
随着 AI 技术的飞速发展,从「快思考」到 「慢思考」,大语言模型(LLMs)在处理复杂推理任务上展现出惊人的能力。无论是我们熟知的思维链(CoT),还是更复杂的深度思考模式(Thinking),都让 AI 的回答日益精准、可靠。
然而,这种性能的提升并非没有代价。模型在推理过程中会产生大量的中间步骤和文本(tokens),这不仅极大地拖慢了计算速度,还对内存和计算资源造成了巨大的压力。简单来说,就是「想得越多,算得越慢,耗得越多」。
为了解决这一难题,研究者们从人类的认知过程中汲取灵感。想象一下人类在解决一个复杂数学题时的情景:我们通常会在草稿纸上写下关键的计算步骤(如下图 a 中的黄色高亮部分),而将一些辅助性的思考过程(非高亮部分)放在脑中。

图 1:(a) 展示了一个典型的思维链推理过程,黄色部分为关键步骤。(b) 对比了传统方案 Vanilla 与 LightThinker 的推理流程。
本文中,来自浙江大学、蚂蚁集团等机构的研究者提出了 LightThinker,它模仿了这一高效的思考模式。它训练 LLM 在推理过程中动态地将冗长的中间思考步骤压缩成紧凑的表示(gist tokens /cache tokens),然后「扔掉」原始的、繁琐的推理链,仅保留核心摘要以继续下一步的思考。 这样一来,存放在上下文窗口中的 tokens 数量被大幅削减,从而显著降低了内存占用和计算成本。

- 论文标题:LightThinker: Thinking Step-by-Step Compression
- 论文链接: https://arxiv.org/abs/2502.15589
- 代码链接: https://github.com/zjunlp/LightThinker
LightThinker 概览
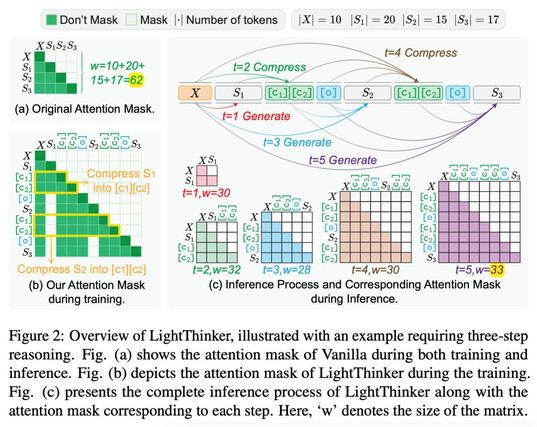
LightThinker 通过训练的方式让模型具备这种能力。这涉及到两个关键问题:「何时压缩?」和「如何压缩?」。整个过程可以概括为以下三个关键步骤:
第一步:数据重构 —— 在思考流程中植入「压缩指令」
LightThinker 的第一步就是改造训练数据,让 LLM 明白「压缩」这个动作的存在和时机 。具体操作是:
- 步骤划分:首先,将模型原本冗长的完整回答 Y,按照语义或段落(即一个完整的「想法」)切分成若干个思维步骤 S1, S2, S3, ...。
- 插入特殊指令符:在这些思维步骤之间,插入一组特殊的「指令令牌」4。这组指令符主要包含两个部分:
- 缓存令牌 (Cache Tokens, C):这是一组特殊的、用于存储压缩后信息的「摘要令牌」。它的作用就像是为即将产生的「思想摘要」预留的空白便签。
- 输出令牌 (Output Token, [o]):这是一个强制性的输出信号,它的作用是告诉模型:「好了,摘要写完了,现在请基于这份摘要继续你下一步的思考」 。
经过这样的改造,原本一条完整的思考链,就变成了一个「思考步骤 1 S1 → 进行压缩 → 继续思考步骤 S2 → 再次压缩 → ...」的全新格式。这等于是在模型的学习材料中明确地标注出了「何时」需要进行压缩。
注意,研究者在具体实现中,采用换行符作为思维步骤的划分,此处不存在任何数据精心构造的过程。
第二步:注意力改造 —— 学会压缩与理解压缩的内容
教会了模型「何时」压缩,下一步就是最关键的如何压缩。这主要通过一种名为 「Thought-based Attention Mask」的技术来实现,如图 2 (b) 所示。精确地控制着模型在思考时 “能看什么” 和 “不能看什么” 。
