由中山大学、鹏城实验室、美团联合开源的X-SAM模型,在计算机视觉领域取得重大突破。
它首次实现了真正统一的图像分割多模态大语言模型,将分割范式从“分割万物”革命性地扩展到了“任意分割”。

创新设计
X-SAM的核心在于构建了一个统一的框架,赋予MLLMs高级的像素级感知与理解能力。其创新点主要包括:
视觉定位分割:研究团队提出了“视觉定位分割”这一新任务。它要求模型通过交互式视觉提示(如点、框)分割图像中的所有实例对象,从而赋予MLLMs视觉定位的像素级理解能力。

通用输入输出设计
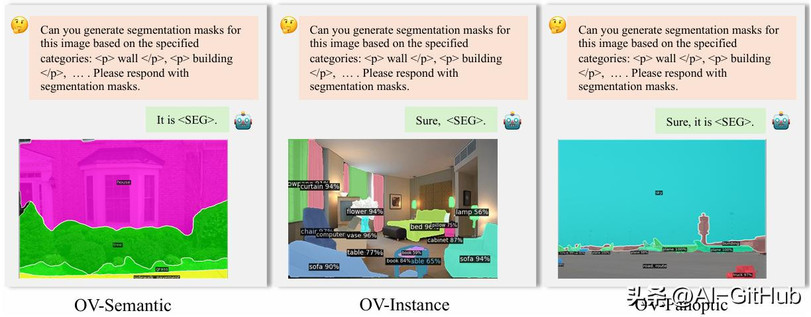
文本查询输入: 适用于通用分割、开放词汇分割、指代分割等任务。
视觉查询输入: 适用于交互式分割和VGD分割任务,支持点、涂鸦、框、掩码等多种提示。
分割连接器:针对图像分割任务对多尺度特征的需求,该组件通过上下采样路径生成多尺度特征,为解码器提供丰富的信息。
统一分割解码器:X-SAM摒弃了SAM原有的解码器,采用了Mask2Former架构。这一关键改进使得模型能够单次分割图像中的所有目标对象,彻底突破了传统SAM只能逐个处理对象的效率瓶颈,显著提升了处理复杂场景的能力。

性能表现
X-SAM在涵盖通用分割、开放词汇分割、指代分割、交互式分割、GCG分割、推理分割、视觉定位分割(VGS)等7大类、超过20个图像分割基准数据集上进行了全面评估,均达到了最先进(SOTA)性能。
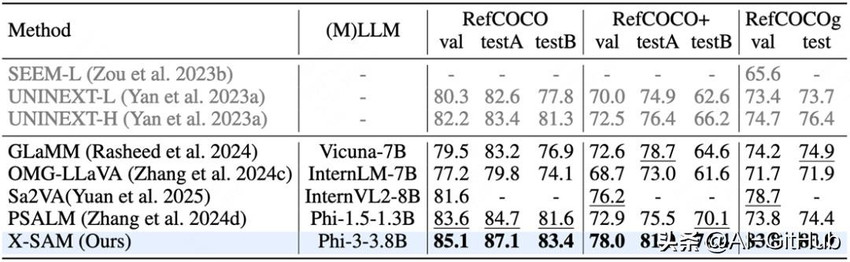
指代分割任务: 性能优异。
对话生成分割任务: 表现出色。
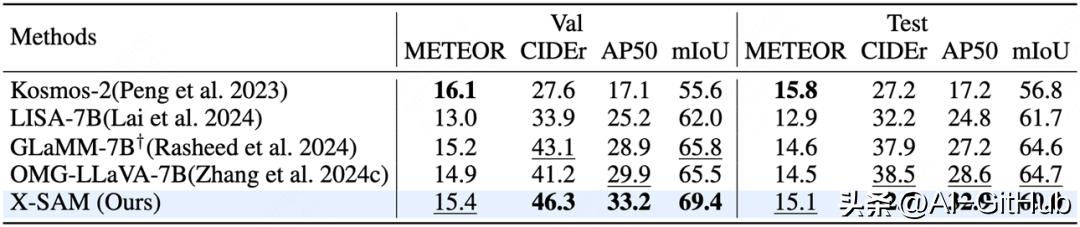
视觉定位分割任务: 验证了VGS任务的有效性。

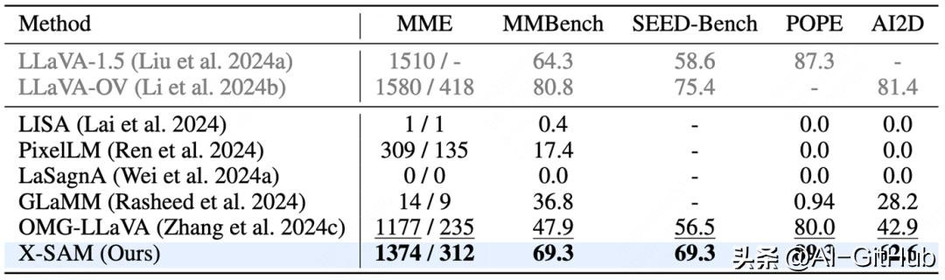
图文理解任务: 也展现了强大能力。
可视化效果:X-SAM在多种任务上的分割结果清晰准确,充分展示了其强大的多模态像素级视觉理解能力。


X-SAM成功实现了从“分割万物”到“任意分割”的重要跨越,通过创新的VGS任务、统一架构和训练策略,在保持各项任务顶尖性能的同时,极大地扩展了任务覆盖范围,为图像分割研究和通用视觉理解系统的构建奠定了坚实基础。
GitHub地址:
https://github.com/wanghao9610/X-SAM







