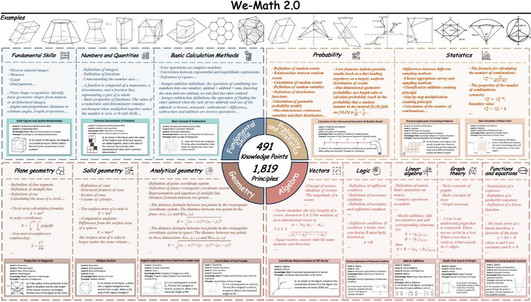
1. MathBook Knowledge System:我们首先搭建了一个系统性、完整、相对正交的知识体系:包含 5 个层级,491 个知识点与 1819 个知识原理,覆盖了小学、初中、高中以及部分大学及竞赛的知识。
2. MathBook-Standard:基于知识体系,我们发现开源数据集存在无法完整覆盖、知识无法完成解构等问题,对此我们选择对每个知识体系进行手动构建题目、画图,并结合一题多图、一图多题两种思想,实现每个知识原理对应包含多个问题。
3. MathBook-Pro:我们希望进一步构造一个以模型为中心的数据空间来提升泛化能力。基于 MathBook-Standard 与知识体系,我们通过题目所需知识点数量、视觉复杂度、场景复杂度等三个维度对题目难度进行延展,将一条训练数据拓展为 8 个不同难度的样本。
4. 训练策略:基于所构建的数据集,我们首先通过 1000 条数据进行 SFT 冷启动微调,旨在改变模型的输出范式,进一步首先利用 MathBook-Standard 的数据,构建了均值奖励,旨在通过以知识原理为单位对模型进行奖惩。在此基础上,我们利用 MathBook-Pro 的数据,构建了动态调度训练(知识调度与模态调度)从而提升模型的泛化能力。
5. MathBookEval: 为了进一步评测模型在全面知识与推理深度层面的能力,我们提出了包含 1000 条样本的 MathBookEval
为了实现严谨、高质量、具备高复杂度的图像数据,我们的全部数据均为手动利用 Geogebra 专业化软件新渲染而成,我们希望先通过手动构造高精度的数据来验证这一思想的可行性。
目前不仅在 X 上收获了一定的关注度,并且荣登 Huggingface Paper 日榜第一名!

We-Math 2.0
知识体系(MathBook knowledge system)
我们按照「定义 — 定理 — 应用」的思想构建了包含 5 个层级、491 个知识点、1819 个知识原理的知识体系,确保数学概念之间的层次关系与逻辑关联得到清晰呈现,知识点之间、知识原理之间尽可能相互独立。
具体而言,每个知识点均对应若干条基本原理。例如,在「三角形的面积」这一知识点下,细分为「三角形面积的基本公式」、「海伦公式」、「三角函数法面积公式」等不同的知识原理。