这个过程分为两个阶段:
- 压缩阶段(生成思维摘要):当模型需要将思维步骤 Si 压缩进缓存令牌 C 时,注意力掩码会强制这些 C 令牌只能「看到」三个东西:
- 最初的问题 X;
- 先前已经压缩好的历史摘要;
- 当前正在处理的思维步骤 Si。
其他所有原始的、未压缩的思维步骤都会被「遮蔽」。这迫使模型必须将 Si 中的所有关键信息高度浓缩并存储到 C 中 。
- 生成阶段(基于摘要生成思维):当思维步骤 Si 被成功压缩进 C 之后,更关键的一步来了。在生成下一个思绪片段 S (i+1) 时,注意力掩码会彻底「遮蔽」掉原始的思维步骤 Si。此时,模型只能「看到」最初的问题 X 和包括刚刚生成的摘要在内的所有历史摘要 。
通过这种方式,模型被迫学会仅依赖紧凑的「思想摘要」来进行连贯的、层层递进的推理,而不是依赖越来越长的原始思考全文。
第三步:动态推理 ——「即用即弃」的高效循环
经过以上两个步骤的训练,LightThinker 模型在实际推理时,就会形成一种高效的动态循环,如图 1 (b) 和图 2 (c) 所示,清晰地展示了「生成→压缩→抛弃」的动态循环过程。下面以图 1 (b) 为例进行分析:
- 模型接收问题,生成第一段思考(Thought 1)。
- 触发压缩,将 Thought 1 中的核心信息压缩成紧凑的摘要(CT1)。
- 抛弃原文,将冗长的 Thought 1 从上下文中丢弃。
- 模型基于问题和摘要(CT1),生成第二段思考(Thought 2)。
- 再次压缩,将 Thought 2 压缩为摘要(CT2),并丢弃 Thought 2 原文。
- 如此循环,直到问题解决。
通过这种「即用即弃」的机制,LightThinker 确保了模型的上下文窗口始终保持在一个非常小的尺寸,从而解决了因上下文过长导致的内存爆炸和计算缓慢问题,实现了效率与性能的完美平衡。
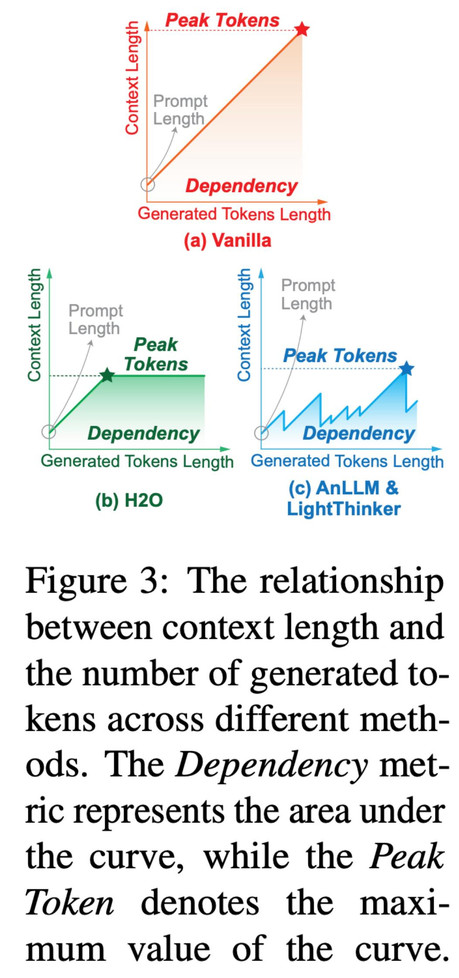
图 3 展示了不同方法在推理过程中上下文长度的变化,其中曲线和坐标轴围城的面积为我们定义的新指标 Dependency,其意义生成 token 时需要关注 token 的数量总和。
实验结果
研究者在四个数据集和两个不同的模型上对 LightThinker 进行了广泛的测试,结果如表 1 所示。
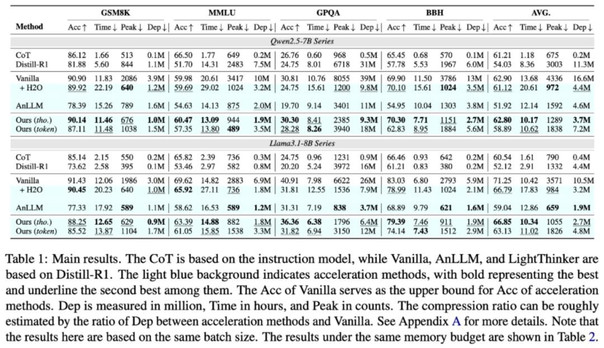
表 1 主要实验结果。Acc 为准确率,Time 为平均推理耗时,Peak 为平均峰值 token 占用数量,Dep 为生成 token 时需要关注 token 的数量总和(如图 3)所示。
结果表明,在 Qwen 系列模型上,与传统模型(Vanilla)相比:
- 峰值内存使用减少 70%:LightThinker 极大地节约了宝贵的内存资源。
- 推理时间缩短 26%:在保证结果准确性的前提下,思考速度得到了显著提升。
- 取得了准确度和效率的平衡。
此外,在 Llama 上,也取得了准确度和效率的平衡。
相关工作
当前关于加速大语言模型(LLMs)推理过程的研究主要集中在四类方法:模型量化、辅助解码、生成更少的 Token 和减少 KV 缓存。模型量化包括参数量化 [1-2] 和 KV 缓存量化 [3-4],辅助解码主要包括投机采样,本节将重点关注后两类方法。
需要注意的是,生成长文本和理解长文本代表着不同的应用场景,因此,专门针对长文本生成阶段的加速方法(例如,预填充阶段加速技术如 AutoCompressor [5]、ICAE [6]、LLMLingua [7]、Activation Beacon [8]、SnapKV [9] 和 PyramidKV [10])不在此处讨论。以下是后两类方法的详细概述。
