RAG,不只是技术架构,更是一种产品思维。从“检索增强”到“生成协同”,它连接的是知识系统与用户体验的双重跃迁。但很多产品经理只看到了“能搜能答”,却忽略了背后的数据治理、提示词策略与系统设计。
作为系列终篇,本文将从产品视角拆解 RAG 的底层逻辑与落地路径,帮助你真正把它用成“认知引擎”,而不是“搜索外挂”。

1. 引言
从RAG的本质和RAG Pipeline的编排展开,把不使用RAG的坏处、使用RAG的好处、RAG系统里各个环节的思考。
- RAG的本质:知识检索与语言生成,二者的解耦再重新编排。
- RAGpipeline的编排:从离线知识库的构建,到在线检索增强生成的每一步。
2. 检索与生成的解耦
从一个不可分的、隐含在同一大模型的内部过程,拆分为两个各自可独立优化的模块。被解开的耦合不仅是检索功能和生成功能,更在于它带来的知识更新与模型训练的分离。
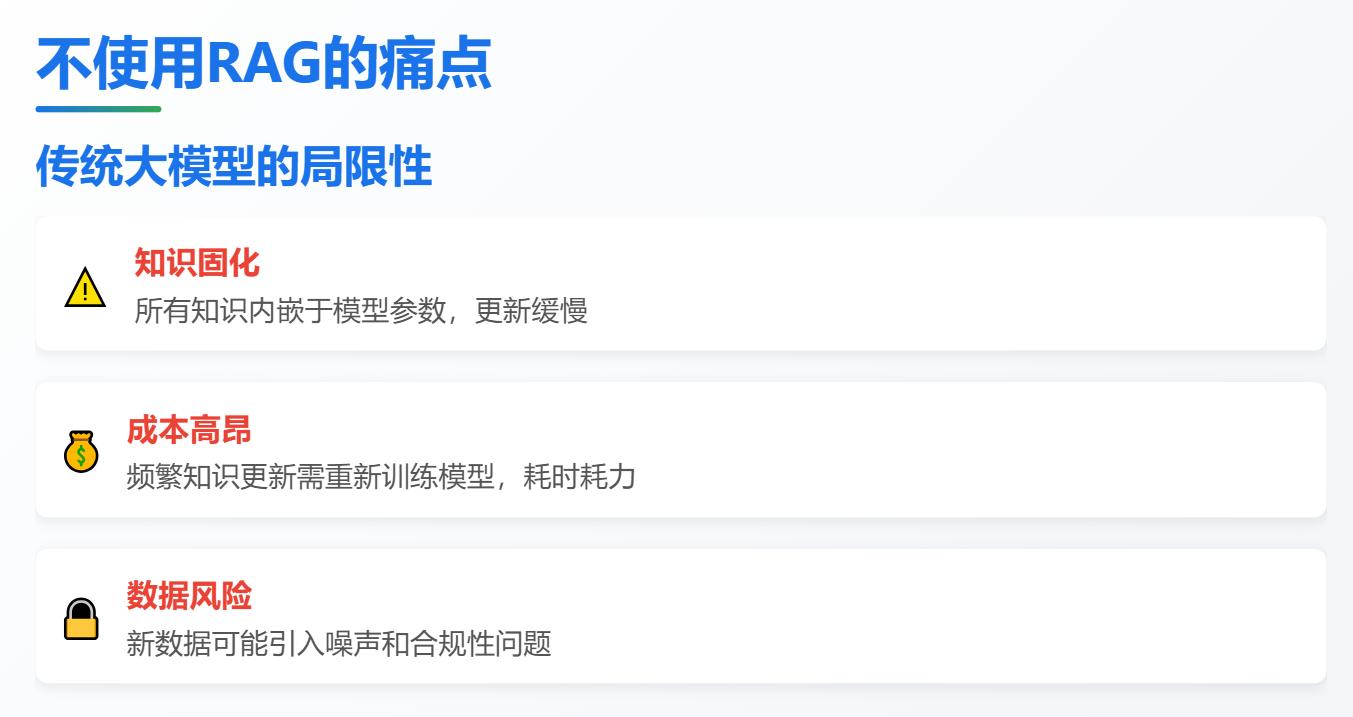
2.1 不使用RAG的坏处
在不使用 RAG 的情况下,大模型需要将所有知识都存储在模型参数中。而知识更新的速度远高于模型训练,可能以小时甚至分钟级变化。如果每次知识更新都要重新训练模型,那成本就太高了,而且还可能引入新的问题。
a)训练周期长和训练成本高:每次知识更新都可能需要对整个大模型进行重新训练或微调,这是一个耗时且昂贵的过程。RAG 通过将知识存储在外部知识库中,避免了频繁的重新训练,只需要大语言模型通过特定的检索机制 (例如,基于语义相似度的向量检索) 从知识库中按需获取相关信息,从而降低了成本。
b)数据合规性和引入新噪声:新数据可能包含不合规内容或噪声,直接用于训练会将这些问题固化在模型参数中。RAG 允许对外部知识库进行更严格的质量控制和合规性审查,从而降低了风险。
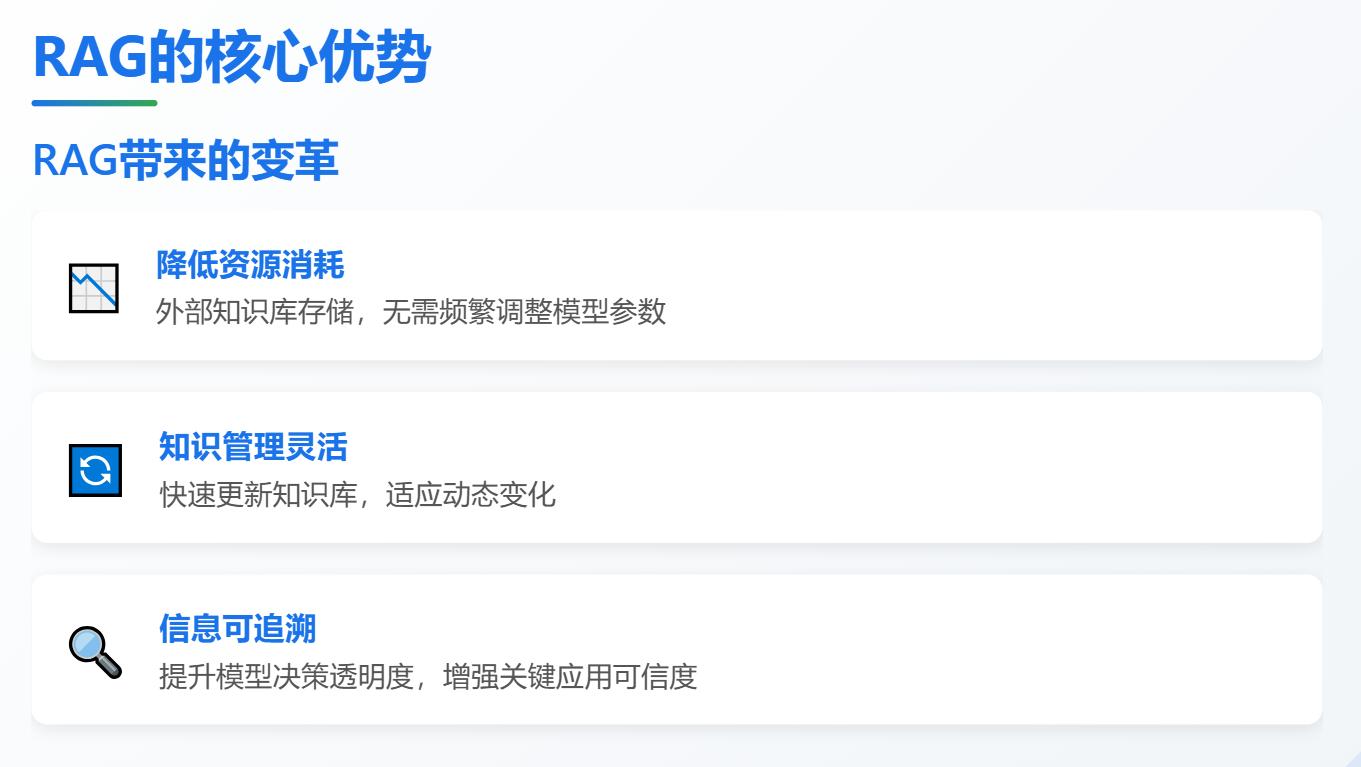
2.2 使用 RAG 的好处
在使用 RAG 的情况下,知识更新无需频繁改变模型参数,知识直接存储在外部知识库,会带来这些好处:
a)减少资源的消耗:模型通常会将知识直接编码到模型的参数中,知识越多,参数越多,计算量越大,就需要更多计算资源来进行部署和推理 (在部署时,需要大量的内存来加载模型参数,就需要高性能服务器和 GPU;在推理时,模型需要对每个参数进行计算,相应基础设施的调度会消耗大量电力)。
