
智东西
作者 | 王涵
编辑 | 漠影
智东西9月24日报道,今天上午在2025云栖大会开幕式上,阿里巴巴一口气发布了7个模型更新,阿里通义系列模型已累计发布了300多款!
本次大会上发布的新模型包括:
1、Qwen3-MAX:万亿参数大模型,编程与工具调用能力登顶国际榜单;
2、Qwen3-Omni:原生全模态大模型,支持19种语言及方言输入、10种语言输出,可处理长达30分钟的会议录音或播客并精准输出纪要;
3、Qwen3-VL:视频理解模型,Agent和Coding能力全面提升;
4、Qwen-Image:开源图片编辑模型,新版本支持多图参考编辑,原生集成ControlNet;
5、Qwen3-Coder:智能编程模型,支持256K上下文,TerminalBench分数大幅提升;
6、Wan2.5-Preview:视频生成模型,可以生成10秒长视频,时长提升1倍,最高支持1080P 24fps画质;
7、通义百聆:企业级语音基座大模型,幻觉率骤减67.8%。
阿里巴巴集团CEO、阿里云智能集团董事长兼CEO吴泳铭首次系统阐述了通往超级人工智能(ASI)的三阶段演进路线,他认为实现通用人工智能(AGI)已是确定性事件,但AGI并非AI发展的终点,而是全新的起点。AI发展的终极目标是发展出能自我迭代、全面超越人类的ASI。
此外,阿里云智能集团首席技术官、通义实验室负责人周靖人还介绍了阿里云百炼平台在Agent智能体开发与AI基础设施上的功能改进和升级。
一、吴泳铭:AGI并非AI发展的终点,而是全新的起点
在发布AI全家桶更新之前,吴泳铭率先登台分享了他本人以及阿里对于AGI、ASI的洞察与思考,还透露了阿里对于AI发展的愿景和实现路径。
他首先系统阐述了通往ASI的三阶段演进路线:
第一阶段:“智能涌现”,特征是“学习人”,指的是AI通过学习海量人类知识具备泛化智能。
第二阶段:“自主行动”,特征是“辅助人”,即AI掌握工具使用和编程能力以“辅助人”,这是行业当前所处的阶段。
吴泳铭认为,实现这一跨越的关键,首先是大模型具备了Tool Use能力,有能力连接所有数字化工具,完成真实世界任务。其次,大模型Coding能力的提升,可以帮助人类解决更复杂的问题,并将更多场景数字化。
“发展大模型Coding能力是通往AGI的必经之路。”吴泳铭强调,“未来,自然语言就是AI时代的源代码,任何人用自然语言就能创造自己的Agent。”
第三阶段:“自我迭代”,AI通过连接物理世界并实现自学习,最终实现“超越人”。
吴泳铭谈道,这个阶段有两个关键要素:
第一、AI连接了真实世界的全量原始数据。他认为,只有让AI与真实世界持续互动,获取更全面、更真实、更实时的数据,AI才能更好的理解和模拟世界,发现超越人类认知的深层规律,从而创造出比人更强大的智能能力。
第二点就是Self-learning自主学习。随着能力的持续提升,未来的模型将通过与真实世界的持续交互,获取新的数据并接收实时反馈,借助强化学习与持续学习机制,自主优化、修正偏差、实现自我迭代与智能升级。

吴泳铭还分享了阿里对于当今AI影响的思考:
首先,阿里认为大模型将是下一代的操作系统。LLM将会是承载用户、软件与AI计算资源交互调度的中间层,成为AI时代的OS。
大模型作为下一代的操作系统,将允许任何人用自然语言,创造无限多的应用。未来几乎所有与计算世界打交道的软件可能都是由大模型产生的Agent,而不是现在的商业软件。
其次,超级AI云是下一代的计算机。从CPU为核心的传统计算,正在加速转变为以GPU为核心的AI计算。新的AI计算范式需要更稠密的算力、更高效的网络、更大的集群规模。
这一切都需要充足的能源、全栈的技术、数百万计的GPU和CPU,这就需要超大规模的基础设施和全栈的技术积累,只有超级AI云才能够承载这样的海量需求。未来,全世界可能只会有5-6个超级云计算平台。
为实现这一畅想,阿里云作为“全栈人工智能服务商”,将通过两大核心路径实施AI战略:
第一,通义千问坚定开源开放路线,致力于打造“AI时代的Android”。通义千问已经开源了300多款模型,覆盖了全模态、全尺寸。截至目前,通义千问全球下载量超6亿次,衍生模型超17万个,是全球第一的开源模型矩阵。
其二,阿里还将构建作为“下一代计算机”的超级AI云,为全球提供智能算力网络。
为支撑这一宏大愿景,吴泳铭分享了一组数据,阿里巴巴正在积极推进三年3800亿的AI基础设施建设计划,并将会持续追加更大的投入。根据远期规划,为了迎接ASI时代的到来,对比2022年这个GenAI的元年,2032年阿里云全球数据中心的能耗规模将提升10倍。
在演讲的最后,吴泳铭强调,一切才刚刚开始。他认为,AI将重构整个基础设施、软件和应用体系,成为真实世界的核心驱动力,掀起新一轮智能化革命。