生成更少的 Token
这一类别可以根据推理过程中使用的 token 数量和类型进一步分为三种策略:
- 离散 Token 减少通过提示工程 Prompt [11-13]、指令微调 [14-15] 或强化学习 [16-17] 等技术来引导 LLM 在推理过程中使用更少的离散 token。例如,TALE [11] 提示 LLM 在预定义的 token 预算内完成任务。Arora 和 Zanette [16] 构建特定数据集并采用强化学习奖励机制来鼓励模型生成简洁准确的输出,从而减少 token 使用量。
- 连续 Token 替换这些方法 [18-19] 探索使用连续空间 token 代替传统的离散词汇 token。一个代表性例子是 CoConut [18],它利用课程学习来训练 LLM 使用连续 token 进行推理。
- 无 Token 使用通过在模型层之间内化推理过程,在推理过程中直接生成最终答案而不需要中间 token [20-21]。
这三种策略都是在模型训练后实施的,推理过程中不需要额外干预。从技术上讲,这些方法的加速效果依次递增,但代价是 LLM 的泛化性能逐渐下降。此外,第一种策略并不能显著减少 GPU 内存使用。
减少 KV 缓存
这一类别可以分为两种策略类型:基于剪枝的离散空间 KV 缓存选择和基于合并的连续空间 KV 缓存压缩。
- 基于剪枝的策略设计特定的淘汰策略 [22-25] 在推理过程中保留重要的 token。例如,StreamingLLM [23] 认为初始的 sink token 和最近的 token 是重要的;H2O [22] 关注具有高历史注意力分数的 token;SepLLM [24] 强调对应于标点符号的 token 是重要的。
- 基于合并的策略引入锚点 token,训练 LLM 将历史重要信息压缩到这些 token 中,从而实现 KV 缓存合并 [26]。
这两种策略都需要在推理过程中进行干预。关键区别在于:第一种策略是无需训练的,但对每个生成的 token 都要应用淘汰策略;而第二种策略是基于训练的方法,允许 LLM 自主决定何时应用淘汰策略。
局限性
受限于自身的数据重构方案(目前分割思维步骤是依赖规则,而不是基于语义)和训练数据(约 16K 训练数据),本文方法在数学相关的任务上表现并不出色。
如下图所示,展示了 LightThinker 在 GSM8K 上的一个 Bad Case。研究者观察到,尽管 LLM 在思考过程中得出了正确答案(见上图中的 Model"s Thoughts 字段),但在最终输出中却出现了错误(见图中的 Model"s Solution 字段)。
具体来说,在 Model"s Solution 字段的第三句话中,第一次出现的「4000」是错误的。这表明在第二次压缩步骤中发生了信息丢失(理论上,「8000」、「4000」和「24000」都应该被压缩,但 LLM 只压缩了「4000」和「24000」),导致后续的推理错误。这类错误在 GSM8K 数据集中频繁出现,表明当前的压缩方法对数值的敏感度还不够。

参考文献
[1] Lin J, Tang J, Tang H, et al. AWQ: Activation-aware weight quantization for on-device LLM compression and acceleration. MLSys 2024.