b)知识管理更灵活:轻松地添加、删除或修改知识库中的信息,而无需更改或重新训练大语言模型。这使得系统更容易适应不断变化的知识需求,例如,可以快速地添加最新的行业报告、法规更新或产品信息,确保模型始终提供最准确和最新的答案。
c)信息的可追溯性:大语言模型被认为是黑盒,因为很难理解它为什么会做出这样的回答,这使得它在医疗、金融、法律的关键应用中的应用受到限制。通过 RAG 可以追踪模型在生成答案的知识来源,验证模型是否使用了可靠的信息,为人类的决策提供具体依据。
★ 3. Rag pipeline的编排
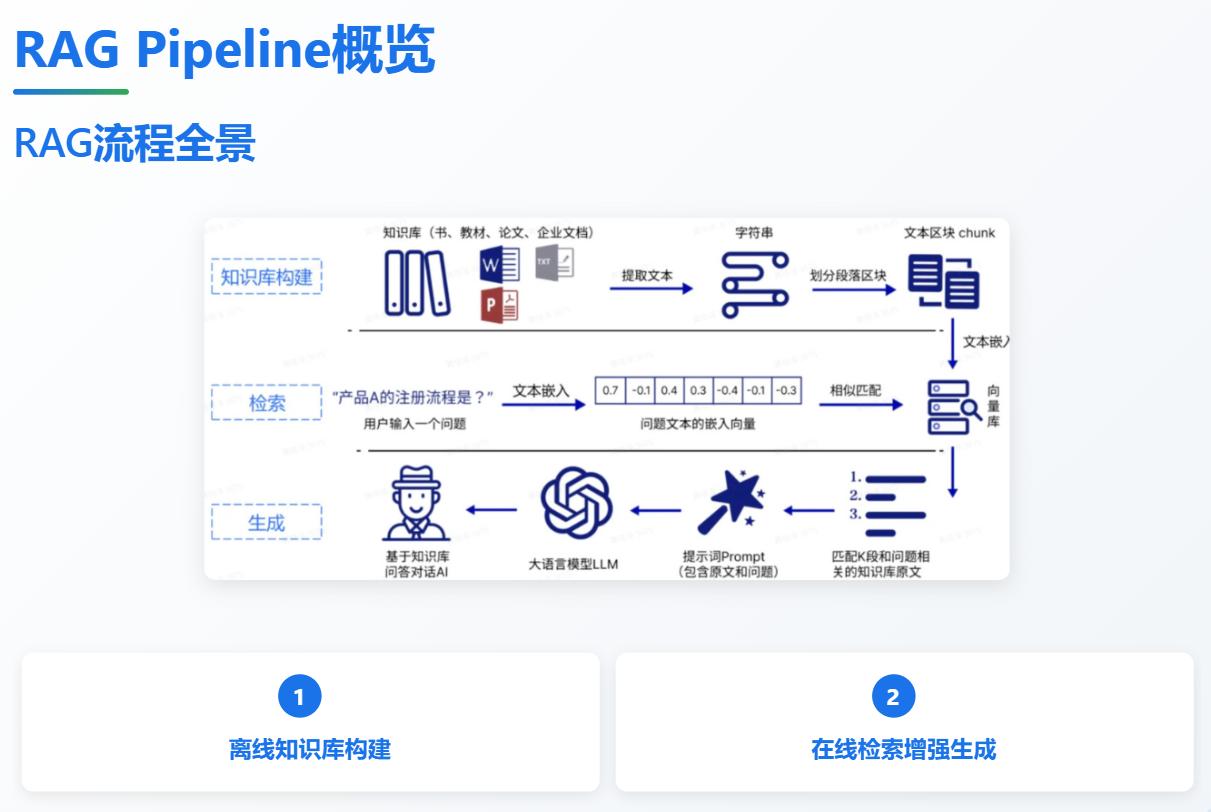
(总的来说分为:离线知识库的构建+在线检索增强生成)
a)数据收集:从各种数据源获取原始数据,并对数据进行预处理,涉及不同类型数据的解析策略 (word、pdf、ppt、跨页表格)。
b)数据分块:将长文档切割成语义相对完整的文本块 (Chunk),涉及不同类型数据的分块策略 (比如结构化数据与非结构化数据、长文段与短文段)。
c)向量嵌入:将上一步的文本块转换为向量。需要用向量嵌入模型 (Embedding Model) 将文本信息嵌入到向量空间中,涉及模型的选型。
d)存储与索引:将上一步的向量化的文本块存储进向量数据库中 (存储),并将文本块按照一定规则排列好 (创建索引),便于查询时快速检索,涉及索引结构的选择 (摘要索引、树状索引、知识图谱、向量索引)。
注意:使用向量索引时,无论是离线文本的向量化,还是在线的用户查询的编码,都必须使用同一个向量模型,保证它们编码在同一个向量空间。
e)检索与重排:系统收到用户查询 (query) 后将其向量化,并在数据空中进行相似度检索,得到大量相关的文本块并进行排序,找出与查询语义最相关的 Top-K 的文本块 (比如 Top-3 就相关性前三的资料) 作为参考。
f)答案生成:模型仔细阅读用户查询和参考资料,依据提示词生成一个有依据的回答,涉及增强提示词的设计。
注意:返回给用户之前需要进行后处理,保证生成答案的美观度和可信度,同时过滤掉不必要的信息。
虽然向量嵌入主要在数据存储时使用,但在检索重排时也会涉及。只是为了方便读者理解,在前文将向量嵌入单独作为一步进行说明,接下来将其合并为:数据收集→数据分块→创建索引→检索重排→答案生成。