二、超级“6+1”,通义系列模型一揽子全面升级
随后,阿里云智能集团首席技术官、通义实验室负责人周靖人带来了阿里通义系列的全栈更新发布。整个发布分为三个部分:大模型、Agent开发范式和AI基础设施。
首先在大模型方面,也是本次大会开幕式最重磅的环节,周靖人一口气发布了7款新模型,分别是Qwen3-MAX、Qwen3-Omni、Qwen3-VL、Qwen-Image、Qwen3-Coder、Wan2.5-Preview和首次亮相的通义百聆,具体升级如下:
1、Qwen3-Max
周靖人Qwen3-Max为通义千问家族中最大、最强的基础模型。该模型预训练数据量达36T tokens,总参数超过万亿,主推Coding编程能力和Agent工具调用能力。
该模型包含Instruct和Thinking两个版本,Instruct适用于代码生成、工具调用等即时交互任务;Thinking 支持结合工具的深度推理与多步任务拆解,适用于复杂逻辑推演、科研解题等高阶场景。
在大模型用Coding解决真实世界问题的SWE-Bench Verified测试中,Instruct版本斩获69.6分,位列全球第一梯队;在聚焦Agent工具调用能力的Tau2-Bench测试中,Qwen3-Max取得74.8分,超过Claude Opus4和DeepSeek-V3.1。理科推理能力方面,AIME25评测正确率达98%。
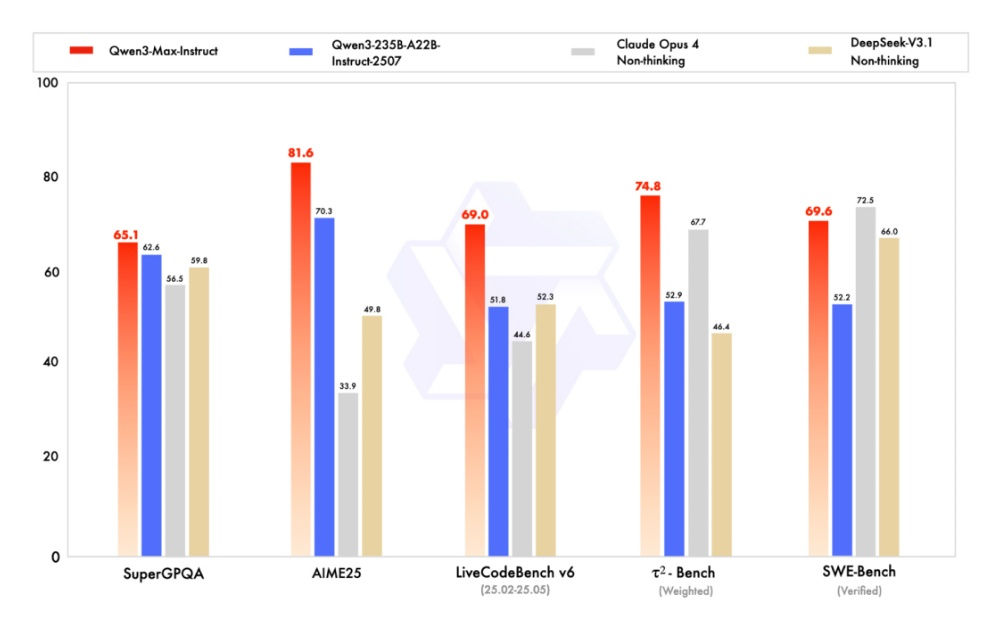
Thinking版本在AIME25评测中得分81.6,显著高于Qwen3-235B-A22B的70.3分,HMMT评测中预估冲击95分,在SuperGPQA、LiveCodeBench、τ²-Bench等任务上也均优于Qwen3-235B-A22B。

