
闻乐 发自 凹非寺
量子位 | 公众号 QbitAI
GPT-oss放飞自我了?!居然出现了明显的幻觉行为。
在没有提示词的情况下,消耗超过30000个token凭空想出一个问题,还反复求解了5000多次?!
这是个关于多米诺骨牌的编程问题,简单来说就是:在NxM的网格中先放一个多米诺占掉两个相邻的自由格,剩下的自由格必须刚好能拼成多个2x2的方块。
然后就开始自行暴力求解……

最近,有人好奇GPT-oss的训练数据构成情况如何,所以就进行了一系列测试。
结果发现了一堆GPT-oss的奇怪问题,比如还有:
- 创造不存在的物理学理论
- 拒绝谈论生活琐事
- ……
这到底怎么一回事?
GPT-oss热衷于推理,推理过程中时常伴随语言转换
事情是这样的,有网友对GPT-oss-20b生成的1000万个示例进行了一些分析,结果发现该模型的一些行为非常古怪。
下图是作者使用分类器分析模型掌握编程语言的情况,可以看出该模型的训练数据覆盖了几乎所有常见编程语言,其中Perl的占比尤其高。
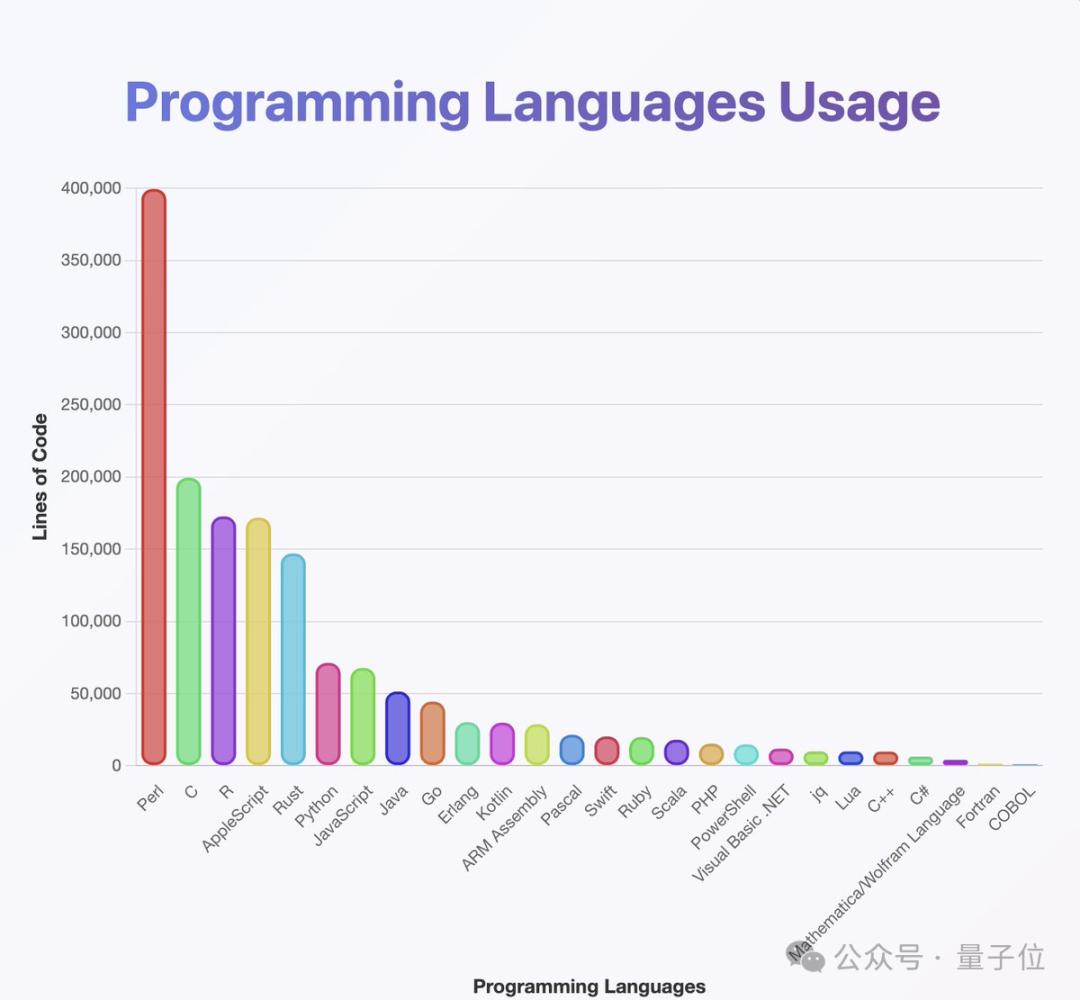
这说明GPT-oss的训练数据很广泛,然而作者据自身经验提出质疑:认为Java和Kotlin的实际占比应该高得多。
而这张关于模型生成内容分布的示意图显示,该模型非常热衷于数学和代码领域,即使不需要任何推理,也会主动进行推理,并且生产的内容几乎都围绕着数学,且大多用英语表达。

并且该模型生成的内容既不像自然网页文本(如日常文章、论坛帖子等偏生活化、随意性的文本),也不同于普通聊天机器人的交互内容(如对话式回应、问答互动)。
于是作者据此推断,该模型并不是为了模拟自然语言或日常对话设计的,而是通过强化学习专门训练,目的是在特定的推理任务基准上进行思考和解题。
更有细心的网友发现下图这种情况的出现可能是由于在训练中对特定方向清除了一大片训练权重。