做法层面:一方面由人类专家基于教材、维基百科和国家课程标准设计初始结构;另一方面,收集开源数据集通过 GPT-4o 进行初步打标,并通过层次聚类生成知识体系。最终,由专家对两者进行融合与修改,形成高质量的知识体系。
可以在我们的网站当中看到可视化的知识体系。
MathBook-Standard:双向数据扩展策略
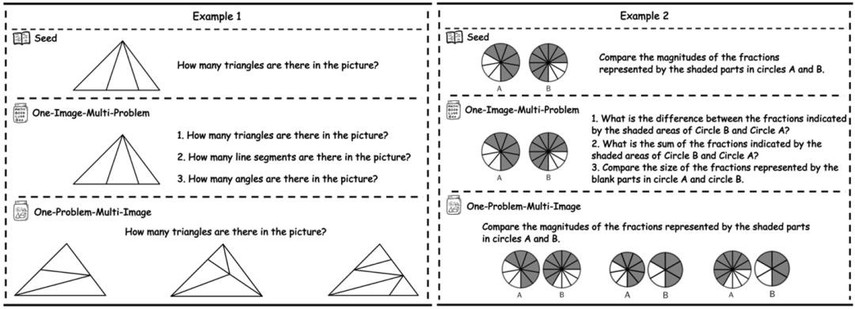
MathBook-Standard 采用「一题多图」和「一图多题」的双向数据扩展策略,每道题目都标注了对应的多层级知识点,并严格覆盖所提出的 1819 个数学知识原理。
具体而言,「一题多图」是为同一道题生成不同的视觉变式,例如,一个关于三角形的种子问题可以通过改变角度生成不同类型的三角形图像(如锐角、直角、钝角三角形),从而提升模型在同一知识原理下的泛化能力;「一图多题」则由专家基于同一图像设计多个针对不同知识原理的新问题,全面考察不同的数学知识。
- 数据集:https://huggingface.co/datasets/We-Math/We-Math2.0-Standard
MathBook-Pro
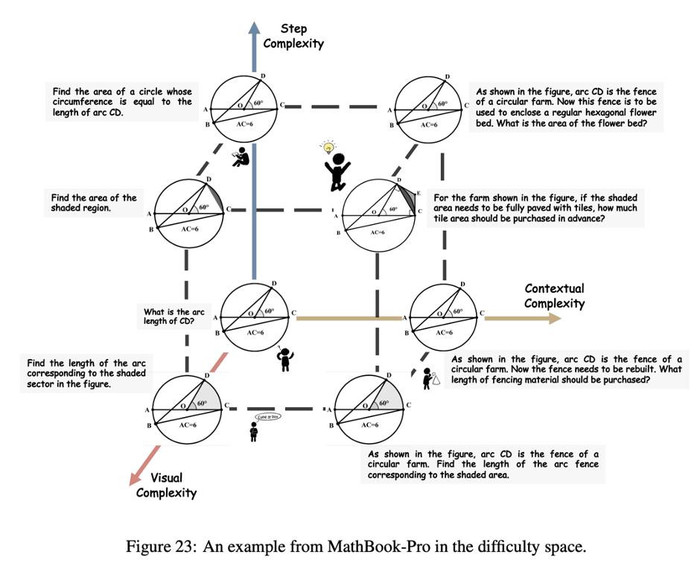
聚焦以模型为中心的学习路径,MathBook-Pro 首次实现了针对多模态数学题目的三维难度建模。具体来说,我们从以下三个维度对每个种子问题进行难度扩展:
- 推理步骤复杂度:通过增加题目涵盖的知识点数量(不少于 6 个),系统性提升题目的逻辑难度。
- 视觉复杂度:在保持核心几何结构不变的基础上,利用 GeoGebra 增加辅助元素或调整几何配置,逐步增强图像的视觉难度。
- 语境复杂度:将问题描述从简明的数学叙述拓展到更为复杂的现实或抽象情境,提升模型对语义和语境的理解能力。
每道种子题目可在这三大维度内扩展为 7 个难度层级,为后续的动态调度和强化学习训练提供坚实基础,助力模型实现更稳健的泛化能力。
- 数据集:https://huggingface.co/datasets/We-Math/We-Math2.0-Pro)
训练策略
SFT 冷启动
首先,我们精选了 1,000 条涵盖全部知识原理的数据,通过监督微调(SFT)实现模型冷启动,让模型初步掌握知识导向的推理链,激发潜力。随后,我们采用 GRPO 算法进行两阶段渐进式强化学习:
预对齐强化学习
基于 MathBook-Standard,在每组包含相同知识原理的问题中,采用均值奖励计算。对于一组变体题目:
