
随着多模态大语言模型(MLLMs)在视觉问答、图像描述等任务中的广泛应用,其推理能力尤其是数学几何问题的解决能力,逐渐成为研究热点。
然而,现有方法大多依赖模板生成图像 - 文本对,泛化能力有限,且视觉与文本信息之间存在严重不对齐问题,制约了模型在复杂几何推理任务上的表现。

来自 UIUC 的作者团队的研究提出了一种基于强化学习与可验证奖励 RLVR 数据生成与优化框架 ——Geo-Image-Textualization,并发布了首个完全对齐的高质量几何图像 - 文本数据集 GeoReasoning-10K,包含 1 万对精心构建的图像与描述。
并且,为了促进社区发展,作者团队已公开 GeoReasoning-10K 数据集及相关代码。

- 数据集地址:https://huggingface.co/datasets/ScaleMath/GeoReasoning
- 代码地址:https://github.com/MachinePhoenix/GeoReasoning
- 论文链接:https://arxiv.org/abs/2509.15217
- 论文标题:Generalizable Geometric Image Caption Synthesis
数据集与方法介绍
该框架的核心创新包括:
- 强泛化性:训练后的模型不仅在几何任务上表现优异,还能泛化至算术、代数、数值推理等非几何任务,甚至处理非几何图像输入。
- 高质量:经过 GeoReasoning 训练过的模型,在下游任务上性能超过其他同类型数据集,并且具有良好的缩放性质。
- 可扩展性:生成的样本由模板集中的字句组合而成,可以组合出任意复杂度的几何题。
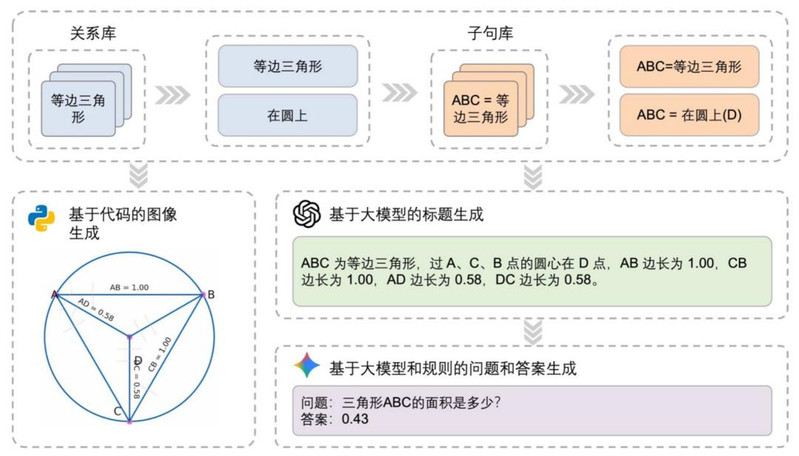
图像 - 标题 - 问题 / 答案的生成流程如下图所示:
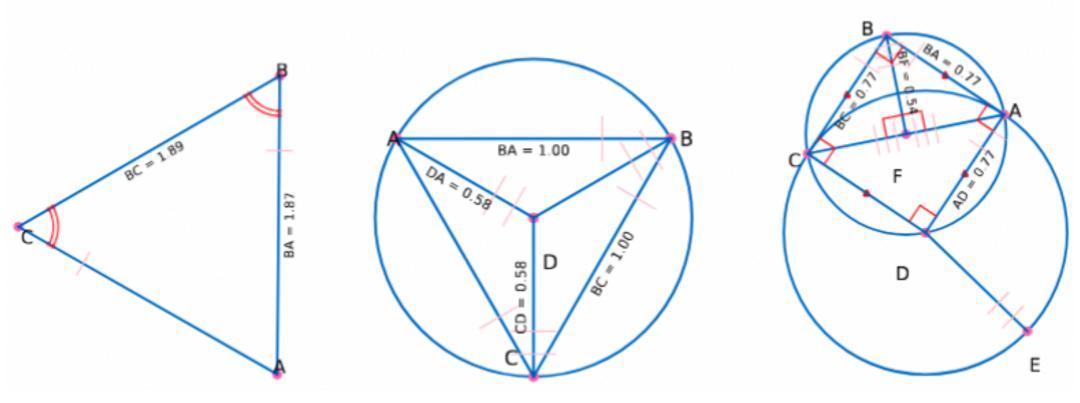
生成的几何图示例如下:
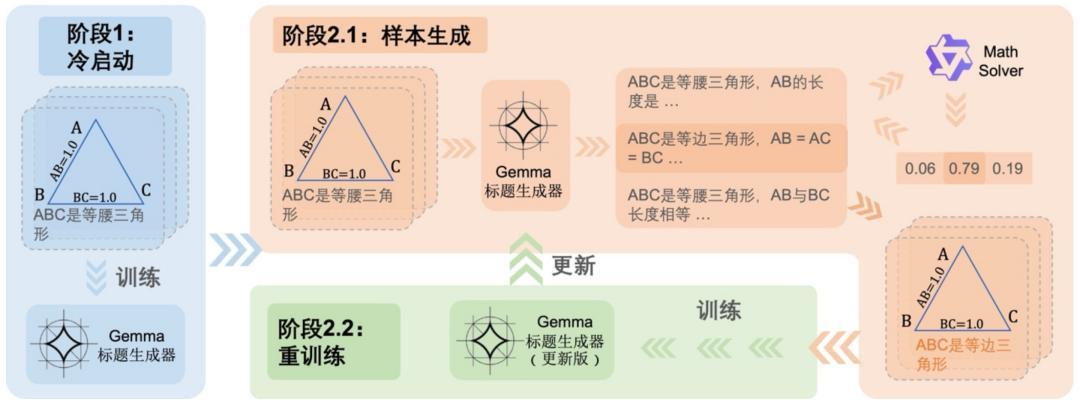
训练流程和强化学习阶段的奖励函数如下:

