
字节跳动Seed团队今日宣布开源Seed-OSS系列大语言模型,该系列专为长上下文处理、复杂推理、Agent开发及通用场景设计;

最大亮点是将上下文窗口扩展至512K,相当于一次性处理1600页文本,达到业界常见128K上下文的4倍,更是GPT-5上下文窗口(256K)的2倍。
三大模型版本开源,7项性能SOTA
本次开源包含三个版本:
Seed-OSS-36B-Base:基础模型
Seed-OSS-36B-Base-woSyn:无合成数据基础版(专为研究社区设计)
Seed-OSS-36B-Instruct:指令微调模型
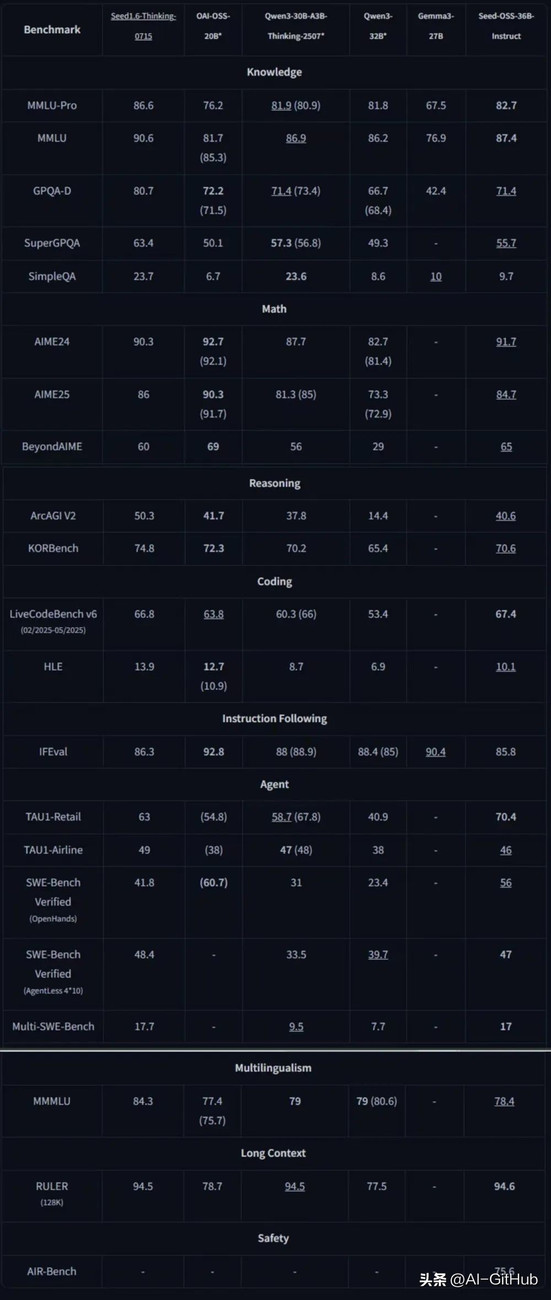
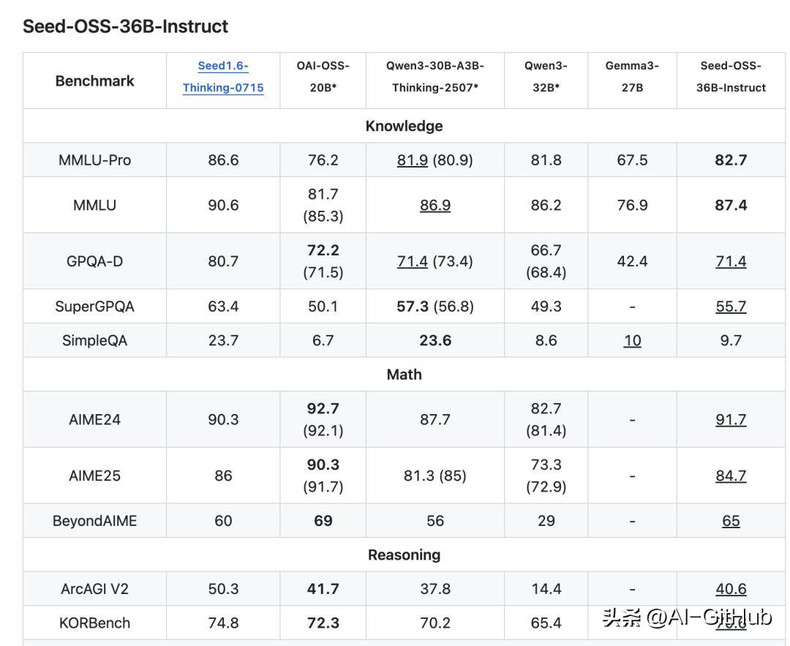
经基准测试验证,Seed-OSS-36B-Instruct在通用知识、Agent任务、编程和长上下文领域斩获7项开源SOTA,整体性能超越Qwen3-32B、Gemma3-27B、gpt-oss-20B等模型,与
Qwen3-30B-A3B-Thinking-2507在多数场景持平。
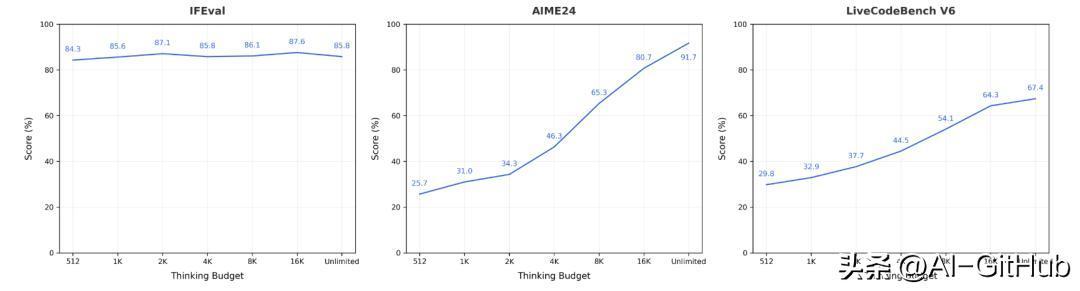