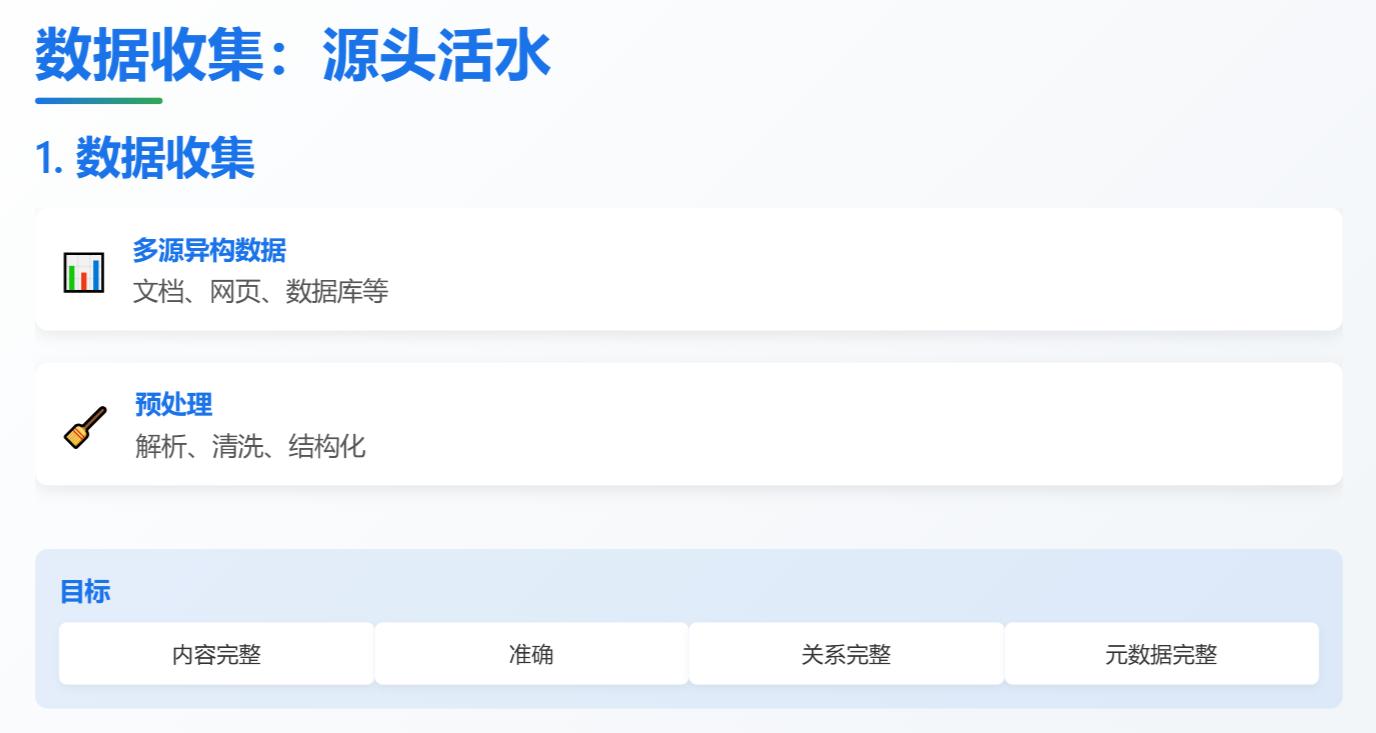
3.1 数据收集
对文档进行搬运(不同类型的文档解析方式不同),并用模型进行预处理 (打标签、生成摘要),优质的数据收集需要满足以下特点:
a)内容完整:不能漏掉任何有价值的信息,包括文字、图片、表格等。
b)内容准确:提取内容不能有错误,比如 OCR 识别出来的文本,就要尽可能地避免识别错误。
c)关系完整:数据内部存在关联性,比如主干段落与分支段落的层级关系、图片与图片说明的对应关系,能够帮助 RAG 系统更好地理解数据。
d)元数据完整:元数据就是数据的数据,数据本身具有标题、标签、大小、生成时间等信息,能够帮助 RAG 系统更好地管理和利用数据。
Word 解析方案
a)文本信息解析:使用”python-docx”库对”.doc”文档进行解析,提取出保留结构层级的信息(标题、正文、编号、列表等)
# ChatGPT 使用说明
## 简介
ChatGPT 是一个大型语言模型,由 OpenAI 训练,它可以用于各种自然语言处理任务。
(解析前)
ChatGPT 使用说明
简介
ChatGPT 是一个大型语言模型,由 OpenAI 训练,它可以用于各种自然语言处理任务。
(解析后)
b)图片标签生成:将 word 里的图片导出到指定文件夹 (image_folder),建立映射字典 (image_map) 表示 key 和 value 的关系(key 就是图片的身份证号,value 就是图片的身份证信息,包含图片路径 scr 和文字说明 alt)
比如:</><><>><>><>></><>><><>若检测到图片引用 ><>在 ><>><>将这个 ></><>><><>文档分块:在><>检索展示:在展示检索内容时,将检索结果高亮显示,将插图还原,会更加的简单和可靠。</></><><># ><>## 简介</><>><>– 文本生成</><>– 机器翻译</><>– 问答</><>[图片></><>(解析前)</><><><>></><><>简介</></><><>></>< ><></><><>文本生成</></><><>机器翻译</></><><>问答</>< class>
