henry 发自 凹非寺
量子位 | 公众号 QbitAI
强化学习+任意一张牌,往往就是王炸。
专注于LLM+RL的科技公司OpenPipe提出全新开源强化学习框架——MCP·RL。
只需一个MCP Server的地址,agent就能自动发现工具、生成任务,通过强化学习在闭环反馈中摸索出最优调用策略。
在实测中,MCP·RL更是在2/3的benchmark上达到或超过SOTA性能,效果直接拉满。
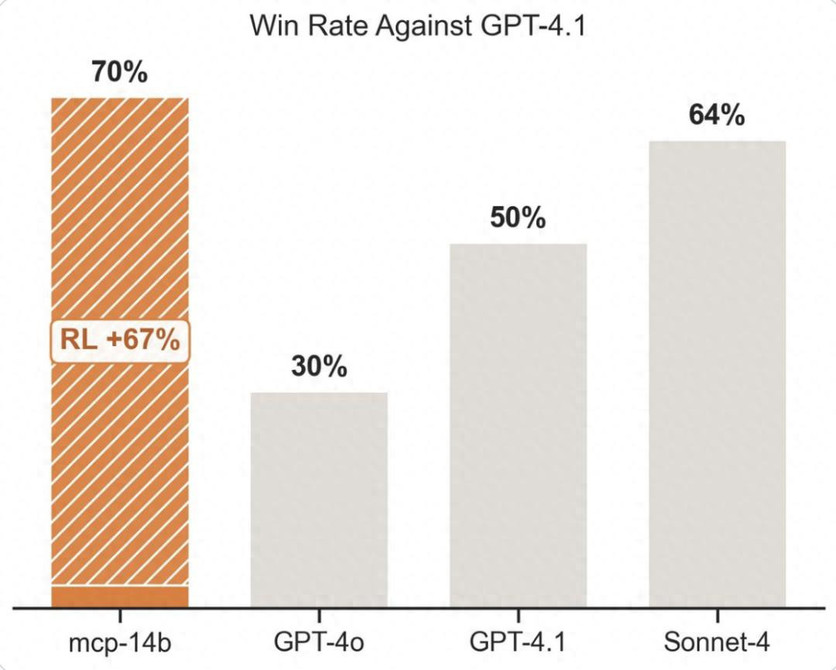
不套公式,在“做中学”,这就是专属RL的power!

MCP·RL的做中学
想明白MCP·RL怎么个“做中学”法,咱们有必要简单过一下传统MCP的流程:
举个例子,假如你想让agent帮自己读邮件、分类、写回复,那么你就得提前设置好整个工作流:
准备邮件数据、注册工具、写prompt规划执行顺序。
此外,你还得设置回退逻辑,以防中途崩掉。
而这只是一个发邮件的例子,功能一多,配置量指数级上升。
最关键的是——你得知道怎么拆任务、调工具、写逻辑。
换句话说,agent就是在做你给他出的完形填空。
而你,我的朋友,要填除了空以外的所有东西。
MCP·RL的提出就是为了解决这一问题。
你只需提供MCP Server地址,不用配置工具、不用写prompt、不用人工标注。
模型就能自己发现工具、自己设计任务、自己实战训练,边跑边学。

简单来说,MCP·RL的训练流程分四步:
- 发现工具:自动连接MCP Server,获取所有可用工具和参数。
- 生成任务:根据工具信息自己“脑补”出一批使用场景,作为训练任务(数据)。
- 实战训练:通过跑任务直接从经验中学习,搭配RULER评估策略,调参优化。
- 测试泛化:用新任务检验策略泛化性,让agent越用越顺手。
总结下来就是:任务场景是什么?AI找;工具怎么用?AI学;流程怎么拆?AI想;效果好不好?AI试。
一位网友精辟的点出了这一转变:
我们曾借助MCP让AI调用工具,而现在是AI反过来利用MCP。

那么,它的效果如何呢?
正如我们开头提到的,MCP·RL在2/3的基准测试中达到SOTA。

而在具体的部署层面,MCP·RL无需标注数据,适用于任何Server,无需定制MCP接口,开箱即用。
One more thing
MCP·RL是科技公司OpenPipe基于强化学习的智能体训练系统(Agent Reinforcement Trainer,ART)的最新项目。
ART是一个开源强化学习框架,其核心思想是让LLM从经验中学习,从而提高agent的可靠性,ART可以将GRPO集成到任何Python应用中。
在此前的实测中,ART(Agent Reinforcement Trainer)对Qwen 2.5-14B进行强化训练,其在一项电子邮件检索任务中表现优于o3,实现了SOTA(state-of-the-art)。

参考链接:
[1]https://x.com/corbtt/status/1953171838382817625
[2]https://github.com/OpenPipe/ART?tab=readme-ov-file#-notebooks
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态







