RAG(检索增强生成)曾是连接外部知识与模型能力的关键桥梁,但随着业务复杂度提升,它的局限也逐渐显现。Context Engineering 的出现,正在重新定义“知识注入”的方式——从检索到构造,从拼接到理解,让上下文成为真正的生产力。本文将带你梳理从 RAG 到 Context Engineering 的演进路径,揭示背后的技术逻辑与产品思维,帮助你在构建智能应用时少踩坑、快落地。

我们在探索的一个问题是:大模型如何更好的落地企业自有的生产场景,为业务产生价值。Ai项目在完成POC概念验证,以小成本跑通后开始启动建设,对大模型在生产中落地应用是一般有几个要求:
- 输出:要求大模型稳定输出高准确率的结果,得出的结论有理、有据、有思考过程,有可追溯的原始数据分析过程,使用者有可反馈校准的渠道和机制;
- 分析:为了应对快速变化的市场,分析需要基于最新的实时数据、专业数据和本地专有数据来做分析决策,部分场景还需要根据使用者角色、历史上下文来做分析;
- 数据:原始数据真实可靠,跟核心任务相关的数据源还需要尽可能的充分、全面。
同时,我们也看到目前广泛在使用的生成式人工智能模型,有其本身的局限性:
- 训练数据的局限性:训练模型的数据完整性、过时的数据、数据的质量都会对模型的结果产生负面影响;
- LLM基于概率分布生成文本,而不是事实正确的文本,评测奖励机制奖励猜测而非诚实,对知识了解和理解有本质的差异,且一般在某些专业领域知识准备不足;
- 在生产中,我们也发现随着更多的token输入,超过一定临界值后模型输出的结果和准确性有明显的降低,模型能力的局限、错误的提示、上下文错误干扰、模型对知识的组合泛化失败等都会造成幻觉的产生。
