
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
字节跳动突发开源大模型,一出手就是360亿参数的Seed-OSS-36B。

这个Seed-OSS的命名方式,明显是在呼应OpenAI此前发布的GPT-OSS系列。
与OpenAI的开源策略也是一样,并没有直接开源核心商业模型豆包(Doubao),而是基于内部技术打造了一个专门面向开源社区的版本。
字节跳动Seed团队正式在Hugging Face和GitHub上发布了这个系列模型,采用Apache-2.0开源协议,可以免费用于学术研究和商业部署。
512K上下文窗口,还能灵活控制思考预算
要说Seed-OSS最让人眼前一亮的特性,那必须是原生512K的超长上下文。
目前主流的开源模型,比如DeepSeek V3.1的上下文窗口是128K,而Seed-OSS直接翻了4倍。
而且这个512K是在预训练阶段就构建好的,不是后期通过插值等方法硬撑上去的。
这意味着法律文档审查、长篇报告分析、复杂代码库理解等需要处理海量信息的专业场景,Seed-OSS都能轻松拿下。
此外,Seed-OSS还引入了“思考预算”(Thinking Budget)机制。
通过设定一个token数量,你就能控制模型思考的深度。比如你设置512个token的预算,模型在推理过程中会这样工作:
复制
好的,让我一步步来解决这个问题。题目说的是… 我已经使用了129个token,还剩383个token可用。 使用幂法则,我们可以… 我已经使用了258个token,还剩254个token可用。 另外,记住… 我已经耗尽了token预算,现在开始给出答案。
对于简单任务,可以设置较小的预算让模型快速响应;对于复杂的数学推理或代码生成,你可以给更多预算让它深思熟虑。
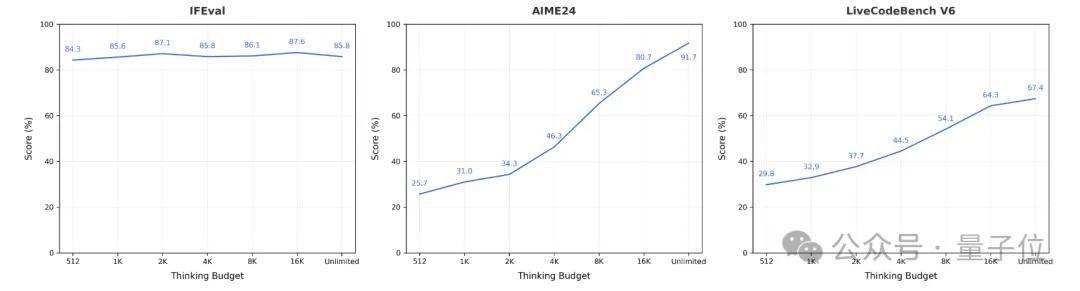
字节跳动建议使用512的整数倍(比如512、1K、2K、4K、8K或16K),因为模型在这些区间上经过了大量训练。
模型架构方面,Seed-OSS采用了成熟稳定的设计:
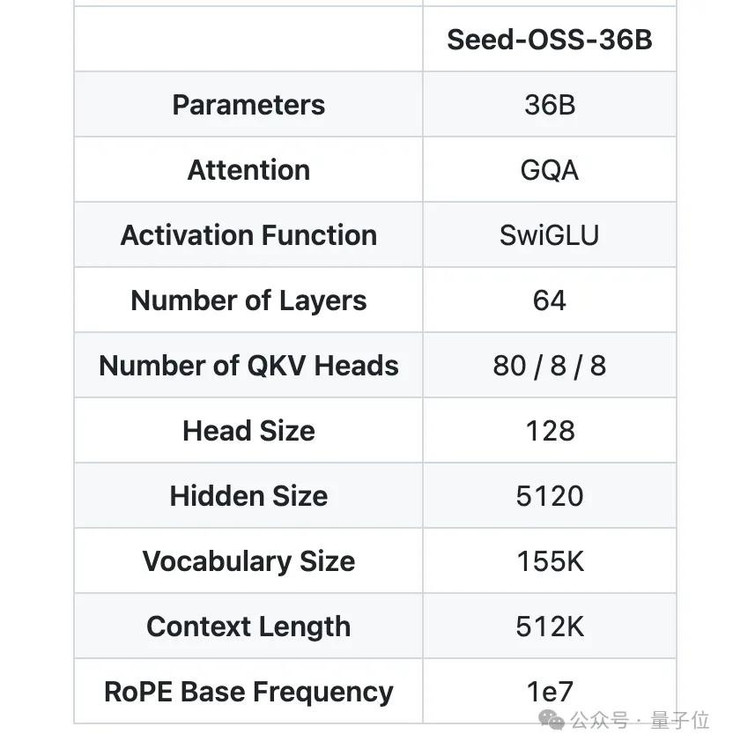
360亿参数的稠密模型(不是MoE),使用了RoPE位置编码、GQA注意力机制、RMSNorm归一化和SwiGLU激活函数。整个模型有64层,隐藏层维度5120,词汇表大小155K。
考虑到合成指令数据可能影响后训练研究,字节Seed团队提供了两个版本的基座模型,
一个包含合成指令数据(性能更强),一个不包含(更纯净),为研究社区提供更多选择。
多项基准测试开源SOTA
那么这个模型的实际表现如何呢?