[2] Dettmers T, Lewis M, Belkada Y, et al. GPT3.INT8 (): 8-bit matrix multiplication for transformers at scale. NeurIPS 2022.
[3] Liu Z, Yuan J, Jin H, et al. KIVI: A tuning-free asymmetric 2bit quantization for KV cache. ICML 2024b.
[4] Hooper C, Kim S, Mohammadzadeh H, et al. KVQuant: Towards 10 million context length LLM inference with KV cache quantization. NeurIPS 2024.
[5] Chevalier A, Wettig A, Ajith A, et al. Adapting language models to compress contexts. EMNLP 2023.
[6] Ge T, Hu J, Wang L, et al. In-context autoencoder for context compression in a large language model. ICLR 2024.
[7] Jiang H, Wu Q, Lin C, et al. LLMLingua: Compressing prompts for accelerated inference of large language models. EMNLP 2023.
[8] Zhang P, Liu Z, Xiao S, et al. Long context compression with activation beacon. arXiv:2401.03462, 2024b.
[9] Li Y, Huang Y, Yang B, et al. SnapKV: LLM knows what you are looking for before generation. NeurIPS 2024.
[10] Cai Z, Zhang Y, Gao B, et al. PyramidKV: Dynamic KV cache compression based on pyramidal information funneling. CoRR abs/2406.02069, 2024.
[11] Han T, Wang Z, Fang C, et al. Token-budget-aware LLM reasoning. CoRR abs/2412.18547, 2024.
[12] Ding M, Liu Z, Fu Z, et al. Break the chain: Large language models can be shortcut reasoners. CoRR abs/2406.06580, 2024.
[13] Nayab S, Rossolini G, Buttazzo G, et al. Concise thoughts: Impact of output length on LLM reasoning and cost. CoRR abs/2407.19825, 2024.
[14] Liu T, Guo Q, Hu X, et al. Can language models learn to skip steps? NeurIPS 2024a.
[15] Kang Y, Sun X, Chen L, et al. C3oT: Generating shorter chain-of-thought without compromising effectiveness. CoRR abs/2412.11664, 2024.
[16] Arora D, Zanette A. Training language models to reason efficiently. arXiv:2502.04463, 2025.
[17] Luo H, Shen L, He H, et al. O1-pruner: Length-harmonizing fine-tuning for o1-like reasoning pruning. arXiv:2501.12570, 2025.
[18] Hao S, Sukhbaatar S, Su D, et al. Training large language models to reason in a continuous latent space. CoRR abs/2412.06769, 2024.
[19] Cheng J, Van Durme B. Compressed chain of thought: Efficient reasoning through dense representations. CoRR abs/2412.13171, 2024.
[20] Deng Y, Choi Y, Shieber S. From explicit CoT to implicit CoT: Learning to internalize CoT step by step. CoRR abs/2405.14838, 2024.
[21] Deng Y, Prasad K, Fernandez R, et al. Implicit chain of thought reasoning via knowledge distillation. CoRR abs/2311.01460, 2023.
[22] Zhang Z, Sheng Y, Zhou T, et al. H2O: Heavy-hitter oracle for efficient generative inference of large language models. NeurIPS 2023.
[23] Xiao G, Tian Y, Chen B, et al. Efficient streaming language models with attention sinks. ICLR 2024.
[24] Chen G, Shi H, Li J, et al. SepLLM: Accelerate large language models by compressing one segment into one separator. CoRR abs/2412.12094, 2024.
[25] Wu J, Wang Z, Zhang L, et al. SCOPE: Optimizing key-value cache compression in long-context generation. CoRR abs/2412.13649, 2024a.
[26] Pang J, Ye F, Wong D, et al. Anchor-based large language models. ACL 2024