复杂需求和大模型能力之间的Gap,如何降低Ai幻觉且提升在当前企业的应用能力,基于这些问题的考虑,我们引入了RAG(检索-增强-生成),从RAG到Context Engineering(上下文工程)。
一、方案设计-RAG
RAG(Retrieval-Augmented Generation,检索增强生成)干的就是这个词组在做的事情,连接知识库先检索相关知识、把检索到的相关知识作为上下文和提示词组成一个新的内容更丰富的提示词给到LLM,即增强提示,LLM基于新的提示词去生成内容。我们在判断RAG是否适用时,关键在应用场景下的大模型输出是否需要参考一个动态频繁更新的知识库,比如依赖实时变化的背景数据、动态更新的本地知识、相关的最新的市场数据信息、政策法规等来进行分析和决策:
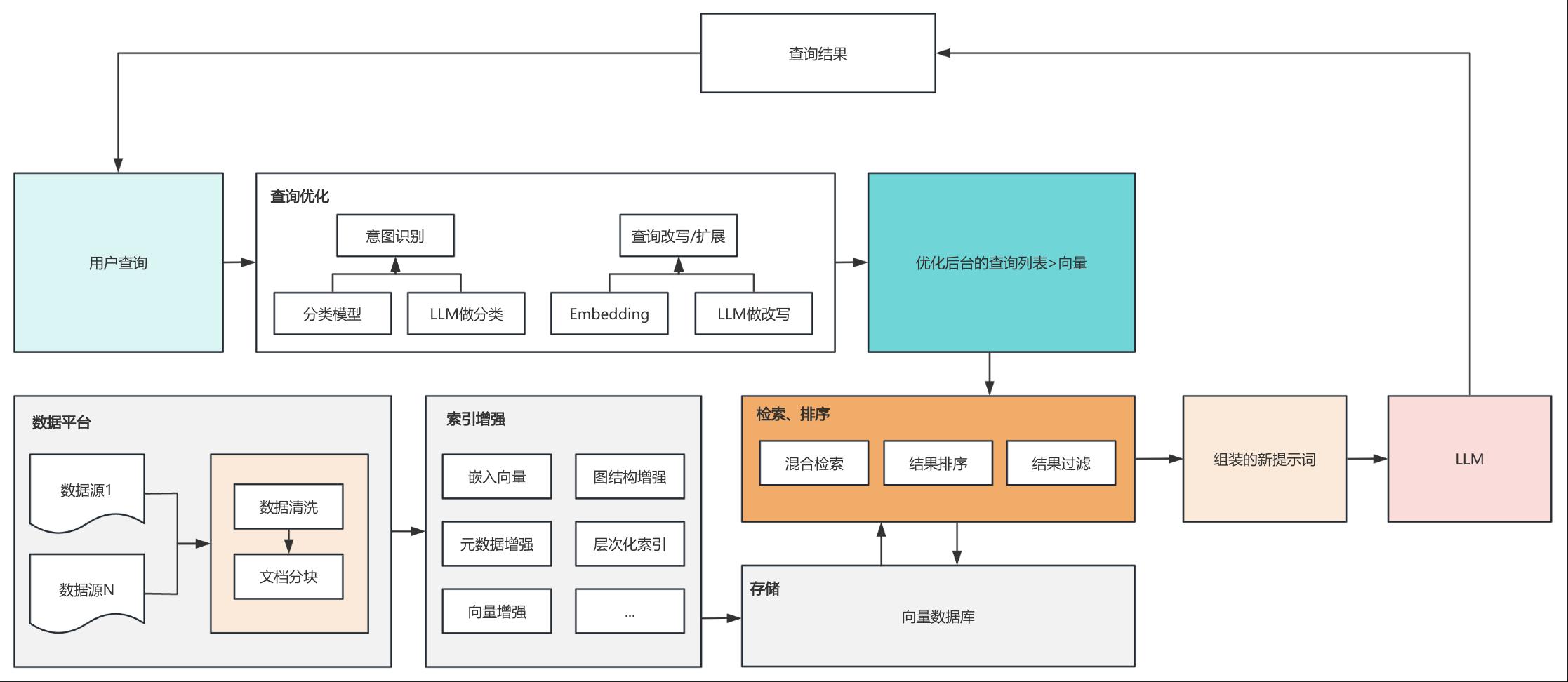
RAG方案结构
- 查询优化:在基础的RAG方案里面,用户查询是可以直接被嵌入并进行检索的,这一步是非必需的。查询优化的目的是用模型/大模型对用户输入进行意图识别、改写和分类,让系统可以更准确的理解用户的意图,从而为后续检索相关知识、输出更高质量的分析结果打下基础;
- 数据准备:在数据平台整理多方数据进行清洗、分块、生成向量,多模态数据统一到知识图谱、包括一系列索引增强技术,都是在为知识准备、索引强化上投入精力,数据可能是海量的,我们必须获取精准做到有所取舍;