实验结果
在权威数学推理基准 MathVista 和 MathVers 上与其他几何字幕标注数据集(如 AutoGeo、GeoPeP)和解题数据集(如 GeoGPT4, Geo170K)相比,GeoReasoning-10K 在相同数据量下均取得最优效果,展现出卓越的数据质量与扩展性:
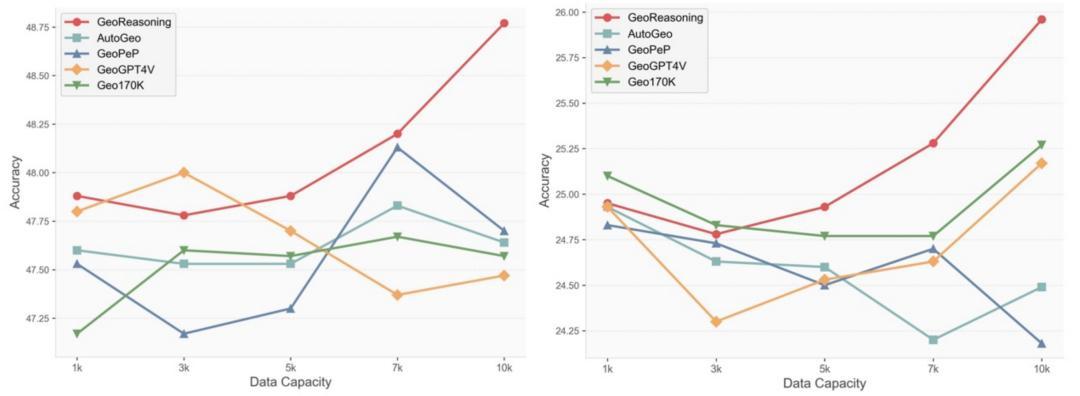
左:MathVista;右:MathVerse
在 MMMU 测评基准上,使用 GeoReasoning-10K 微调后的 Gemma3-4B 模型显著提升多项能力:
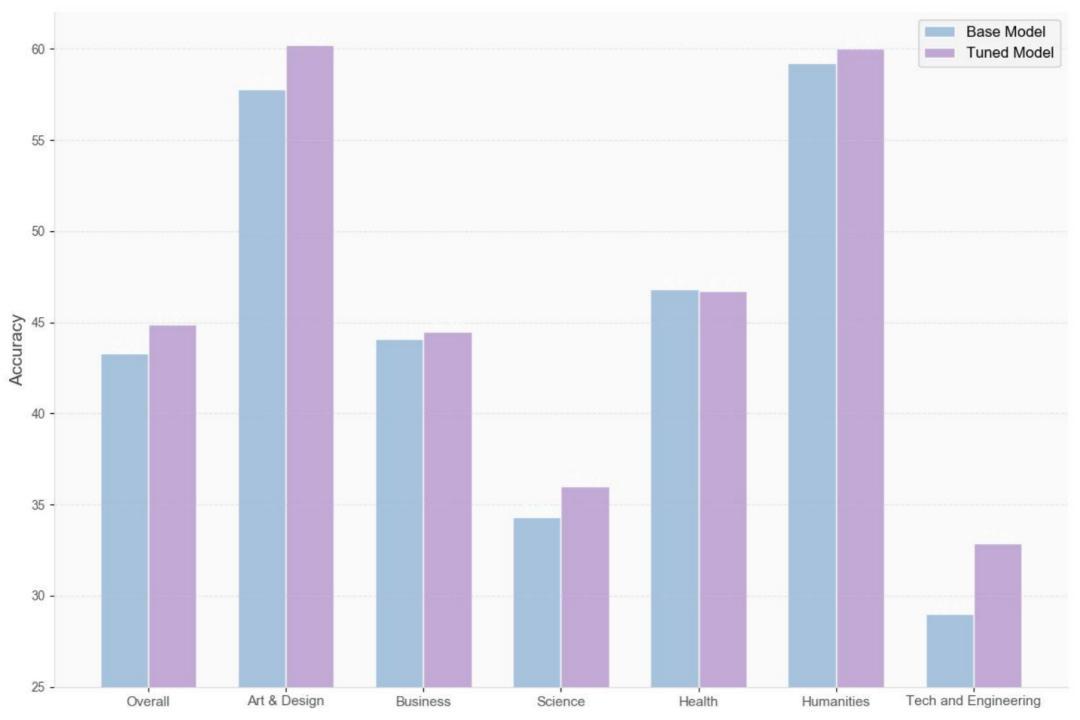
MMMU 实验结果
最后展示 MathVista 中的一些具体样例:



以及 MMMU 的一些样例:


总结
在多模态大语言模型快速发展的今天,Geo-Image-Textualization 框架和 GeoReasoning-10K 数据集为解决几何推理瓶颈提供了全新思路。通过确保视觉和文本信息的完全对齐,本文的方法不仅提升了模型在几何问题上的表现,还实现了向更广泛数学领域的泛化。
正如实验结果所示,给几何图片写标题可以让 AI 变聪明,不仅能解决几何问题,还能增强其整体数学推理能力,为多模态 AI 在教育、科学计算等领域的应用铺平道路。
感谢作者团队的辛勤工作和开源贡献,期待更多研究者加入这一领域,共同推动多模态 AI 技术的边界不断扩展。







