
本文一作为陈骁,香港中文大学 MMLab - 上海人工智能实验室具身智能中心联培博士生,研究方向是三维计算机视觉和具身智能,导师为薛天帆教授。个人主页:xiao-chen.tech/。
研究背景
当人类走入陌生房间时,会通过移动和观察来掌握室内结构。想象机器人被扔进一个陌生场景:有的房间堆满障碍,有的走廊九曲十八弯,它能像人类一样主动探索未知空间吗?
尽管计算机视觉已赋予机器人强大的被动技能,比如按预设拍摄轨迹实现同步定位建图(SLAM),可一旦剥离所有提示,机器人却可能沦为 “路痴”——
“门在哪?”“怎么绕过障碍物?”
“哪片区域还没有探索过?”
“目标最可能出现在哪片区域?”

“主动探索” 这一智能基石,何以成为技术盲区?
经典方案往往依赖人工预设的轨迹、视角与指令,而现有探索策略在陌生复杂场景中频频失效:机器人既可能在废墟救援时因全局规划缺失而卡死墙角,又容易在障碍密集的客厅中反复碰撞进退维谷。当机器人在此类复杂环境下运转时,感知 - 决策 - 行动闭环如何挣脱被动依赖桎梏? 这正是下一代机器人跨越 “智能鸿沟” 的核心挑战。
如何让机器人在完全未知的复杂房间里自主探索?
针对移动机器人在复杂未知环境中 “探索 - 建图” 的泛化难题,香港中文大学与上海人工智能实验室联合提出系统性解决方案:研究者们搭建了全球规模最大的 “探索 - 建图” 基准 GLEAM-Bench—— 该数据集涵盖上千个室内场景,并在此基础上设计了通用可泛化的 “探索 - 建图” 策略GLEAM。该策略使机器人在完全陌生的复杂室内环境中首次实现了高效安全的探索和精准建图,实现零样本适配未知复杂空间,无需微调即达66.5% 平均场景覆盖率。得益于大规模训练架构,GLEAM 较现有技术提升 9.49%。

- 论文标题:GLEAM: Learning Generalizable Exploration Policy for Active Mapping in Complex 3D Indoor Scenes
- 项目主页: https://xiao-chen.tech/gleam
- 代码:https://github.com/zjwzcx/GLEAM
- 论文:https://arxiv.org/abs/2505.20294
方法效果
基线方法往往只能在空旷的单一场景内探索,一旦面对家具等障碍物密集的多房间布局,难以保证跨房间探索的安全性和高效性。
相比之下,GLEAM 在来自三个室内场景数据集的未知场景上展现了优越的泛化能力。更为重要的是,GLEAM 首次体现了无需在新数据集上微调模型的零样本泛化能力 —— 它能够直接适配到全新的真实场景数据集(如 Matterport3D),而之前的方法通常局限于单一数据集或需要针对特定场景进行参数调整。






数据和基准
团队构建了首个涵盖千级(1152个)复杂三维室内场景的训练评测体系:GLEAM-Bench 基准。完整的三维场景数据文件、预处理脚本和仿真相关的 API 均已开源。

