机器之心报道
编辑:冷猫
Training Small, Thinking Big.
大模型的推理架构颠覆的未免有些太快了。
今年 6 月,来自 Sapient Intelligence 的研究者提出了分层推理模型(HRM),用循环架构打破了传统思维链(CoT)的架构限制,对大模型推理结构产生了重大的影响。HRM 仅包含 2700 万个参数(大约比最小的 Qwen3 0.6B 模型小 22 倍),仅使用 1000 个训练样本,便在复杂的推理任务上取得了卓越的性能。
对 HRM 感兴趣的读者可以参考我们之前的报道。
仅仅过了四个月,HRM 的架构就彻底不够看了。
来自加拿大蒙特利尔三星先进技术研究所(SAIT)的高级 AI 研究员 Alexia Jolicoeur-Martineau 介绍了微型递归模型(TRM)。
这个 TRM 有多离谱呢?一个仅包含 700 万个参数(比 HRM 还要小 4 倍)的网络,在某些最困难的推理基准测试中,其参数数量与 o3-mini 和 Gemini 2.5 Pro 等尖端语言模型相比,甚至可以超越它们,尽管这些模型的参数数量是 TRM 的 10,000 倍。
这一结果让很多业内人士大呼不可思议。


论文作者 Jolicoeur-Martineau 说:「通过递归推理,结果证明 『少即是多』。一个从头开始预训练的小模型,通过递归自身并在时间推移中更新答案,可以在不超出预算的情况下取得很大成果。」

- 论文标题:Less is More: Recursive Reasoning with Tiny Networks
- 论文链接:arxiv.org/abs/2510.04871v1
简而言之,TRM 的工作原理如下:
1. 起草初始答案:不同于逐字生成的普通大语言模型(LLM),TRM 首先会快速生成一个完整的「草稿答案」,可以理解为它的第一次粗略猜测。
2. 创建「思维草稿区」:接着,它会开辟一个独立的内部空间,用于储存潜在推理的「草稿板」。
3. 深入自我审查:模型进入一个高强度的内循环。它不断将草稿答案与原始问题进行对比,在草稿板上反复(连续 6 次)推敲和修正推理逻辑,不断自问:「我的逻辑是否成立?错误在哪里?」
4. 修订答案:经过这段专注的「思考」后,模型会利用在草稿板中改进后的逻辑,重新生成一个全新的、更高质量的最终答案草稿。
5. 循环至自信为止:整个「起草 — 思考 — 修订」的过程最多可重复 16 次。每一轮迭代都让模型更接近一个正确且逻辑严密的解决方案。
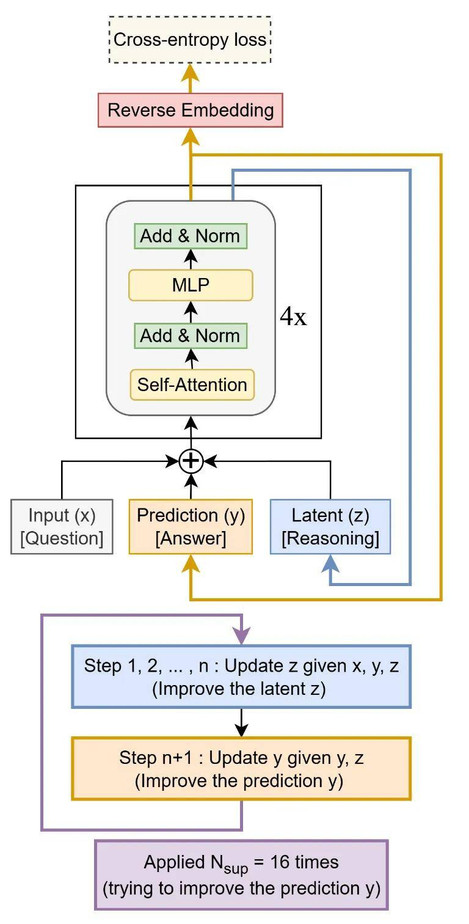
Tiny Recursion Model(TRM) 递归结构图
少即是多
不再需要不动点定理
HRM 假设其递归过程在 z_L 和 z_H 上都会收敛到某个不动点,以便使用 一步梯度近似(1-step gradient approximation)为了绕开这种理论上的约束,TRM 重新定义了「完整的递归过程」:
在训练中,先运行 T−1 次无梯度的递归过程 来改进 (z_L, z_H),然后再运行一次带反向传播的递归过程。
换句话说,不再使用一步梯度近似,而是采用包含 n 次 f_L 与一次 f_H 的完整递归更新,从而完全消除了对不动点假设和隐函数定理(IFT)的一步梯度近似的依赖。