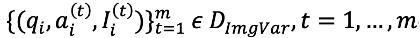
奖励计算为:
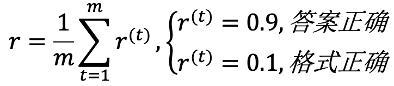
具体而言,平均奖励不仅聚焦于单个问题,还反映了模型对同一知识原理下所有问题掌握情况,从而提供更全面的评价。
动态调度学习
基于 MathBook-Pro,动态调度策略能够根据模型的错误类型,智能地调整训练数据。MathBook-Pro 为每个种子问题构建了一系列难度逐渐增加的变体,如下所示:
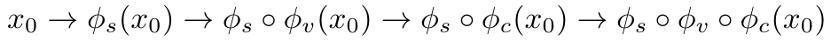
其中,s,v,c 分别表示在推理步骤、视觉和语境上的复杂度增量,这就为每个种子题目形成了一条从基础推理到高级推理的渐进路径,基于此展开的增量学习机制如下:

实验结果
主要结果
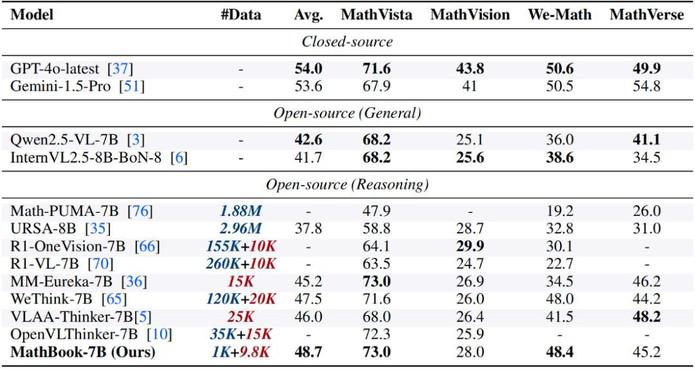
- 较 Baseline 有稳定提升:我们基于 Qwen2.5-VL-7B 开发了 MathBook-7B,并在四个主流数学推理测试集(MathVista、MathVision、MathVerse、We-Math)上进行了评估。结果显示,MathBook-7B 的平均性能较 Qwen2.5-VL-7B 提升超过 5%。
- 优异的知识泛化能力:在 MathVista 和 We-Math 测试集上,MathBook-7B 展现出优异的知识泛化能力,能够高效解决多领域的复杂多步问题及其子问题,性能超过了其他强化学习方法的基线模型。
- 用相对较少的数据解锁较大的潜力:MathBook-7B 最终用 10K 左右的数据量训练即达到与大规模数据集同等效果,充分凸显了高质量数据与结构化知识体系的高效性。
消融实验分析
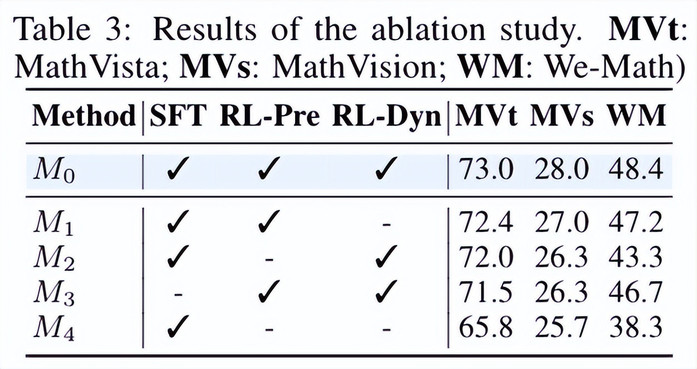
- 每个模块均有性能提升,预对齐强化学习最有效:冷启动微调与两阶段强化学习策略均提升了模型性能。特别是预对齐强化学习后的模型在 MathVista 和 We-Math 中取得了令人印象深刻的结果,这凸显了知识学习在增强数学推理能力方面的关键作用。
- SFT 带来的性能提升有限,但对于释放强化学习的潜力至关重要:SFT 有效改变了模型推理范式,为后续 RL 优化提供了基础,从而显著提升了整体性能。(可以从后续的案例分析中看到变化)
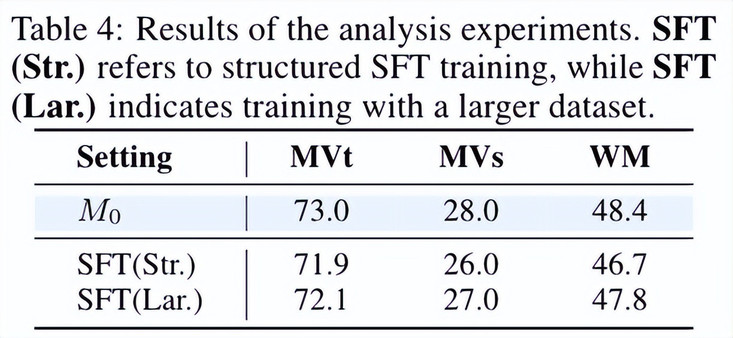