- 检索技术:比如混合搜索结合了稀疏向量相似度计算,即关键词匹配,稠密向量相似度计算,即语义匹配,从而提升检索效果,然后对检索得到的结果进行关联度排序,选取topN的结果给到context去组装生成新的提示词;
- 增强、生成:知识+优化后的用户查询组装成了新的提示词进行增强,新的提示词自动带着最新的知识给到大模型,输出结果给到用户。
需要说明的是以上方案并非最简化方案,企业场景一般还是以实用为主,更简化版本也是可以跑通创造价值的,RAG的应用正在不断演进,从最基础的RAG、到具备校验/自省的RAG、到Graph RAG,利用统一的知识图谱统一多模态数据,以进行多模态的知识提取、实体与关系连接等,这些RAG的方案最终还是在检索-增强-生成这个主干流程上,面向每一步分支流程做到更好,所以在生产一线,作为产品经理来说,应该优先评估需求价值和技术实现成本之间取得平衡,更先进的技术往往有更大的落地成本,选择合适的技术满足需求,先产生业务价值再逐步迭代更新,是比较建议的做法。
二、方案设计-上下文工程
在上面第二部分着重介绍了RAG,RAG解决了最新动态知识库如何融入大模型来解决Ai幻觉的问题,从定义上来讲,Context Engineering(上下文工程)是希望通过工程设计、构建和管理输入给大语言模型(LLM)的上下文信息(Context),以精确引导大模型生成高质量、高相关性、高准确率分析结果的工程方法,RAG可以视为Context Engineering理念具体落地的一种:
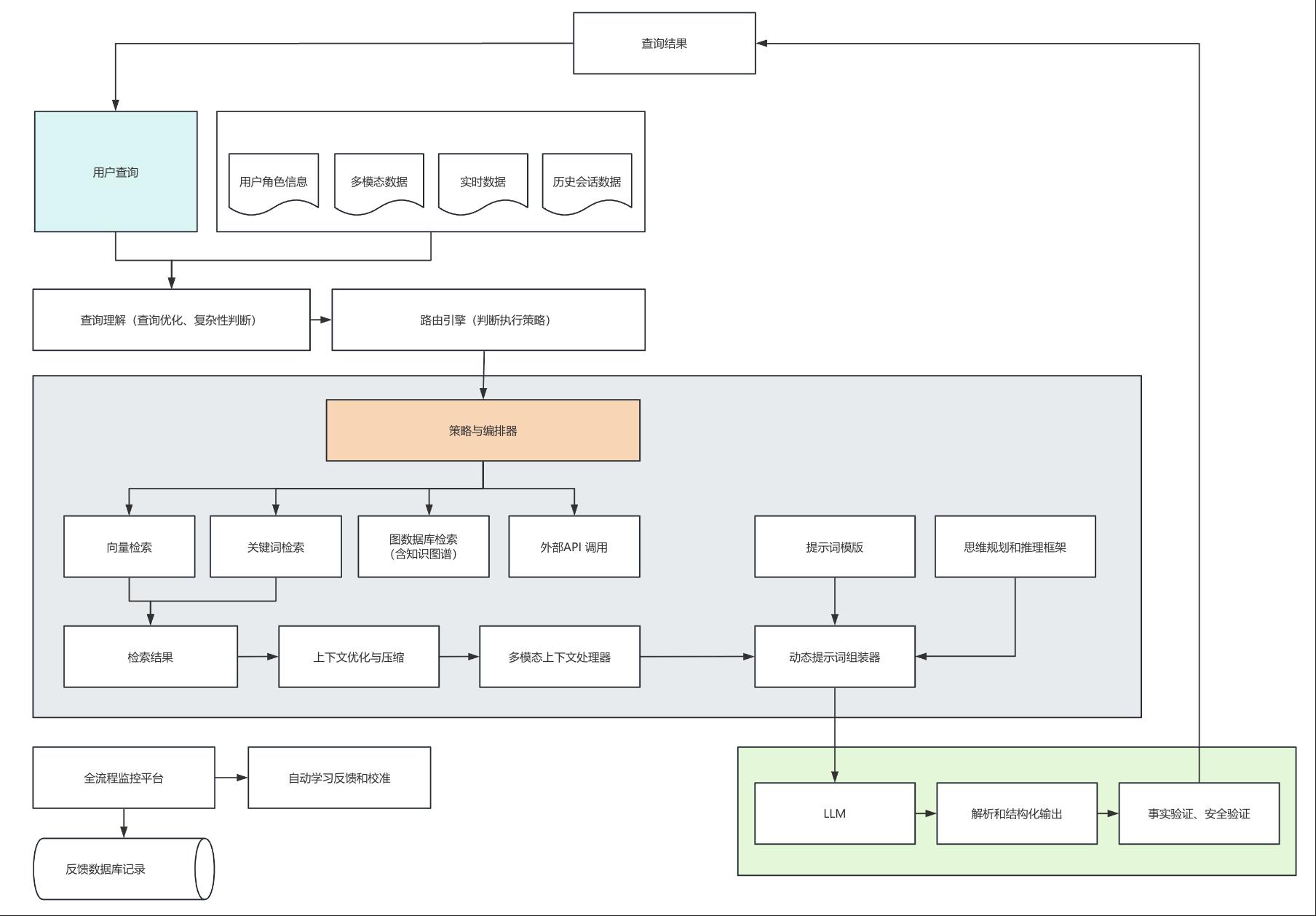
上下文工程结构