PDF 解析方案: Word、HTML、Markdown 是结构化文档,内部带有结构化标签,例如段落、列表、表格等,这些标签如同文档的”骨架”,方便计算机直接解析和理解。而 PDF 的设计初衷是为了在不同设备上完美展示文档,内容以页面流的形式呈现,缺乏内在的语义结构信息,是按照坐标进行绘制的,大大增加了提取难度。 PDF文档中的文本在提取出来时,排版是混乱的,不具有可读性。需要根据字符坐标 (x 和 y)、排版特征 (页码、字体、粗细、行间距)、结构信息 (标题、正文、编号、列表),像拼图一样,把这些碎片重新组合成完整的富文本结构的段落。 a)文本提取:使用工具 pdfplumber 和 PyMuPDF,或 OCR 解析PDF文件,为后续文本重组做铺垫。 文本内容:” 1. Introduction” 位置坐标:(100, 50) 字体大小:14pt 字体:Arial 加粗:True 结构:一级标题 b)文本重组:基于字符坐标、排版特征、结构信息,重建包含标题、正文、序号等结构的页面。 c)修复错误:在重新组织文本时,容易出现换行错误(一段话被错误地分成两行),这是由于坐标精度不足导致的字符位置关系不确定(公式、表格、特殊符号、字体的变化等,会导致字符间距变小,程序识别精度不够,可能会认为是字符重叠的),进而采取”强制换行“和”插入空格“这样最常见、也最保守的策略。 d)图片标签生成 e)图文内容整合 f)HTML文档导出 文本分块是自然语言处理 (NLP) 中的一项关键技术,其作用是将较长的文本切割成更小、更易于处理的片段。 为什么需要对文档进行分块?而不是直接进入下一步,提取文档的嵌入向量。 分块过大: 降低检索精度,增加计算成本,易超出模型上下文窗口导致信息截断。分块过小: 造成上下文缺失(如论点论据分离、数据分析脱节),影响模型对信息的完整理解。 分块大小需要考虑几个维度: a) 数据本身的结构特点:学术论文需要长段的完整的分块,视频文案天然适合较短的分块。 b)用户提问的长度和复杂性:用户输入的文段长度和问题的复杂程度,影响结果需要参考的上下文长度。 c)Embedding 模型的适配:不同的嵌入模型,对文本块颗粒度的适应性不同,影响检索的效果。 d)计算成本和响应时间:分块越大,意味着生成内容时发给 LLM 的内容越多,成本和延迟都会增加。 Token 切片 (滑动窗口) 滑动窗口是实现 Token 切片的一种常见方式,你可以把它想象成一个在文本序列上滑动的尺子,它有固定的长度 (chunk_size),每次滑动一定的距离,就从尺子框住的头和尾切下一块。 