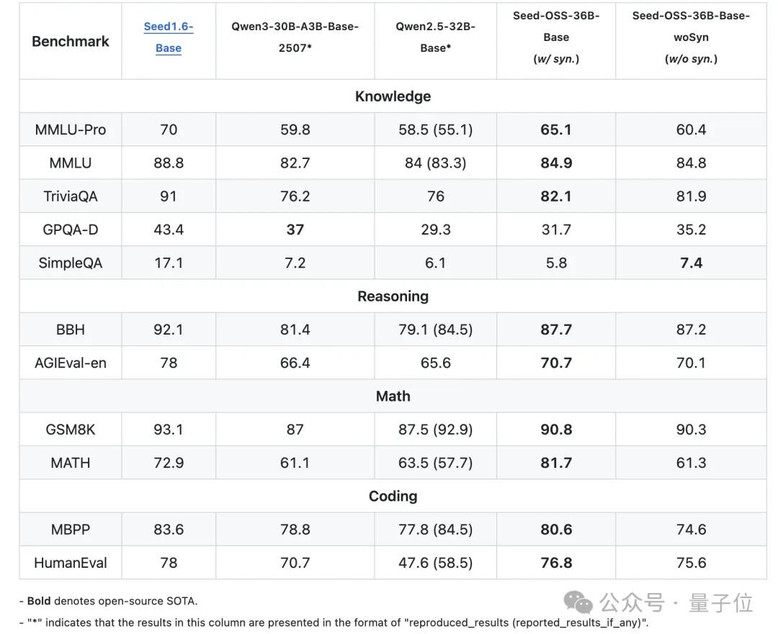
在知识理解方面,Seed-OSS-36B-Base在MMLU-Pro上达到了65.1分,超过了同等规模的Qwen2.5-32B-Base的58.5分。在TriviaQA上更是拿下了82.1的高分。
推理能力的BBH基准测试得分87.7,直接刷新了开源模型的记录。在数学能力上,GSM8K达到90.8分,MATH的81.7分。
Seed-OSS代码能力同样不俗,HumanEval得分76.8,MBPP达到80.6。
指令微调版本Seed-OSS-36B-Instruct在AIME24数学竞赛题上达到了91.7分的成绩,仅次于OpenAI的OSS-20B。
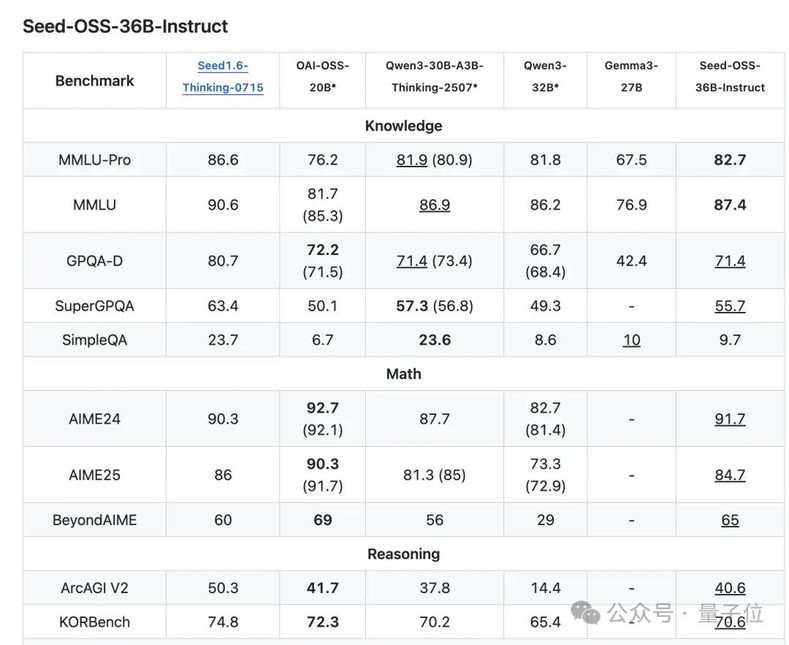
并且这些成绩是用仅12T token训练出来的,相比之下,很多同规模模型的训练数据量都在15T以上。
字节Seed团队的开源版图
字节Seed团队成立于2023年,定位是“打造业界最先进的AI基础模型”,研究方向覆盖大语言模型、多模态、AI基础设施等多个前沿领域。
过去一年多时间里,已经陆续开源了多个有影响力的项目,只不过多是细分领域模型,而不是受关注的基座语言模型。
今年5月,他们发布了Seed-Coder,一个8B规模的代码生成模型,最大的创新是让LLM自己管理和筛选训练数据,大幅提升了代码生成能力。
紧接着,他们又推出了BAGEL,一个能同时处理文本、图像和视频的统一多模态模型,真正实现了”万物皆可输入输出”。
更早之前,他们还发布了Seed Diffusion,这是一个基于离散状态扩散技术的实验性语言模型,在代码生成任务上实现了极高的推理速度。
为了支撑这些模型的训练,团队还开源了VeOmni,一个PyTorch原生的全模态分布式训练框架。
最近他们还搞了个Seed LiveInterpret端到端的同声传译模型,不仅翻译准确率高,延迟低,还能复刻说话人的声音特征。
随着Seed-OSS的开源,国产开源Base模型又添一员猛将。
GitHub:
https://github.com/ByteDance-Seed/seed-oss
HuggingFace:
https://huggingface.co/collections/ByteDance-Seed/seed-oss-68a609f4201e788db05b5dcd