2、Qwen3-Omni
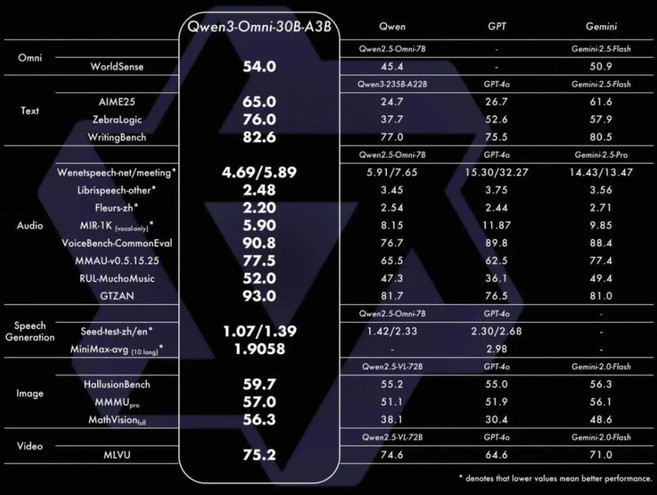
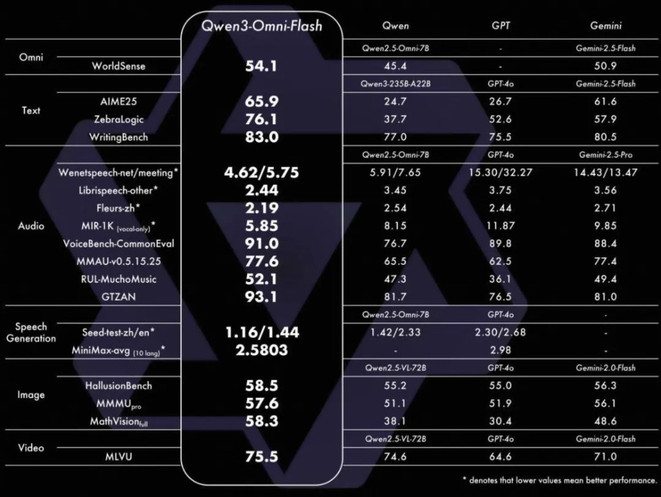
Qwen3-Omni是新一代全模态大模型,支持19种语言及方言输入、10种语言输出,可处理长达30分钟的会议录音或播客并精准输出纪要。
该模型采用Thinker-Talker MoE架构,在支持音视频、图像等多模态能力的同时,文本智力不打折,原生支持Function Call与MCP协议,可无缝嵌入车机、智能音箱等语音助手系统。Qwen3-Omni闭源版提供17种拟人音色,每种音色支持10语种自然表达。
该版本的模型在音频识别、语音生成、图像理解等任务上全面超越Qwen2.5-Omni与GPT-4o,VoiceBench-CommonEval得分达90.8,在AIME25、ZebraLogic等文本推理任务上得分更高,语音生成(MiniMax-avg)达2.5803,VoiceBench-CommonEval得分91.0,在开闭源评测中22项达SOTA水平,多项指标领先开源模型。
3、Qwen3-VL
Qwen3-VL是最新的视觉理解模型,可以实现“看懂、理解并响应世界”。该模型支持2小时视频精确定位,OCR语言从19种扩展至32种,生僻字、古籍、倾斜文本识别率显著提升,原生支持256K上下文,可扩展至100万token。
本次发布重点强化了视觉智能体、可视化编程、空间感知与3D Grounding、超长视频理解与行为分析、Thinking版本STEM推理、视觉感知、多语言OCR与复杂场景支持、安防感知与风险预警、长上下文原生支持等能力,其中视觉智能体在OS World等评测中达世界顶尖水平,Thinking版本在MathVista、MathVision、CharXiv等评测中达SOTA水平。
4、Qwen-Image
Qwen-Image是全新升级的开源图片编辑模型,新版本支持多图参考编辑,强化人脸、商品、文字ID一致性,原生集成ControlNet,实现工业级稳定性。
多图编辑支持人物、商品和场景的多重组合排列;单图编辑在人物ID保持(支持各种风格肖像、姿势变换)、商品ID保持(支持各种商品海报编辑)、文字编辑(支持文字内容、字体、色彩、材质修改)等方面一致性显著增强。

