谷歌Genie 3来了,一句话就能生成可交互的3D空间。这篇文章帮你快速了解它的核心能力、应用场景和背后技术逻辑,提前卡位下一波AI内容浪潮。

就在昨天深夜,当你我可能还在为工作收尾或准备入睡时,地球另一边的谷歌DeepMind悄悄投下了一颗重磅炸弹,科技圈瞬间“核爆”。
他们发布了一个名为Genie 3的模型。
简单说,这不是一个聊天机器人,也不是一个视频生成器。它是一个“世界模型”。你只需给它一句话,它就能在几秒钟内为你创造一个可交互、可探索的3D虚拟世界。

这已经不是“让AI画个画”或“做个视频”那么简单了。这是在创造一个“地方”,一个你可以“走进去”的梦境。
今天,我们就来深度拆解一下,这个Genie 3到底是什么?它有多牛?它将如何颠覆游戏、机器人甚至我们每个人的未来?
Part 1:Genie 3究竟是个什么“神灯”?
让我们用一个简单的比喻来理解:
如果说OpenAI的Sora像一位天才导演,能根据你的剧本拍出一段以假乱真的高清电影;那么谷歌的Genie 3,则更像一位“创世神”,直接给你一把钥匙,让你进入一个可以随意探索的梦境世界。
Genie 3的核心能力有三点,每一点都足以让人惊掉下巴:
- 文本到世界(Text-to-World):这是基础。你输入一个文本提示,比如“一个郁郁葱葱、有瀑布和发光蘑菇的魔法森林”,它就能立刻生成这样一个3D世界。
- 实时交互(Real-timeInteraction):这是关键!它生成的不是一段固定视频,而是一个可以实时渲染的互动环境(720p分辨率,24fps帧率)。你可以像玩第一人称游戏一样,在里面行走、跳跃、环顾四周。
- 可提示的世界事件(PromptableWorldEvents):这是它的“杀手锏”。当你已经身处这个世界时,你可以继续用文字下达指令来改变它!比如,你正走在一片平静的火山旁,可以输入“让火山喷发”,然后眼前的火山就会开始涌动岩浆!
根据谷歌放出的演示,研究员在一个由Genie 3生成的房间里,输入指令“在墙上涂上红色的油漆”,然后他真的可以像玩游戏一样,拿起“喷漆枪”在墙上涂鸦。最可怕的是,他转身离开再回来,墙上的涂鸦还在——这意味着这个世界拥有了“记忆”和“物理一致性”。
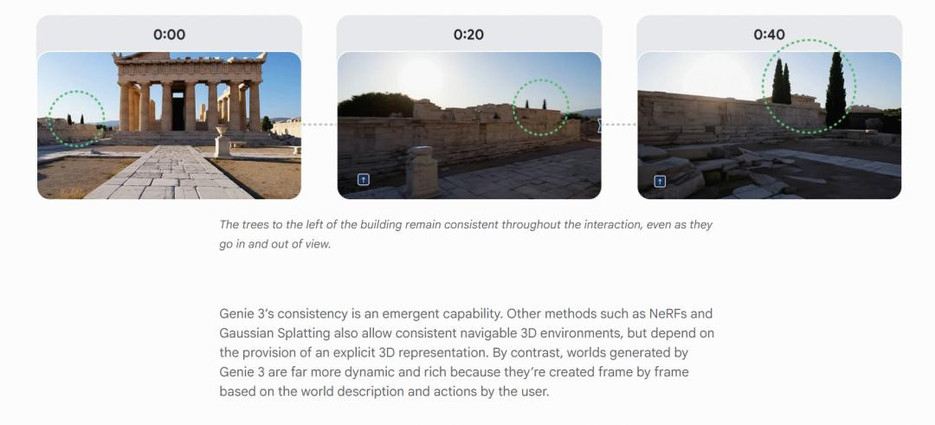
这背后代表的,是AI从“观察世界”到“理解世界运行规律”的巨大飞跃。
Part 2:技术揭秘:Genie 3的“魔法”从何而来?