举个例子,假设我们有一段文本: [A、B、C、D、E、F、G、H、I、J、K、L、M、N、O、P、Q、R、S、T、U、V、W、X、Y、Z] 如果我们设置 chunk_size = 5,chunk_overlap= 2,那么切出来的效果就是: 切片 1: [A, B, C, D, E] 切片 2: [D, E, F, G, H] 切片 3: [G, H, I, J, K] 分块时使用配套的分词器 (Tokenizer) 可以确保分词方式与模型训练时使用的方式一致,从而获得最佳性能。LLM 模型的官方文档会明确指出推荐使用的 Tokenizer,或者有自己的 Tokenizer (例如 BERT、GPT 有自己专门的 Tokenizer,与模型一起发布)。同时,也需要考虑语言和任务,在 Hugging Face Transformers 库中寻找合适的分词器,并进行效果评估。 一句话总结:Token 切片是目标,就像我们要把蛋糕切成小块;滑动窗口是手段,就像切蛋糕的刀,决定了怎么切、切多大。它的特点是简单粗暴,但是也容易破坏语义完整性。 句子切片 使用正则表达式识别中文标点符号(句号、问号、感叹号等)是一种简单直接的中文文本分句方法,虽然不如语义切片精确,但足以满足基本需求。 递归分割 递归分割按照预设的优先级顺序 (段落分隔符/两个换行符 → 换行符 → 句子分隔符 → 空格),依次尝试使用这些分隔符将文本分割成更小的块,直到文本块的大小都满足预设的限制。就像一个要减肥的人吃蛋糕,一次不能吃太多,不然卡路里超标。先切一大块,发现切多了,热量高了,就再补一刀,直到大小合适,热量正常为止。 -最高优先级:按照段落 (两个换行符/单个换行符) 切割。 -再次:按照句子分隔符 (句号、问号、感叹号) 切割。 -接着:按照空格切割 (尽量保证单词完整)。 -最低优先级:如果以上方法都不行,就强制按照字符切割 (最坏的情况)。 专门分块(数据本身有特定规则) 根据 Markdown 语法规则(标题、加粗、代码块等)进行分块。 根据 LaTeX 命令(如 \section, \subsection)来创建逻辑块,如章节和小节。 语义切片 通过 LLM 理解语义后,依据上下文精准灵活地进行分割。切片的精度高,但计算成本也高。 