- SFT 人类自然的语言形式优于结构化形式:通过对 SFT 数据范式与规模进行分析,我们发现,采用自然语言形式的 CoT(Chain-of-Thought)作为 SFT 数据优于结构化推理链,更能激发模型灵活推理能力的提升。
- SFT 少量数据足以释放强化学习的潜力:扩大 SFT 数据规模并非总能带来更好的性能 —— 在少量精心挑选的 SFT 数据上训练的模型,其表现可与大规模数据集模型媲美,甚至更优。
实例分析

我们在附录中提供了具体的回答案例。对比表明,通过在 SFT 阶段改变了输出范式,MathBook-7B 能够提供更简洁、更精准的推理过程。例如,在 MathVision 测试集上,MathBook-7B 的回答更加简洁,平均响应长度减少,但仍保留了所有必要的知识推理步骤,解决了基线模型「过度思考」的问题。我们认为这种思路可以与构建自我思考、自我反馈的方法结合,旨在让模型在正向推理过程中高效有效地利用知识推理。
MathBookEval 中的实验结果
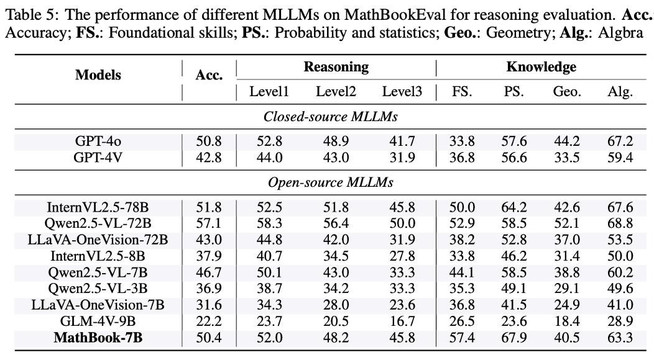
- 知识点数量影响显著:模型准确率与题目知识点数量呈负相关,尤其在涉及 7-10 个知识点时,大多数模型准确率低于 50%,凸显多步推理的挑战性,验证了知识点数量作为难度指标的有效性。
- 代数与几何表现差异明显:模型在代数题上表现较好,准确率普遍超过 50%;但在几何题上表现较差,反映出空间推理能力的不足。
We-Math 系列工作

我们希望通过 We-Math 系列工作,以长期且持续系统性的努力,推动多模态数学推理的发展。其愿景希望让模型像人类一样可以依据知识解决问题,同样也能在未来成为人类的学习助手。
具体而言,We-Math (ACL 2025) 聚焦于模型的评测,2.0 版本更加聚焦于模型的训练,现阶段我们通过手动构建高精度的知识体系与题目验证了这一思路的有效性。
从数据集的角度看,2.0 版本更希望凸显 MathBook-Standard 的高质量与知识覆盖全面性而 MathBook-Pro 则更多的是传达一个有更多可能性的思路,后续我们也会进一步依照知识体系与三维空间探索大规模自动构建的可能性。
此外,2.0 版本我们也会将全部的图像数据与 GGB 源文件开源,我们认为这不仅会对多模态推理有所贡献,也会对 AI for Education 有着一定的贡献,相信在未来,知识学习会是很重要的基石。