技术突破
原生512K长上下文:通过预训练阶段原生支持(非后期扩展),结合RoPE旋转位置编码+GQA分组查询注意力技术,实现超长文本的高效处理。
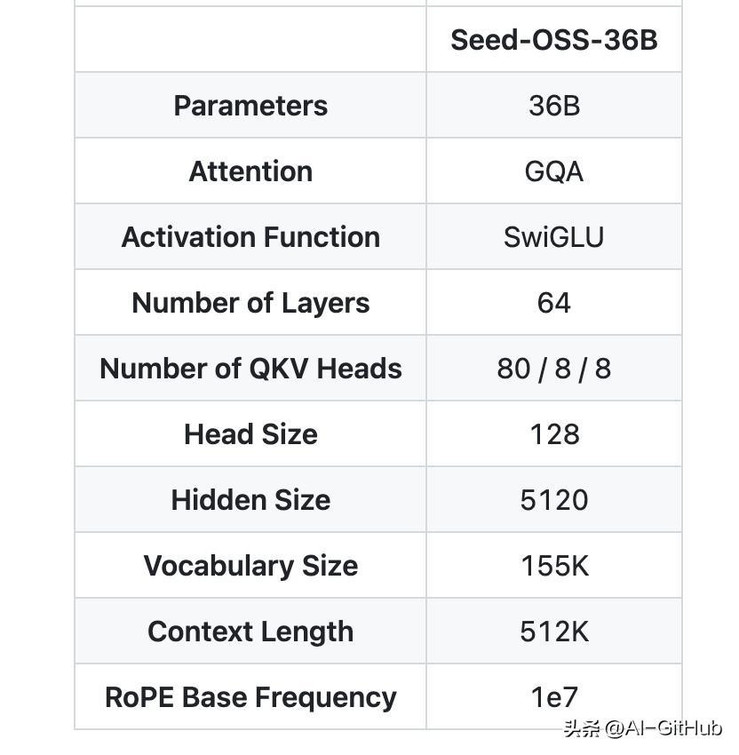
Seed-OSS采用了成熟稳定的设计:360亿参数的稠密模型(不是MoE),使用了RoPE位置编码、GQA注意力机制、RMSNorm归一化和SwiGLU激活函数。整个模型有64层,隐藏层维度5120,词汇表大小155K。
字节Seed团队提供了两个版本的基座模型,一个包含合成指令数据(性能更强),一个不包含(更纯净),为研究社区提供更多选择。
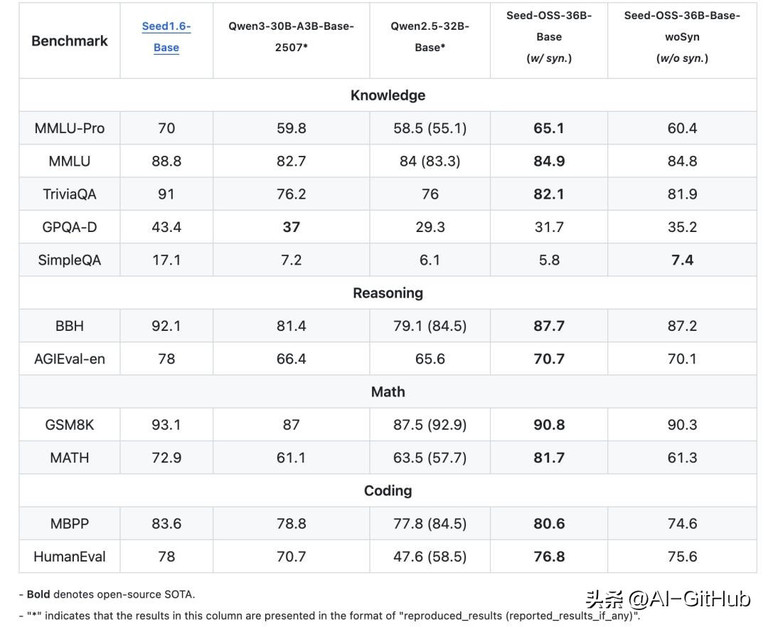
多项基准测试开源SOTA
在知识理解方面,Seed-OSS-36B-Base在MMLU-Pro上达到了65.1分,超过了同等规模的Qwen2.5-32B-Base的58.5分。在TriviaQA上更是拿下了82.1的高分。
推理能力的BBH基准测试得分87.7,直接刷新了开源模型的记录。在数学能力上,GSM8K达到90.8分,MATH的81.7分。