在上下文工程中,从【策略与编排器】开始的上下文组装层是工程核心,对知识、数据的检索、调用等输出原始相关信息,这里面又包含从文本、关系型数据库、音视频文件的元数据去从底层物理存储中提取具体的数据,通过对原始信息进行摘要、智能去重、相关性重排序,去除无效信息【上下文优化与压缩】,再通过【多模态上下文处理器】对多模态关联数据进行理解、描述或转录,并将结果转为文本融入上下文,最终,将所有元素——优化后的上下文数据、推理思维方式、预设的指令模板、多模态知识内容按照最优结构和格式,以新的提示词组装送给LLM,并且根据业务要求,做结构化输出,如文本、json等。
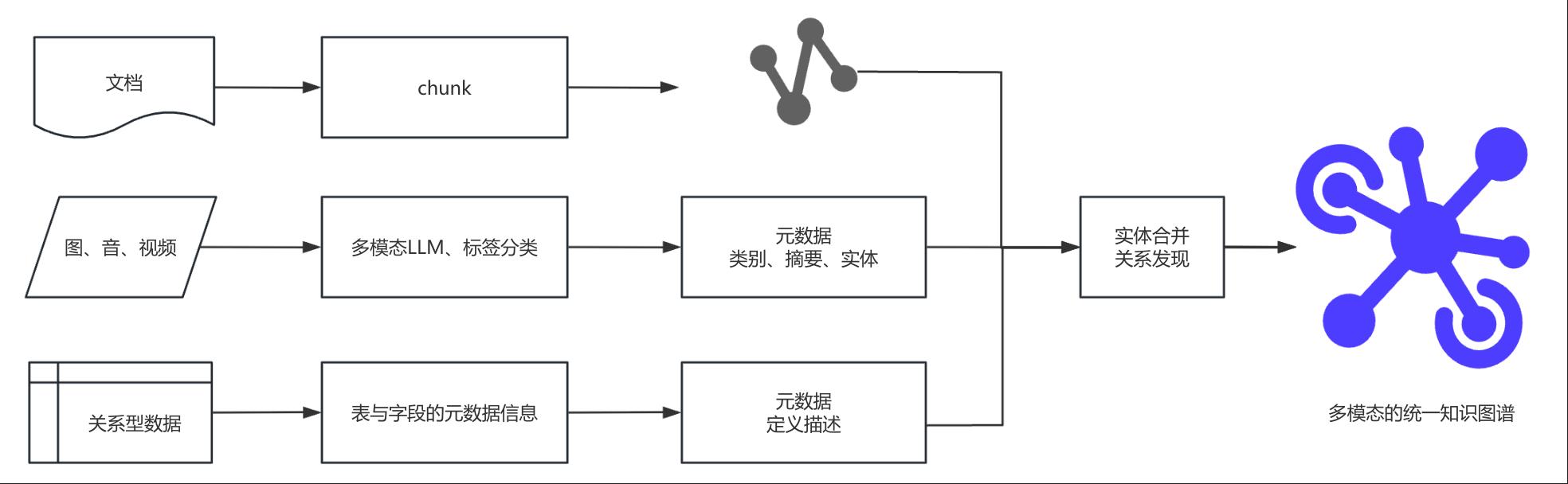
对RAG和Context Engineering来说,在对多模态数据的处理上,尤其想介绍知识图谱的环节,通过建立统一的知识图谱实现数据的存储、索引和调用,我们在生产实践中,客户逐步想要实现对各个重要数据源多模态数据的处理、更深关联的分析,这可能会是一种解法:
统一知识图谱生成:
三、总结
无论是RAG或者Context Engineering,一切探索其最终目的是为了实现系统可控、可靠、高效的AI交互,将大语言模型的能力转化为稳定、实用的生产力,应用到生产之中。在实践过程中,有时候总有种技术迭代日新月异,各种叫法层出不穷,乱花渐欲迷人眼的感觉,不过回归本质来讲,产品理论、工程思想在Ai时代也并未过时,希望本文也对你有帮助。
本文由@大风吹 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。提供信息存储空间服务。