这么神奇的效果,技术上是怎么实现的?虽然谷歌尚未公布完整的论文,但根据其博客和技术分析,我们可以一窥其“魔法”的秘密。
它主要由三大模块构成:
- 时空视频分词器(SpatiotemporalVideoTokenizer):负责“看”。它通过观看海量的网络视频(尤其是游戏视频),学习世间万物长什么样,以及它们是如何运动和互动的。
- 潜在行动模型(LatentActionModel):负责“动”。它理解“向前走”、“跳”这些指令在虚拟世界里意味着什么。
- 动力学模型(DynamicsModel):相当于这个虚拟世界的“物理引擎”。它负责预测你做出一个动作后,下一帧画面会发生什么。
而它能实现“物体恒存”(object permanence)的关键,很可能在于一种混合3D表征的方法。简单来说:
它不像传统模型那样一帧一帧地“画”出新画面,而更像是在自己的“脑海”里,对你周围的环境建立了一个简易的3D地图。所以即使你没在看某个物体,它也知道那个物体还在那里。
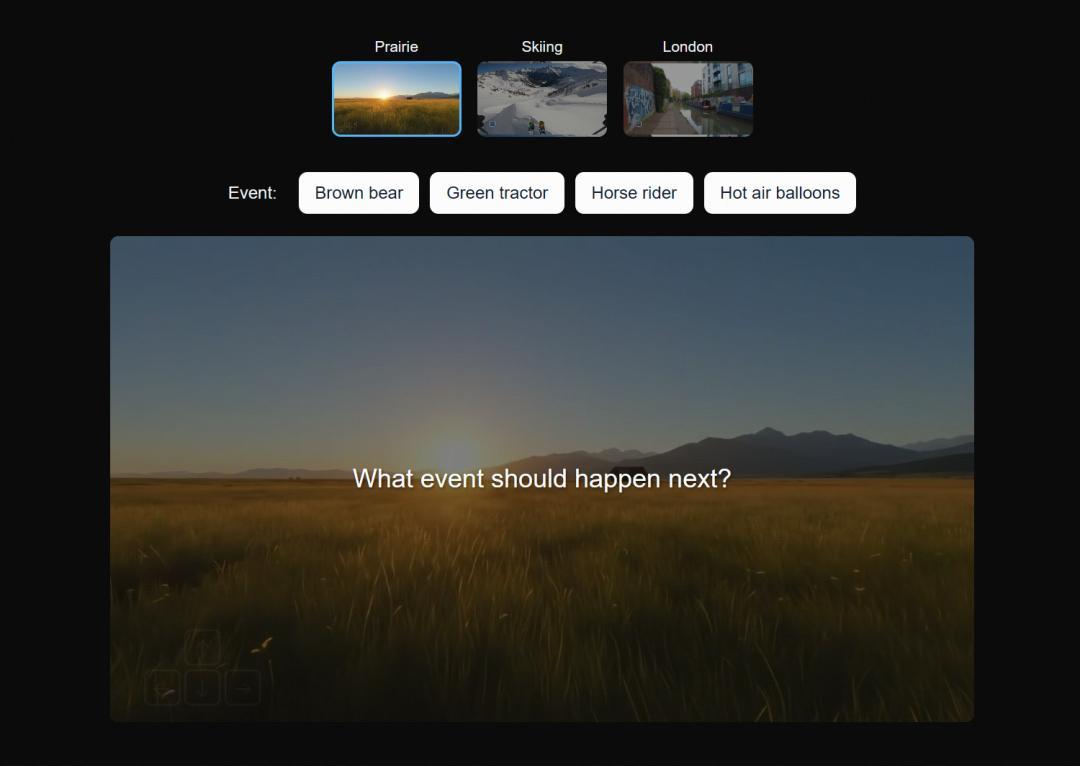
这就是为什么Genie 3感觉更像一个“世界”,而不是一个“电影”。
Part 3:谷歌的“内部封神榜”:Genie 3是如何一步步炼成的?
要理解Genie 3的突破性,最好的方式不是看它与外部对手的比较,而是看它在谷歌内部是如何“进化”的。这张由官方发布的对比图,清晰地展示了Genie 3的封神之路。
我们可以看到,从早期的GameNGen到如今的Genie 3,谷歌的AI模型在一代代的迭代中,能力不断攀升:
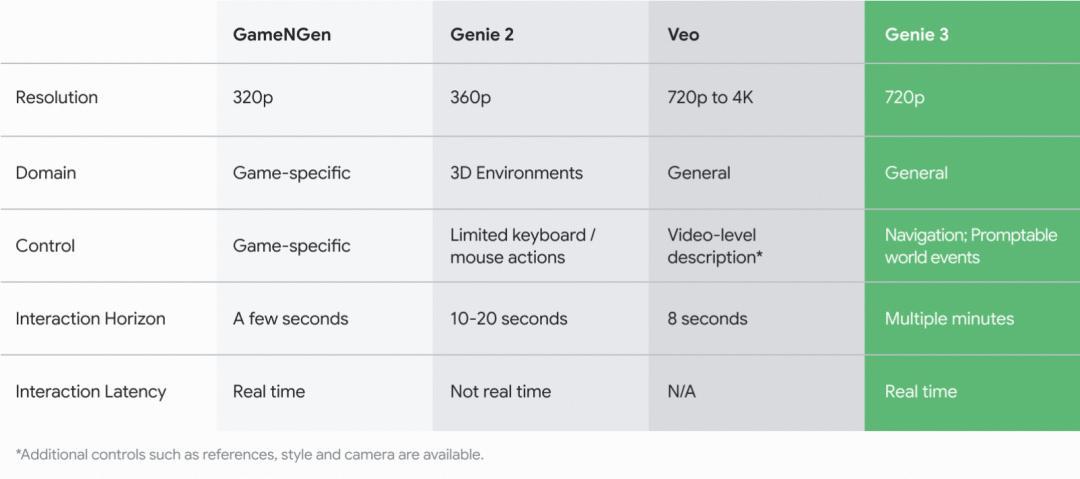
这张图信息量巨大,我们来解读一下Genie 3的几次关键飞跃:
1. 控制方式的革命 (The Revolution in Control):这是最核心的进化。控制方式从早期模型的“特定按键”和Genie 2的“有限鼠标键盘”,一跃成为Genie 3的“导航 + 可提示的世界事件”。这意味着你不仅能像玩游戏一样移动,还能用语言(Prompt)去命令和改变这个世界,这是质的飞跃。
2. 交互时长的指数级增长 (The Exponential Growth in Interaction Horizon):从GameNGen的“几秒钟”记忆,到Genie 2的“10-20秒”,再到Genie 3惊人的“数分钟”。这代表着AI对世界状态的记忆力和连贯性有了巨大的提升。你在这个世界里做过的事,在几分钟内都不会被“遗忘”,这才让一个“世界”真正变得可信。
3. “实时交互”的王者归来 (The Return of “Real-Time”)非常有趣的一点是,中间的Genie 2为了追求更复杂的3D环境生成,牺牲了“实时性”。而Veo作为一个视频模型,更不存在实时交互的概念。但Genie 3在实现了远超前代复杂度的同时,成功回归了“实时交互”,这背后是算法和算力的巨大突破。720p的分辨率正是为保证实时流畅体验而做出的最佳平衡。