作者基于平均频率对token进行采样,并用单个token作为提示让模型生成内容。
这时模型会幻觉式生成多米诺骨牌的编程问题,并自发尝试解决,单次过程就消耗了超过30000个token(相当于数万字的文本量)。
问题是:在NxM的网格中,先放置1个2格骨牌,占掉2个相邻自由格,然后看剩下的自由格能不能刚好切成多个不重复的2x2方块(4格),要找出所有满足这个条件的骨牌摆法。
然后GPT-oss-20b就开始暴力求解了。

更特殊的是,在基本没有提示的情况下,这种求解的行为重复发生了5000多次,这说明该任务可能与模型的训练目标深度绑定。
这种极端重复且无提示生成的行为,反映出模型可能在训练中被过度优化于特定推理任务,导致生成内容缺乏自然性,更像一个被训练偏科的工具。
除此之外,作者还发现模型在推理过程中常常伴随着语言转换。
许多推理链起初以英语展开,但会逐渐演变为一种被称为“Neuralese”(可理解为模型特有的、非自然语言的神经层面表达)的状态。
这些推理链会在阿拉伯语、俄语、泰语、韩语、中文和乌克兰语等多种语言间自如切换,之后通常会转回英语(但并非绝对)。

这一现象反映出模型在长文本生成或深度推理时,可能出现语言分布偏移,既包含自然语言间的交替,也存在向非自然语言表达的转变。这暗示了模型可能在训练数据特性或模型内部处理机制方面非常复杂。
模型输出中还出现了特殊伪影(如“OCRV ROOT”)。

作者推测:这些异常符号或表述可能源于训练数据的处理方式—— OpenAI在训练过程中使用了OCR(光学字符识别)技术扫描书籍。
而OCR识别过程中可能出现错误或残留痕迹(如“OCRV ROOT”这类可能的识别偏差),从而导致模型输出中夹杂此类异常内容。
并且作者还表示:模型总爱提马来西亚的聋人数量。
这种看似无关联的内容,或许正是OCR扫描书籍时误读、漏读,或训练数据中特定文本片段被错误收录的结果,这也进一步支撑了他“训练数据经OCR处理且存在瑕疵”的猜想。
值得一提的是,在众多异常表现中,模型也有少量创意输出,比如为挪威剧本撰写草稿。

并且展现出对unicode的熟练使用,但模型在物理领域的表现却不尽如人意。

作者现已将分析使用的相关数据放在Hugging Facce上,可供感兴趣人员进行研究使用。
同时他也给出了一些分析建议:
一是对模型高度冗余的输出进行去重处理,以提高信息的有效性;
二是用自然语言描述不同文本分布的差异,例如对比不同规模模型(如20b与120b模型、LLAMA、GPT-5 等)的输出情况,从而更深入地理解模型的运行机制。
GPT-oss的幻觉率高
实际上,最近不少人都觉得GPT-oss的幻觉情况比较严重。
OpenAI官方公布的数据已经显示,GPT-oss-120b和GPT-oss-20b在基准测试PersonQA中的幻觉率分别达到了49%和53%。
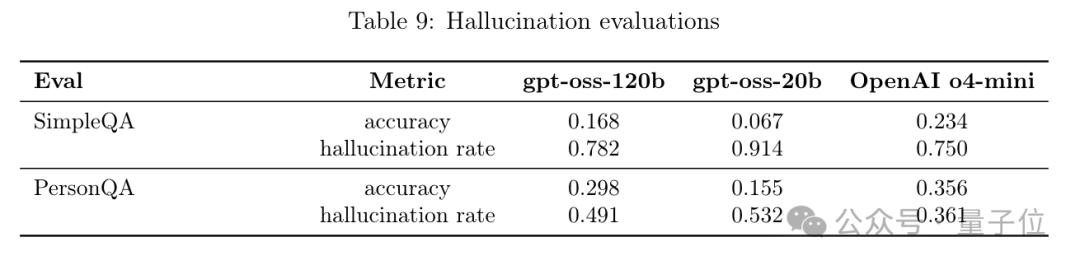
在实际使用和测试中,模型可能出现的问题包括:
GPT-oss-20b花费了2个小时推理“生成一个水平、垂直和对角线都组成单词的3x3字母矩阵”这个问题。就像一只被困在迷宫中的苍蝇,无法停止推理但却迷失了方向……

又比如GPT-oss-20b创造不存在的理论名称:
请解释“量子重力波动理论”在现代物理学中的应用。
实际上并不存在这个理论,仅有“量子引力理论”或“引力波理论”。但GPT-oss-20b还一本正经地说这是一个新兴交叉学科……

还有人说在和它谈论日常生活的琐事时,它偶尔会拒绝谈论,而有的时候会完全崩溃——
用占位符字符删除整个段落。这让它在除数学或者编程外的日常任务中显得很没用。

emmm……不知道你在使用过程中有遇到类似问题吗?欢迎评论区讨论~
相关数据:https://huggingface.co/datasets/jxm/GPT-oss20b-samples
参考链接:
[1]https://x.com/jxmnop/status/1953899426075816164
[2]https://news.ycombinator.com/item?id=44850260
[3]https://x.com/ViepliveeLee/status/1953982402231222763
[4]https://blog.csdn.net/weixin_66401877/article/details/150019363
— 完 —
量子位 QbitAI
关注我们,第一时间获知前沿科技动态







