使用 Claude Code 时,开发者常常面临成本高昂的问题。本文将揭露 Claude Code 成本浪费的原因,并提供实用的省钱攻略,助你高效利用这一编程工具。
用Claude Code等终端代理编程工具,就是在体验“冰与火之歌”:
一边惊叹于 Claude Code 的强大——作为Claude亲儿子,能帮你分析代码库、修复 Bug、甚至独立完成开发,效率拉爆Cursor几条街;
另一边又对着账单心惊胆战,感觉还没怎么用,几千万的 Token 就被干爆了。
甚至有开发者,一次 40,000 个输入 Token 的请求,最终只为了生成 30 个 Token 的有效输出 。
更有人分析发现,超过80%的成本,可能都被浪费在了完全无关的臃肿上下文上!
随着 Claude Code 这类“终端编程代理”的兴起,学会计算和管理 Token 成本,已经是一项必备的基本功了。
如果你还对这背后的“成本黑洞”一头雾水,那么这篇文章就是为你准备的保姆级省钱攻略。
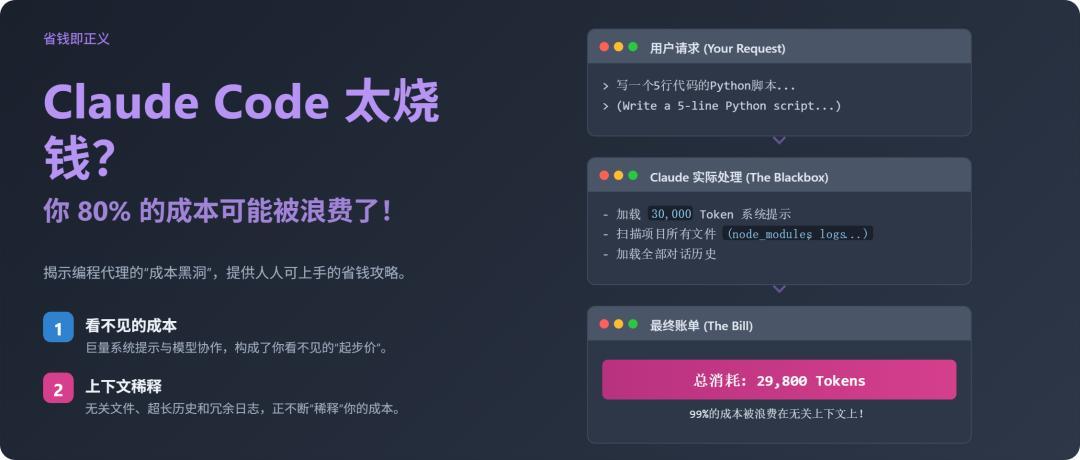
1. 解密黑盒:你的钱是怎么被“稀释”的?
要学会省钱,首先得知道钱是怎么花出去的。
Claude Code 的 Token 计算机制,比普通聊天机器人复杂得多,其核心成本问题可以归结为一个概念:上下文稀释 (Context Dilution) 。
上下文稀释率 = 不相关 Token / 总 Token。这个比率越高,意味着你的钱花得越冤。
这些不相关的 Token,主要来自以下几个方面:
1.1 看不见的成本:庞大的“系统提示”
在你敲下任何字符前,Claude Code 已自动加载一个可能高达 20,000 到 30,000 个 Token 的系统提示 (System Prompt) 。这是你每次请求的固定“起步价”,也是小任务产生大账单的根本原因。案例:一位开发者修复一个 Bug,代码 diff 仅 51行 ,却花费了 $0.73 美元 。
另一位用户让它写5行 Python 脚本,消耗了近 3万 Token 。原因分析:固定加载的“系统提示” + 对整个项目文件的无差别扫描,导致99%的 Token 都花在了与这51行代码无关的内容上。
1.2 Opus 4.1 = Token刺客
一次请求的背后,是 Haiku(小模型) 和 Sonnet/Opus(大模型) 的协同工作。Haiku 处理杂活,大模型负责核心推理。这种分工虽能优化成本,但也意味着计费结构更复杂。