结论:Genie 3并非横空出世的“天才”,而是谷歌多年研发、不断试错和迭代的“集大成者”。它继承并融合了前辈们的各项优点,最终实现了通用领域、长时程、可语言控制的实时互动,一举奠定了自己在“世界模型”领域的王者地位。
Part 4:未来已来:Genie 3将如何改变世界?
如果这项技术成熟并普及,它带来的将是翻天覆地的变化:
- 游戏行业:独立游戏开发者可以在几天内创造出过去需要一个团队耗时数年才能构建的宏大世界。未来的游戏甚至可以根据你的对话实时生成新的剧情和场景,实现真正的“开放世界”。
- 机器人与自动驾驶:这是谷歌最主要的目的。他们可以在Genie3创造的亿万个虚拟世界里,对机器人和自动驾驶AI进行近乎零成本、零风险的训练,让AI在进入现实世界前就“阅尽人间百态”。
- 电影与创意产业:导演可以在虚拟世界里进行堪景、测试镜头,甚至完成前期视觉预览,极大地降低制作成本和风险。
- 教育与培训:历史系学生可以“走进”古罗马的街头,与AI扮演的市民互动;医学生可以在高度逼真的虚拟手术室里进行反复练习。
Part 5:硬币的另一面:我们应该担心什么?
每一次技术的巨大飞跃,都伴随着巨大的风险。Genie 3也不例外。
技术局限:
首先,它并不完美。目前的交互时间只有几分钟,画面偶尔有瑕疵,对复杂物理规则的理解也有限。它还不能100%复刻一个真实的地点。
伦理风险:
- 超级深度伪造:如果能生成可交互的虚假场景,那么伪造证据、制造虚假新闻将变得轻而易举。
- 偏见固化:AI从人类数据中学习,它创造的世界也可能充满现实世界已有的偏见和歧视。
- 失业冲击:游戏场景设计师、3D建模师等职业可能会受到巨大冲击。
- 现实与虚拟的边界:当虚拟世界变得足够诱人且唾手可得,它是否会成为一个让人沉溺其中、逃避现实的“奶头乐”温床?
谷歌DeepMind对此也持谨慎态度,表示在完成全面的安全评估前,不会向公众广泛开放。
结语:推开新世界的大门
总而言之,谷歌的Genie 3不是又一个炫技的AI玩具。它是一项基础性的、具有里程碑意义的技术突破。
它标志着AI的能力,正从“生成内容”向“构建世界”的维度跃迁。
这扇通往无数新世界的大门已经被推开一条缝,门后是无尽的机遇,也潜藏着未知的风险。我们每个人都被这股浪潮裹挟着向前。
最后,留一个问题给大家:
如果只用一句话,你最想创造一个什么样的世界?在这个世界里,你又会定下什么样的规则?
欢迎在评论区留下你的“创世蓝图”!
本文由 @像素呼吸 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议







