
小朋友都能懂的人工智能⓵
小朋友都能懂的人工智能⓶ -卷积神经网络初探
小朋友都能懂的人工智能⓷ -惊世骇俗的狗故事
小朋友都能懂的人工智能⓸ -狗大师的修仙之路
「 15 神奇参数替代了海量数据」
L:上回我们说到了大语言模型Chat
GP
T,提到它能“
创造”李白的《静夜思》而非
背诵,大家有些难以置信了,是吧。
A爸:是的,我现在依然认为您在开玩笑,我认为 《静夜思》肯定是存在于Chat GP T内部的数据中,或者就是它上网搜的。
B爸:会不会这样,当你和它随意聊天对话时,它的回复是一种创造。当你问及史料诗歌这类记载时,他就搜资料来回答你。
L:B爸说的似乎有理,有中庸之道的感觉。
众笑。
L:事实上不只是《静夜思》,任何知识类的问题它都能对答如流,如果数据都存在其内部,那Chat GP T存储的内容得覆盖绝大部分的网页文本、书籍、维基百科、科学论文、社交媒体、专业文献、新闻、报告....才能做得到。问题来了, 这可是要存储海量数据啊。
A爸:我明白了!如果大模型在企业是本地部署,按照之前我们的认知,就意味本地要有这些海量数据, 那 存储成本必然惊人。 大模型也就难以在企业落地了。

众人 非常期待! L老师当即调出ChatGPT4进行问答,很快结果出来了,如下。


换句话说,让Chat GP T写出《静夜思》,不是因为它读取原诗的内容,而是它在 通过基于各种参数的计算分析统计后顿悟了, 于是刷刷刷,写出来了。
「 16 语言与神经网络一样是分层的」