案例:有用户反馈,在处理一个“纯屎山”项目时,直接升级到 $100/月的 Opus 模型 订阅,虽然物超所值,但也体验了15分钟烧掉50%额度的刺激。原因分析:模型性能和价格直接挂钩。Opus 虽强,但 Token 价格是 Sonnet 的数倍。
$20/月的 Pro 订阅(使用 Sonnet)对绝大多数日常开发已绰绰有余,甚至“比 Cursor MAX 更 MAX”。
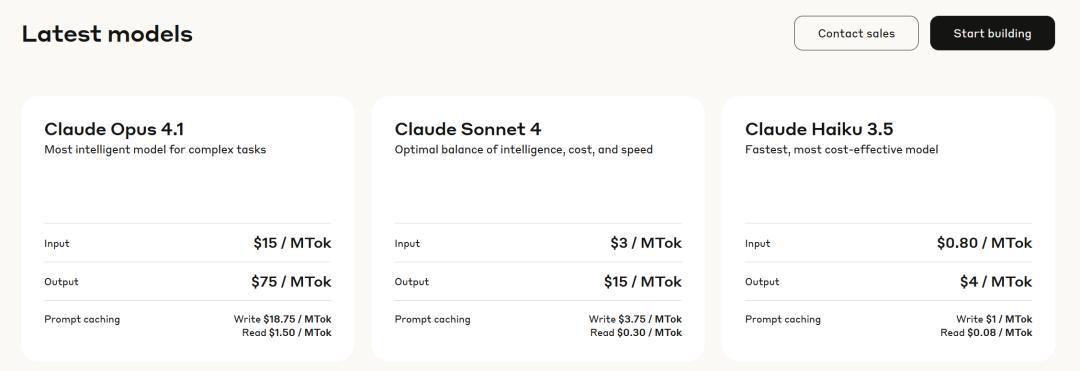
模型性能与特点典型场景Opus最高智能,顶尖推理能力复杂的系统设计、屎山项目重构、前沿研发Sonnet性能与成本的完美平衡日常开发、代码生成、大部分调试任务Haiku速度最快,成本最低简单的脚本编写、格式化、终端命令
有同学用我们服务的时候,切换到了Opus 4.1,一下子就干满限额了,但编程效果反而没明显提升。
幸好每日限额救了他,要不然一天直接把一个月额度干没了。
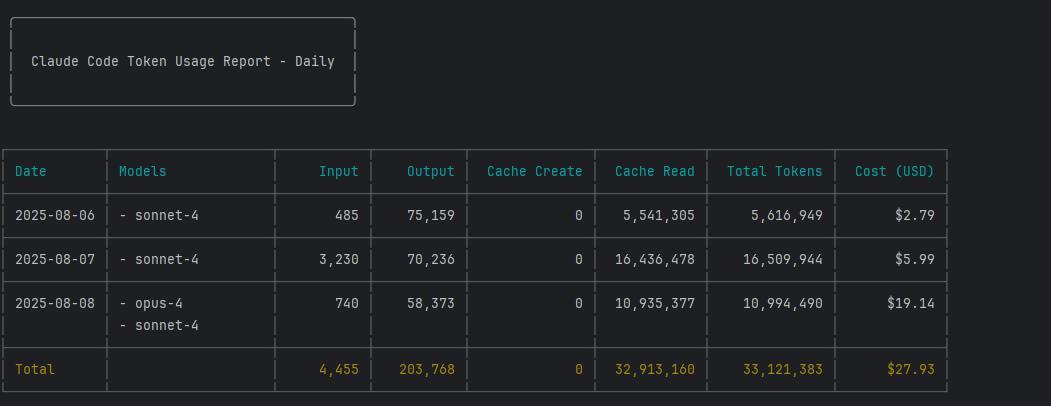
从表格看下来,我们服务还挺划算的,等于26元 rmb 用了官方27美金。
详见文末。
1.3 滚雪球的“上下文窗口”
为了“记住”历史,Claude 必须在每次请求时重新加载全部对话和文件内容 。对话越长,这个“雪球”就滚得越大,成本呈指数级增长。案例:开发者在做一个复杂功能时,与 Claude Code 进行了数十轮的迭代调试。
他发现越到后面,Claude 响应越慢,而且自己的订阅额度很快就用完了。原因分析:这正是“上下文窗口”滚雪球的恶果。每一轮调试,之前的全部历史都会被加载,不仅成本飙升,当上下文接近极限时,模型性能还会下降,开始输出“蠢”内容,造成恶性循环。
其实饼干哥哥也被背刺过,是在Claude Code里用Qwen3,大模型拉胯,一直在循环报错
刚好这会我人离开了,回来后就是80元账单,和留着bug没解决问题的烂摊子
我还专门吐槽过,从评论区看很多受害者:一觉醒来,天塌了, qwen3 循环报错,导致欠费一大堆,关键任务还没完成
1.4 冗余信息的四大“污染源”
完整文件转储:你只想改一行,它却读了整个文件。超长聊天历史:几个小时前的对话还在占用宝贵的上下文。原始文档粘贴:格式混乱的 PDF、Word 文档被直接丢入。海量日志文件:极端情况下,它甚至会去读取 node_modules、日志和二进制文件!