5、Qwen3-Coder
Qwen3-Coder是智能编程模型,支持多模态输入,搭配Qwen Code系统,可上传截图+自然语言指令生成代码。
周靖人透露称,新版本通过Agentic Coding联合训练优化,在SWE-Bench Verified上得分达70.3,TerminalBench与SecCodeBench也显著上涨。Qwen3-Coder在OpenRouter平台一度成为全球第二流行的Coder模型(仅次于Claude Sonnet 4)。
Qwen3-Coder支持256K上下文,可一次性理解并修复整个项目级代码库,推理速度更快、Token消耗更少、安全性更高。

6、Wan2.5-Preview
Wan2.5-Preview首次原生支持音画同步,全面提升视频生成、图像生成、图像编辑三大核心能力。
在视频生成方面,该模型支持原生音画同步,可以生成10秒长视频,时长提升1倍,最高支持1080P 24fps画质。其次,该模型还在复杂指令遵循、图生视频保ID优化、通用音频驱动等方面对应升级。
在图像生成方面,Wan2.5-Preview在美学质感、稳定文字生成(支持多种文字类型精准渲染)、图表直接生成(可输出多种结构化图文)、指令遵循等方面全面升级;
此外,该模型在图像编辑能力上,还支持丰富指令编辑任务,可以保持视觉元素ID一致性。
7、通义百聆
除了以上既有模型的升级以外,周靖人还带来了全新发布的企业级语音基座大模型“通义百聆”。
通义百聆整合了Fun-ASR 语音识别大模型与Fun-CosyVoice语音合成大模型,致力于攻克复杂环境下的语音落地应用难题。
Fun-ASR通过首创的Context增强架构“CTC+LLM+RAG”,将幻觉率从78.5%降至10.7%,支持热词动态注入与跨语种语音克隆,实现了行业术语100%准确召回。
Fun-CosyVoice采用创新性的语音解耦训练方法,大幅提升音频合成效果,支持跨语种语音克隆。该模型还具备强定制化能力,引入RAG机制动态注入术语库,5分钟就可完成配置。
现阶段,此次发布的所有模型已同步上线。用户可进入魔搭、GitHub、Hugging Face一键部署,也可登陆阿里云百炼平台调用API。
周靖人还分享称,阿里的开发者社区魔搭社区,已经有超过1800万的用户数,有超过10万个模型。
三、支持低代码构建流程,还提供全新开发框架,阿里云百炼Agent平台全面更新
Agent开发部分,周靖人称当下Agent智能体需要更加清楚地理解业务需求,能够调用工具帮助开发者充分发挥魔性能力,解决实际场景问题。
他提出,智能体开发还有诸多难题需要解决,首先就是从预定义流程编排到自动化分解需求的演变。
另一方面,阿里认为当下智能体开发,记忆是十分重要的能力。记忆能力可以让Agent贯通上下文,与模型不断提升的上下文能力有机结合。阿里会为用户定制不一样的记忆内容,做到实时动态更新记忆,这也为Agent个性化奠定了基础。
在记忆方面,还要做到智能化记忆分层,例如具体的历史记录以及抽象化形成经验的归纳和总结。并且,记忆还要做到多模态。
第三方面,阿里还希望可以在智能体上面做到信息增强,链接更加多元的信息,拓展模型的能力边界。
特别是本地知识,阿里希望可以让模型更加快速地学习本地、实时的知识,做到准确、可靠、实时和专业。
最后,周靖人认为智能体要从过去的对话聊天形式升级为自主行动模式。要完成这一转变,模型需要强大的工具调用平台,需要提供一个完整的沙箱的环境和一系列计算运行所需要的工具,这一系列都与云能力紧密相关。
为此阿里也推出了阿里云百炼Agent产品,可以从规划决策、信息管理以及工具调用各个方面,全面支持AI时代的智能体的开发。