单网络
HRM(分层递归模型)使用了两个网络:
- 一个低层模块 f_L,被频繁调用;
- 一个高层模块 f_H,被较少调用。
这种设计使得模型的参数量约为常规单网络监督学习的两倍。
基于这一观察,研究者尝试用一个单一网络来同时完成这两个任务,而不是分开训练两个网络。
少层数
研究者尝试通过增加层数来扩大模型容量,以实现模型的可扩展性。
然而,结果令人意外 —— 增加层数反而降低了泛化能力,原因在于模型出现了过拟合。
于是研究者们反向实验:
在保持总计算量和 「等效深度」大致不变的情况下,减少网络层数,同时按比例增加递归次数 n。
结果发现,使用 2 层(而非 4 层)时,泛化性能达到最优。
无注意力架构
自注意力机制(Self-Attention)在长上下文场景表现出色,因为它只需一个形状为 [D, 3D] 的参数矩阵,却能建模整个序列的全局依赖。
然而,在短上下文任务中,使用线性层(Linear Layer)更加高效,仅需一个形状为 [L, L] 的参数矩阵即可完成建模。
受到 MLP-Mixer 的启发,将自注意力层替换为作用于序列维度上的多层感知机(MLP)。
实验结果
研究者们在以下数据集上评估方法:Sudoku-Extreme、Maze-Hard、ARC-AGI-1 以及 ARC-AGI-2。
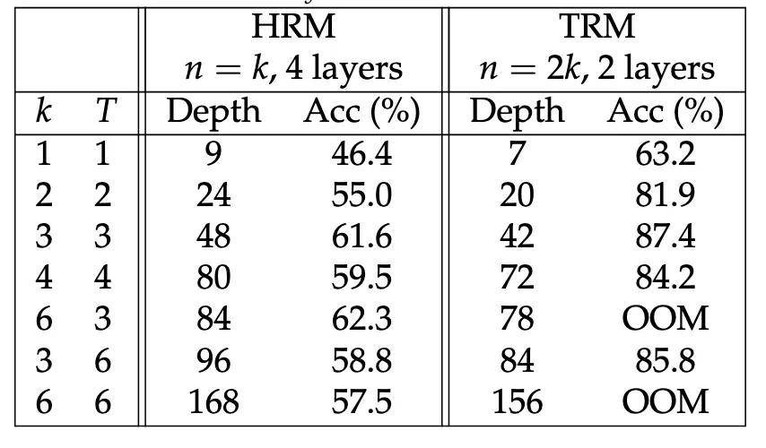
在 Sudoku-Extreme 数据集上的测试准确率(%)。在每个监督步骤的等效深度(T (n + 1) × n_layers)相同的条件下,对比 HRM(Hierarchical Reasoning Model) 与 TRM(Tiny Recursion Model) 的性能。
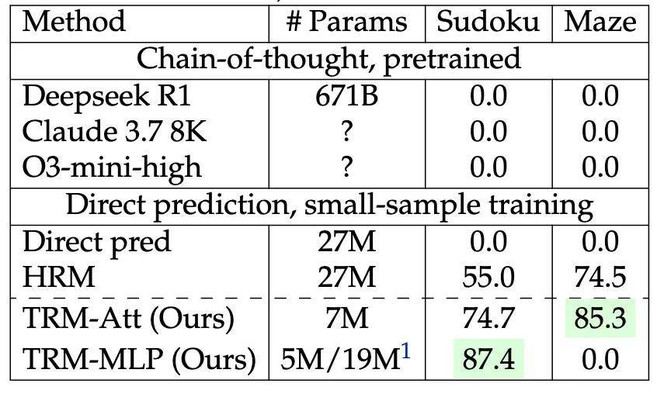
在谜题类基准测试(Sudoku-Extreme 和 Maze-Hard)上的测试准确率(%)。
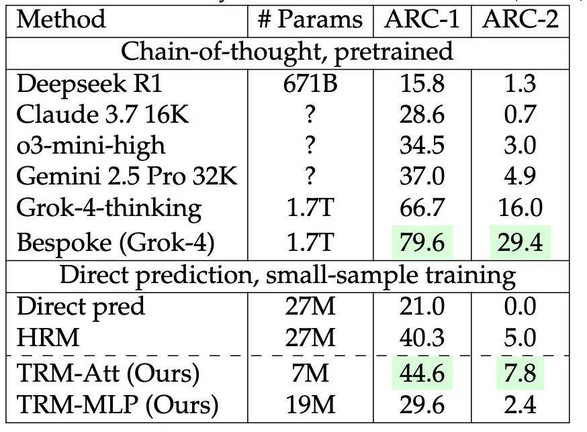
在 ARC-AGI 基准测试(尝试 2 次)上的测试准确率(%)。
从实验结果可以看出,不带自注意力机制的 TRM 在 Sudoku-Extreme 上表现最佳,测试准确率达 87.4%。而 带自注意力机制的 TRM 在其他任务上泛化效果更好。
带自注意力机制的 TRM 在 Maze-Hard、ARC-AGI-1、ARC-AGI-2 上的准确率分别为 85.3%、44.6% 和 7.8%,模型规模为 700 万参数。
相比之下,使用 4 倍参数量(2700 万) 的 HRM 模型仅达到 74.5%、40.3% 和 5.0% 的准确率,显示出 TRM 在参数效率与泛化能力上的显著优势。
更多信息请参阅原论文。
参考链接:
https://venturebeat.com/ai/samsung-ai-researchers-new-open-reasoning-model-trm-outperforms-models-10
https://x.com/JacksonAtkinsX/status/1975556245617512460