「 17 向量化是理解语言的第一步」
L:Chat GPT是如何做到看见一句话,就能准确理解其意思呢?这里至少需要两步,第一步叫 向量化,第二步叫 信息压缩与特征提取,我们先来看向量化。
B: 什么是向量化?
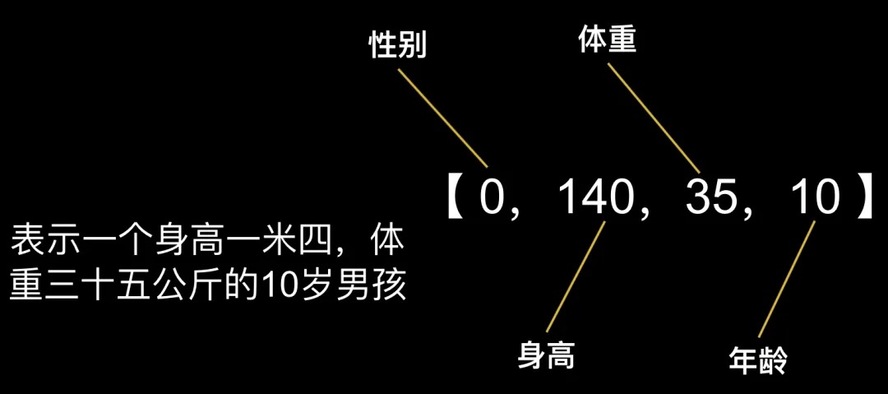
L:简答来说,就是要把你要表示的东西变成一组数字的组合。比如我们要表示一个人,可以用这样一组数字:【0,140,35,10】来表达。
B:这啥意思啊。
L:假设第一个数字表示 性别, 0是男,1是女 , 第二个数字表示 身高, 第三个数字表示 体重, 第四个数字表示 年龄。小B你知道是啥意思了吗?
B:表示一个身高一米四,体重三十五公斤的10岁男孩,咦,这不就是我吗?
L:哈哈,如果你觉得可能还不一定是你。我们可以增加更多的维度,比如【性别,身高,体重,年龄,胸围,腰围,臀围,体脂率,血压,视力,爱好,特长,年级,学校,城市....
】而这些
都可以表示成
数字,
维度越多,对一个人的
定义就越准确。
A爸:那为什么要向量化呢?
L:一方面是向量化能表示成数字,方便电脑处理,更重要的是,向量化以后的空间结构,能很好的展示出规律。我们仅以身高和体重两个维度形成坐标系来举例说明。 如下图所示,所有与【140,35】坐标接近的位置,就是体型和小B相似的人。 比如身高1米42,体重36公斤的小A就距离小B很近。而身高185,体重80公斤的A爸,则距离小B很远。
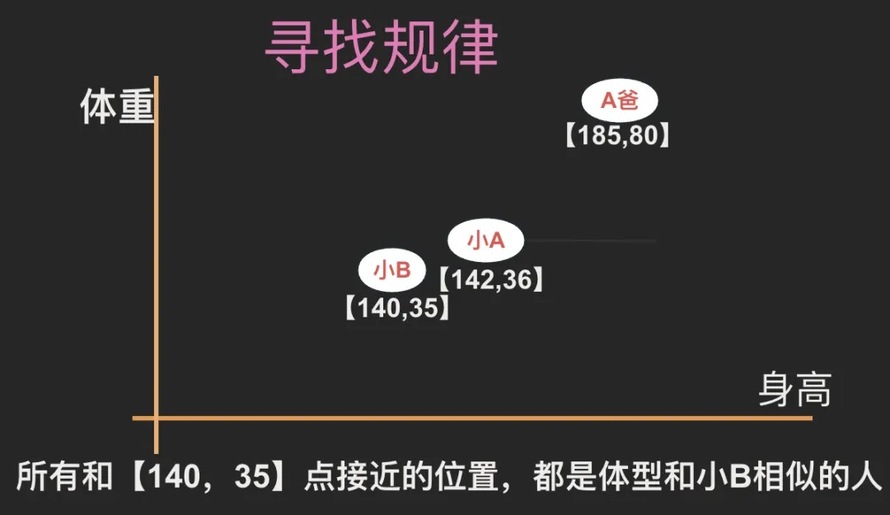
我们可以增加更多的维度,比如增加年龄,就变成三维坐标系,再增加性别,就变成四维坐标系... 衡量的标准就越多,维度越多。 在多维坐标系里,我们就能更多的通过 空间关系理解每一个人的特征。大家能听明白吗?
如此通俗易懂,众人纷纷点头。
L:接下来引出关键之处了,大家想想,其实词语也是一样的。如果我们把词语放在一个高纬坐标里, 意义相近的词语,空间就会更近。
比如“美”和“好”。从词性维度上,它们都是 形容词。从贬义褒义上它们都是 褒义,从使用场景上,它们 经常一起出现....还有各种我们猜不出来的维度,所有这一切维度让它们在一个高维坐标里,出在了比较近的距离。
A爸:有意思,原来是这样啊。