滑动窗口+语义切片 语义切分优先 (首先将文本分割成具有完整语义的块),超过限制的块用滑动窗口 (如果语义块仍然过大超出 token 限制,则对该块使用滑动窗口切分)。 a)大模型理解语义:将原始文本切分成语义段落 (例如,有”原始语义段落 1″和”原始语义段落 2″)。 b)判断每个段落的大小:如果段落大小合适 (比如 ≤50 tokens),则直接采纳。 c)滑动窗口并进行切片:针对过长段落进行 token 切片,生成含重叠的子切块。 举个例子,原始段落如下: “RAG 框架是一种将检索和生成相结合的技术。它首先从大规模知识库中检索相关信息,然后利用这些信息来生成更准确、更有针对性的回复。与传统的生成式模型相比,RAG 框架能够显著提升生成内容的质量和可信度。本段主要介绍 RAG 的基本概念和优势。要搭建一个基于 RAG 框架的智能客服,你需要准备以下几个关键组件。” a)大模型语义理解 原始语义段落1:”RAG 框架是一种将检索和生成相结合的技术。它首先从大规模知识库中检索相关信息,然后利用这些信息来生成更准确、更有针对性的回复。” 原始语义段落2:”与传统的生成式模型相比,RAG 框架能够显著提升生成内容的质量和可信度。本段主要介绍 RAG 的基本概念和优势。要搭建一个基于 RAG 框架的智能客服,你需要准备以下几个关键组件。” b)判断每个段落的大小 原始语义段落1: 45 个 token,小于 50 token 的阈值,因此直接采纳。 原始语义段落2: 70 个 token,大于 50 token 的阈值,需要进一步切分。 c)滑动窗口并进行切片(含重叠部分) 子切块2.1:”与传统的生成式模型相比,RAG 框架能够显著提升生成内容的质量和可信度。本段主要介绍 RAG 的基本概念和优势。” 子切块2.2:”本段主要介绍 RAG 的基本概念和优势。要搭建一个基于 RAG 框架的智能客服。你需要准备以下几个关键组件。” 普通分块的问题在于,直接切分可能会破坏语义的完整性,但如果整个文档太大,又会超出 token 数量的限制。而滑动窗口+语义切片的优势就在于,既能保证语义完整性,又不会让单个文本块过大:先做语义切分 (保证语义完整性),若语义切分后的块还是很大,超出token限制,再对这个块做滑动窗口切分 (解决chunk大小问题)。 