2. 省钱即正义:从入门到大师的三层省钱心法
既然我们知道了成本黑洞在哪,就可以对症下药。
第一层:基础篇(人人必会)
1. 主动压缩:Claude 会在上下文剩余20%时自动压缩,但那时基本为时已晚。要养成手动提前使用 /compact 命令 的好习惯。
2. 一事一议,用完即焚:为每个独立任务多开几个终端窗口 。任务一旦完成,立刻关闭窗口 (/clear 也行)。保持任务的原子性,防止不相关的上下文污染后续对话。
3. 杀鸡焉用牛刀,明智选择模型:日常开发坚决使用 Sonnet。只有在啃硬骨头时,才请出 Opus 这尊“大佛”。
可以通过 /model sonnet的命令切换当前使用的模型。
4. 定期查账,心里有数:多用 /cost 命令检查 Token 消费情况。
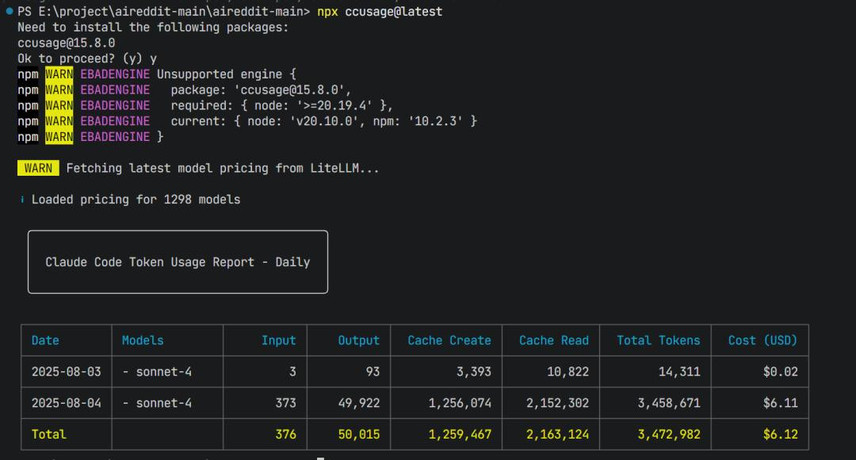
还可以通过这个命令看看自己烧了多少Token、花了多少钱?npx ccusage@latest
5. 编辑代替追问:别一错就再加一句“你刚才错了,试试这个”,直接编辑原始提示,避免记住所有历史错误。
第二层:工作流优化(善用工具组合)
1. 划定禁区,善用 .gitignore:Claude Code 会尊重你项目中的 .gitignore 文件。把 node_modules、日志、构建产物等无关文件夹都加进去,能从源头上阻止它进行无效扫描。
2. 文档驱动,让AI先做计划:不要随意对话。先让 Claude Code 生成一个任务清单(TODO List) 。然后你再引导它逐一完成。这种“先规划,后执行”的模式,能让每一次交互都更精准。这也是我之前推荐的AI编程工作流:发现个用 Claude Code 的高效…
3. 管理记忆:运行 /memory 命令可以查看和编辑 Claude “记住”了哪些核心信息。对于版本号、关键工具链等固定内容,在这里一次性修正,就不用在对话中反复纠错了。
4. 借力打力,混合工具流:让其他工具干脏活累活!比如,像饼干哥哥一样,搭配Trae,3美金/月,用来做文档、梳理等,例如为项目自动生成初步的文档说明,再让 Claude Code 基于这些精准的说明进行具体的代码实现。
但不建议用Trae来跑复杂任务,我最近在搭建自己的品牌官方,用Trae折腾了几天,审美不行、多语言报错等等,后来用Claude Code给它擦屁股,20分钟就解决了。
5. 随时存档,git commit 是你的后悔药:每次 Claude 完成一个独立的小任务,立刻 git commit 保存当前状态 。万一后续出现 Bug,可以轻松回溯,避免大量的返工和 Token 浪费。
第三层:高阶篇(极限省钱大师)
1. 强制约束,给 Claude 上“紧箍咒”:这是最高级的技巧。在项目配置或初始提示中,用规则强制约束 Claude 的行为 。
例如:禁止读取:明确禁止读取日志文件、锁文件、二进制文件等。禁用工具:除非明确要求,否则禁用某些工具的使用权限。设置预算:设定 Token 预算、延迟目标、每次获取最大行数等硬性限制。
2. 精简输入,只喂“干货”:不要给 Claude 整个文件,只给它预期会更改的代码,外加周边 20-40 行的相关上下文 。
用5点总结替代长篇大论的文档。传递文件路径而非原始内容,让模型按需请求。这样做,同样任务的 Token 消耗能减少80%以上!
在做跨对话、甚至跨AI的时候,可以用我之前分享的这个提示词,提前把内容做压缩总结:分享一个 AI 对话总结提示词,可用于跨…
本文由人人都是产品经理作者【饼干哥哥】,微信公众号:【饼干哥哥AGI】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。







