
智东西
作者 | 李水青
编辑 | 云鹏
智东西8月15日消息,今日晚间,阿里宣布推出首个开源多模态深度研究智能体(Deep Research Agent)——WebWatcher。
市面上的深度研究工具层出不穷,但大多只能围绕文字进行搜索。WebWatcher的核心创新点在于配备了增强的视觉语言推理能力,能够图文结合思考并调用多种工具,从而使研究结果更深入。
比如,当用户要分析一张图片里的信息,WebWatcher能调用 “图片搜索” 找相关图和说明,用 “OCR” 提取图片里的文字,用 “文字搜索” 查背景知识,用 “网页访问” 看具体网页内容,用 “代码工具” 算数据等。
WebWatcher运行案例
实验结果表明,WebWatcher在四个具有挑战性的VQA(视觉问答)基准测试中全面领先于主流的开闭源多模态大模型:
其在Humanity’s Last Exam(HLE)-VL(复杂推理)、BrowseComp-VL(信息检索)、LiveVQA(知识整合)和MMSearch(聚合类信息寻优)等任务测试中均获得高分,超越GPT-4o、Gemini2.5-flash、Qwen2.5-VL-72B、Claude 3.7等模型。
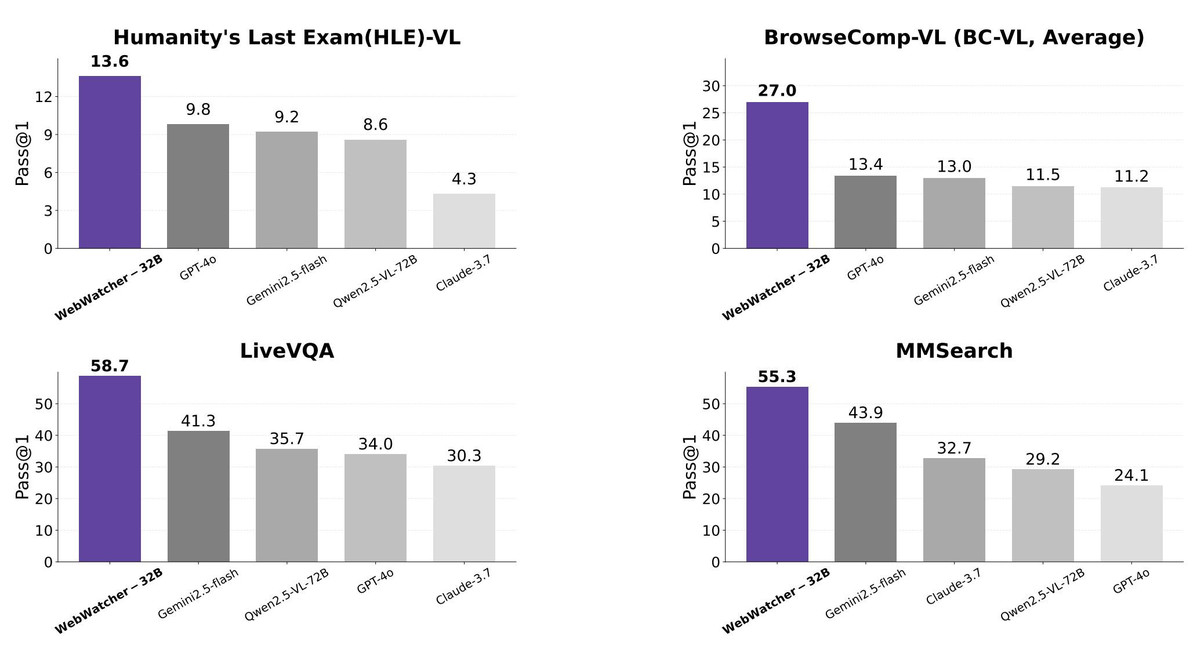
WebWatcher测评成绩
WebWatcher的技术方案覆盖了从数据构建到训练优化的完整链路,核心目标是让多模态Agent在高难度多模态深度研究任务中具备灵活推理和多工具协作能力。整个方法包含三大环节:
1、多模态高难度数据生成:构建具备复杂推理链和信息模糊化的训练数据;
2、高质量推理轨迹构建与后训练:生成贴近真实多工具交互的推理轨迹,并通过监督微调(SFT)完成初步能力对齐。然后利用GRPO在复杂任务环境中进一步提升模型的决策能力与泛化性;
3、高难度基准评测:构建并使用BrowseComp-VL对模型的多模态深度推理能力进行验证。
为了更好地评估WebWatcher的能力,阿里提出了BrowseComp-VL,它是BrowseComp在视觉-语言任务上的扩展版本,设计目标是逼近人类专家的跨模态研究任务难度。
GitHub地址:
https://github.com/Alibaba-NLP/WebAgent
论文地址 :
https://arxiv.org/abs/2508.05748

论文页面截图
结语:突破视觉语言,向深度搜索Agent迈进
自2025年1月推出WebWalker多Agent框架之后,阿里在过去近八个月里加速迭代,陆续推出了原生Agent搜索模型WebDancer、可执行极复杂信息搜索的Agent搜索模型WebSailor、面向信息检索Agent的数据合成方法WebShaper,向通用搜索Agent不断迈进。
本次,阿里最新推出的多模态深度研究智能体WebWatcher,进一步突破视觉语言深度研究Agent的新前沿,其构建的BrowseComp-VL基准、自动化轨迹生成与训练流程,为解决复杂多模态信息检索任务奠定基础,也为未来多模态深度研究Agent发展提供方向。