分块策略的选择a)先结构化后语义 面对 word、ppt、markdown 这种结构化的文档,优先采用专门切块,按照目录/章节/列表的格式进行切片,再视情况而定是否要追加语义切片。可以最大化的保留文档的语义,结构化部分也可作为检索特征。 b)非结构化就语义 面对小说、散文、哲学这种典型的结构化文档,就需要采用语义切块。可以避免整段语义的分割,便于模型理解抽象概念。 工作流: – 句子级拆分:将文档按句子进行划分。 – 组块构建:连续多个句子组合成一个“句子组”。 – 语义嵌入生成:使用指定嵌入模型为每个句子组,生成向量表示。 – 语义相似度计算:通过余弦距离衡量相邻句子组之间的语义差异。 – 动态切分决策:当语义差异超过设定的阈值,则在此处进行切分。 c)窗口重叠来补救 token 切片和递归切片,这种固定规则的切片方式,容易破坏语义结构,有时需要采用窗口重叠来补充上下文。重叠比例一般在 10%-20%之间,宁愿多消耗算力,也要保证语义信息的完整。 索引是检索增强 LLM 中的一个核心组件,用于组织和存储向量化后的文本内容 (chunk),以便用户能够快速找到所需的信息。简单来说,它就像书的目录一样,可以帮助你快速定位到书中的相关章节。 以下是几种常见的索引结构: a)摘要索引:将节点按照顺序链接起来。检索时,可以顺序遍历所有节点或根据关键词进行过滤。 b)树索引:将节点组织成树状结构,检索时可以从根节点向下遍历,也可以直接利用根节点的信息。 c)关键词表索引:从每个节点中提取关键词,并建立关键词与节点的多对多映射关系。适用于查找包含特定关键词的文档,但在处理多关键字查询时效率较低 (过于复杂)。 d)向量索引:使用文本嵌入模型将文本块转换为固定长度的向量,并存储在向量数据库中。检索时,将用户查询文本也转换为向量,并通过向量相似度计算来查找最相似的节点 (这是目前最流行的方法)。 e)知识图谱索引:知识图谱是不同知识之间的关系图。 f)多层表示索引:通过创建多个向量来表示每个文档,例如: 通过较小的表示(摘要或块)进行检索,但将它们链接到完整的文档/上下文中进行生成,核心思想是在保证检索效率的同时,尽可能提供完整的上下文信息。 传统的搜索技术,要么因为过于依赖关键词而忽略了用户的真实意图,要么就是因为信息处理能力有限而遗漏了关键信息。而在RAG中需要检索相关资料作为上下文,发给大模型。