GLEAM-Bench 涵盖多种数据来源,包括
- 高质量虚拟场景(ProcTHOR-10K、HSSD)
- 真实扫描数据集(Gibson、Matterport3D)
其中,两个真实扫描数据集验证了 GLEAM 真实世界部署的潜力,ProcTHOR 提供了场景生成方法,可以批量制作丰富多样的场景数据。
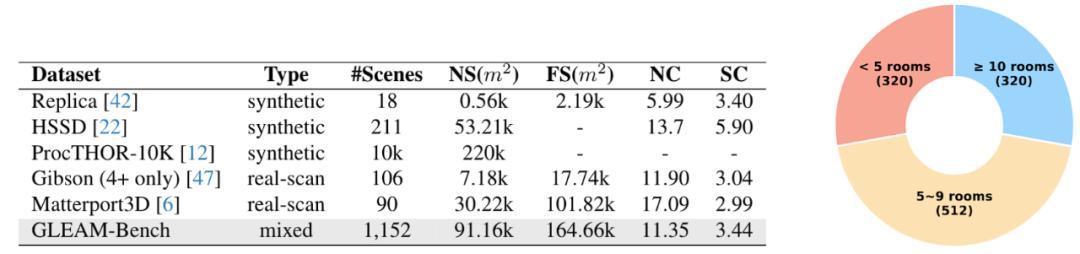
研究者严格筛选并预处理了所有三维场景数据,数据特征包括:
- 拓扑连通性:确保场景中每个房间的可达性;
- 几何水密性:选择几乎 100% 水密的场景,避免无人机穿过窗户等特殊情况;
- 复杂度跃升:导航复杂度达到 11.35,包含高密度障碍与拓扑迷宫等复杂结构。
方法解读
为攻克 “探索 - 建图” 在未知复杂场景的泛化瓶颈与大规模训练的数据效率难题,GLEAM 架构融合三大创新设计:
- 语义认知地图
- 分层动作空间
- 抗过拟合训练策略

1. 语义认知地图:让机器理解 “未知”
为了使机器人在复杂环境中实现高效时空推理,研究者将环境解构为任务导向的语义地图表征,构建了双地图系统:
- 全局概率地图:融合历史观测的贝叶斯占据栅格,动态更新环境认知;
- 局部语义地图:以机器人为中心,在局部栅格概率地图的基础上,进一步引入边界检测模块,通过提取四元语义状态(占据 / 空闲 / 未知 /边界)来强化探索导向。
同时,研究者部署了轻量化 LocoTransformer 提炼语义地图的空间关系,助力实时推理和建图。
2. 分层动作空间:直觉式长程决策配合启发式局部规划器
研究者解耦了全局探索与局部避障:
- 高层决策(“去哪探索”):摒弃传统局部移动指令(如“前进 10cm”),直接预测可达的长程目标;
- 低层规划(“目的地是否安全可达”):由轻量级 A * 模块保障,在实时更新的观测空间内验证目标可达性,避免过于激进或取巧的规划策略。
这个设计极大提升了训练和推理效率, 并且确保了决策安全性与探索效率。
3. 随机化 “抗过拟合” 训练
- 随机初始化机器人位置:强制适应任意初始位姿;
- 动态轮换千级训练场景:训练中实时更换环境,锻造跨域适应能力。
实验结果
实验结果表明,GLEAM 优越的泛化性主要来源于四个要素:
- 大规模多样化空间数据
- 丰富的任务特征
- 分层策略架构
- 随机化抗过拟合训练技巧
从以下表格可以看出,无论在虚拟场景还是真实场景上,GLEAM 在探索覆盖率(Cov.),探索效率(AUC)和建图精度(CD)三类指标上均大幅超越之前的方法。

研究者分析了训练场景的数量、质量和多样性对测试结果的影响。从数量开始, 研究者们均匀地对每种类别的训练场景数量作下采样, 测试结果如下:

符合直觉的是,随着训练场景的数量从 32 按比例上升到 1024,GLEAM 在未知测试场景上的探索覆盖率相关指标呈稳定上升趋势,同时建图精度稳定下降。
更进一步,研究者解耦了训练场景的数量、复杂度和多样性这三个要素:

有趣的是,只使用 192 个多房间 (>10) 训练场景的策略性能竟然高于 416 个少房间 (
研究者在搭载单张 RTX 3090 显卡的电脑上测试推理速度为 104.7Hz,证明了 GLEAM 在现实部署的潜力。

另外,研究者还进行了抗噪声测试和关键技术的消融实验,证明了 GLEAM 的鲁棒性和涉及特征提取、动作空间和训练策略等方面的关键设计的有效性。
更多细节与结果请参阅原论文 (
https://arxiv.org/abs/2505.20294) 与项目主页 (
https://xiao-chen.tech/gleam)。欢迎对该方向感兴趣的读者与作者交流探讨!