百炼Agent提供多种开发方式,一种开发方式是通过低代码的方式,开发者可以通过拖拽的方式去构建静态或动态流程,能够快速上手搭建一个智能体。
另外,该产品基于Agentscope的Agent开发框架(ADK),该框架提升了Agent调用云资源效率以及Agent应用开发效率,并且支持不同类型的Agent,具备可扩展性。周靖人透露,今天,Agentscope已经成为了国内开源社区最活跃的智能体开发的框架之一。
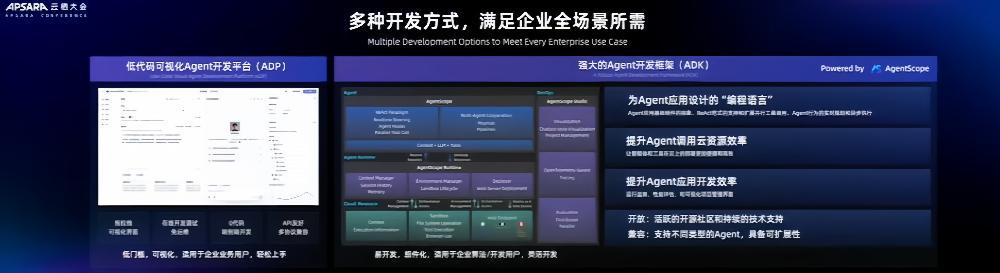
在工具调用方面,百炼Agent支持MCP协议,能够原生提供多种工具服务、沙箱服务以及相关的计算服务等等,开发者可以开箱即用、快速调用。
另外该产品也可以让企业私有化的API一键式转化成MCP服务,由百炼Agent进行托管,让企业的智能体在专有域上调用内部工具,与模型能力有机结合。
同时,百炼Agent也可以在Agent和环境的交互服务、Agent数据和评测服务、Agent训练服务以及模型部署服务上全链路支持Agent的持续调优和进化。
周靖人分享称,到今天,阿里云的百炼模型服务已经完成了全球部署,部分模型的生成速度能够达到100TPS。在过去的12个月里面,百炼模型服务的调用量增加了15倍。

四、AI基础设施面临三大挑战,阿里带来从服务器到算力的全栈优化
周靖人认为,Agent发展给AI基础设施提出了更高的要求:更强大的算力、模型全生命周期优化以及AI原生的应用的开发。
在服务器方面,阿里推出磐久AI Infra2.0 128超节点服务器。该服务器单柜最高功率以及液冷散热可以达到350千瓦,系统供电可用性高达99.9999%。该服务器兼容开放架构,能够兼容产业中各类主流芯片以及ALS AI原生Scale up协议。

为了将服务器连接起来,阿里还推出高性能网络HPN8.0,真正做到训推一体。通过自研硬件的升级,阿里通过网络连接,实现从万卡规模到可以支持几十万卡规模数据中心建设的升级。同时,阿里还优化了通信的协议以及通信库。HPN8.0网络支持跨数据中心连接,实现资源调度。

分布式的存储方面,阿里面向Al Infra方面推出CPFS,单客户端可以达到每秒40GB存储量,相比传统的方案提升了60%。面向Agent开发,阿里还推出OSS,原生支持向量数据,可以实现存检一体,节省95%的成本。

在算力方面,阿里推出了智能计算灵骏集群,支持业界主流GPU,支持多种异构芯片,故障发现率超过了98%。此外,容器计算与函数计算方面,阿里提供的容器计算能够在每分钟拉起15,000个沙箱,做到低延时快速启动。

面向智能体的开发,阿里做到AI应用全栈可观测,也就是提供各种各样的监测工具,帮助开发者跟踪当前系统运行的状态,做到故障检测以及故障分析。阿里已经构建起了连接全球的智能算力网络,可以为AI应用提供全球访问加速。

在模型优化服务方面,阿里推出的人工智能平台PAI,可以贯穿大模型训练、推理与强化学习的全链路性能优化。在数据平台以及数据库方面,阿里推出面向AgenticAl时代的多模态智能数据底座,可以实现多模态数据处理。

最后,在安全方面,阿里向模型和Agent开发提供强大的AI安全护栏,用AI来保护AI安全,实现数据安全、内容安全、实人认证和智能安全运营。

结语:阿里云AI布局蓝图逐渐明晰
总而言之,本次云栖大会开幕式清晰地勾勒出阿里巴巴在人工智能领域的雄心与实力,也展示了阿里在下一阶段AI发展中的技术布局与产业思考。
从通义千问系列模型到Agent开发框架以及AI基础设施,阿里展现了一个从顶层设计到技术落地的完整AI生态体系。阿里此番布局,或许有意抢占下一代AI操作系统和算力平台的核心生态位。