但是,如果一股脑地把Top50 的资料都塞给大模型,显然会带来一些问题 (token 消耗过大、模型受窗口限制无法读取全文)。 所以,在向量查询 (ANN) 后,通常使用 Rerank模型 进行重排序,精选 TOP5 甚至 TOP3 的相关资料。 Reranker 是一种后处理技术,常用于向量近似最近邻(ANN)搜索之后。它通过更精确的语义相关性分析,对初始检索结果进行语义级精细打分并排序,进一步提高检索的准确性。 注意:既然通过 embedding 可以理解语义,为什么还要使用 rerank?前者可以检索到相似语义的结果,但后者可以通过打分区找到最相关的结果,减少提示词上下文窗口的占用。 检索到参考资料,接下来由模型组装答案,需要使用提示词进行引导,最基础的 rag 提示词模板: 参考资料(检索到的文本快):xxx 用户查询(用户输入的指令):xxx 请你根据参考资料回答用户查询。 备注:更详细的提示词的模板可以查看《AI产品经理必修课:RAG(2)》的”三个 RAG 提示词模板——精准地引导 RAG 进行信息检索与生成”。 RAG(检索增强生成)技术在不断发展,为各种应用场景带来了新的可能性。在实际的RAG编排中,难免会遇到各种问题,如何用逆向排查的方式定位问题,可以从哪几个角思考解决方案。可以参考:RAG 系统的问题排查可以查看《AI产品经理必修课:RAG(1)》的”RAG的数据源从哪里来,出现错误信息,结果不合预期怎么办?”。 本文由 @黄晓泽 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自Unsplash,基于CC0协议></></></><>(解析后)</>< width height="945" type="1" type="image/png" uri="tos-cn-i-tjoges91tu/f6d40a3c0336a0d8058a0dd9528cc063" class="syl-page-img syl-page-img-error" data-src="/uploads/20250826/3910348d5f202ef4b7065e395de8a8fd.gif" data-syl-retry="1">

3.2 数据分块 (chunk)







3.3 创建索引



3.4 检索重排

3.5 答案生成

4. 结语