Seed-OSS代码能力同样不俗,HumanEval得分76.8,MBPP达到80.6。
指令微调版本Seed-OSS-36B-Instruct在AIME24数学竞赛题上达到了91.7分的成绩,仅次于OpenAI的OSS-20B。
并且这些成绩是用仅12T token训练出来的,相比之下,很多同规模模型的训练数据量都在15T以上。
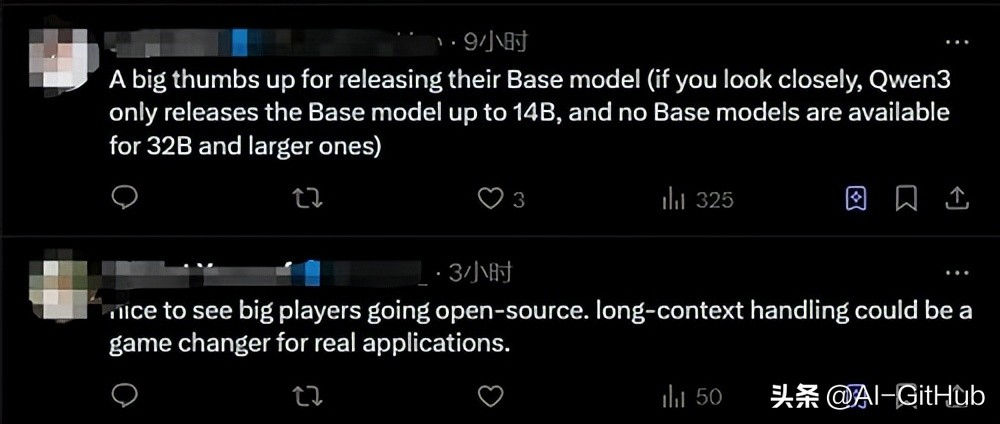
社区反响
Hugging Face工程师Tiezhen Wang评价:“极适合做消融研究”

开发者指出:“36B级基础模型开源稀缺”(对比Qwen3未开源14B以上基础模型)
用户强调:“512K上下文对实际应用价值显著”
随着开源大模型竞争的加剧,字节跳动此次发布展示了中国企业在AI开源领域的强大实力!
开源地址:
https://github.com/ByteDance-Seed/seed-oss
https://huggingface.co/ByteDance-Seed/Seed-OSS-36B-Base
https://huggingface.co/ByteDance-Seed/Seed-OSS-36B-Instruct