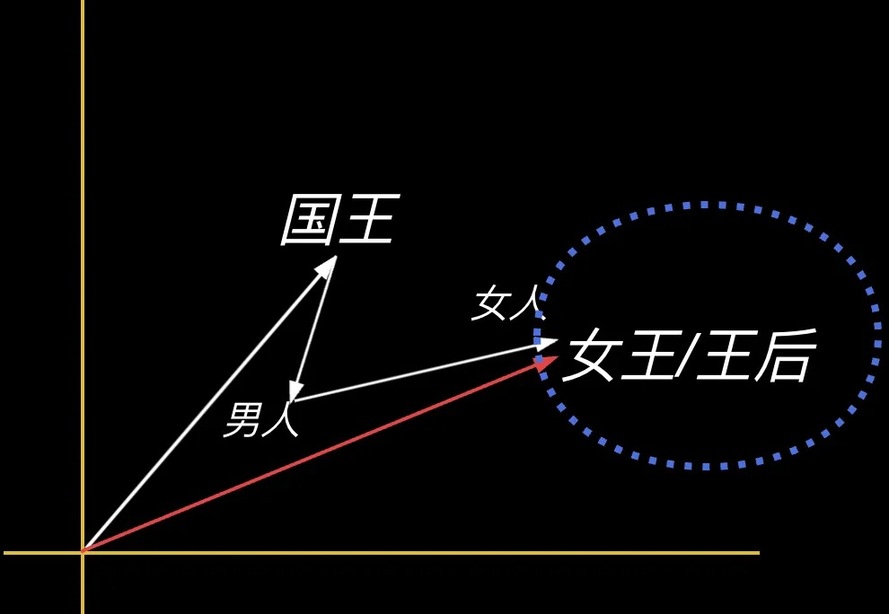
L:还有更有意思的,因为 向量是可计算的,可相加相减相乘,当我们把词语放到向量空间后,我们发现神奇的事发生了,“国王”这个词减去“男人”再加上“女人”,得出的向量居然和“女王”或者“王后”的位置非常接近,这说明在一个合适维度的坐标中, 词语之间的空间关系反映了它们现实世界的实际关系。
「 18 如何完成向量化工作」
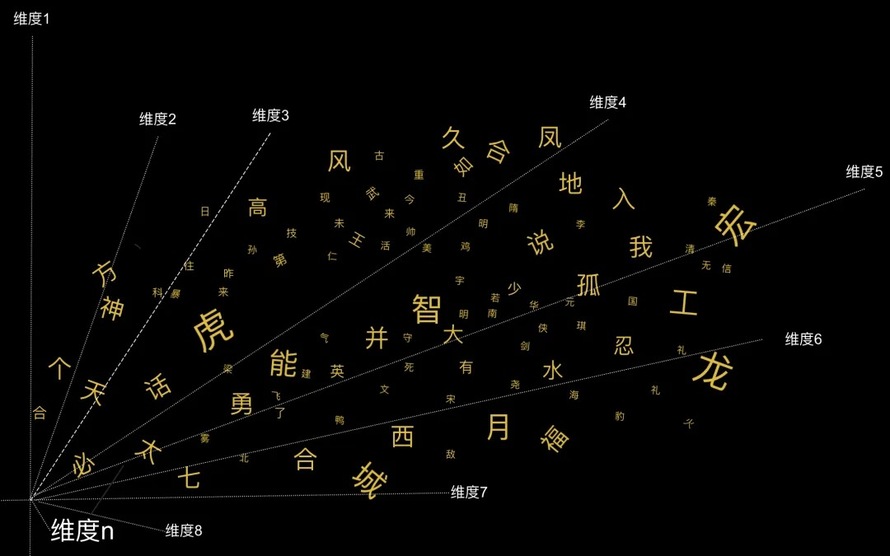
L:前面说了,我们需要把词语放到一个合适维度的坐标中,还要能正确的标注出每个词语在这个空间中的位置,神奇的事才能发生。但是怎么才能找到这些维度,怎么找到词语的空间位置呢,这就需要训练了。
具体如何训练,举例说明。我们预先准备一个 多维坐标。准备10000个词,把这 10000个词随便扔到坐标里,也就是随机产生每个词的向量,如下图所示。
机器见到这句话后大喜过望,赶忙去自己的向量空间去找到第一个词 “话“ 和第二个词” 说“ ,把它们的 向量拿过来一通 计算,看看第二个词跟在第一个词背后的 概率有多大,结果算出来 概率很小, 说明一开始随便放的 位置不合适。

怎么办?那赶紧调整呗,经过不断尝试后最终调整好了词的位置。


A爸:这下我是算搞明白了,原来是这样啊!
L:10年前Google就发布了 word2vec模型,详见 《 E fficient Estimation of Word Representations in Vector Space 》 。 不过既然词向量已经帮机器理解每个词的意思 , 为什么大模型 到今天才发展起来?
L:是的。
A爸:具体该如何进行 信息压缩与特征提取?
L:精彩程度让人拍案叫绝!细节可参考Google论文 《 Attention Is All You Need 》 。 时候不早了,咱们下回分解吧。
公众号:收获不止数据库
微信:ljbyxl1213
-
“大白话人工智能” 系列
-
“数据库拍案惊奇” 系列
-
“世事洞明皆学问” 系列
来自 “ ITPUB博客 ” ,链接:https://blog.itpub.net/9091385/viewspace-3079720/ ,如需转载,请注明出处,否则将追究法律责任。






