
本论文的主要作者来自腾讯混元 AI 数字人团队 (Tencent Hunyuan AI Digital Human)。该团队致力于打造「有智商、有情商、有温度的数字人」,旨在为用户提供高度拟人、可信赖的数字伙伴,进而实现富有温度与信任的情感交互。
自主智能体(Agents)正朝着能够处理复杂长程任务(Long-Horizon Tasks)的通用智能(AGI)迈进,但许多研究者发现了一个尴尬的现实:很多智能体虽然能完成任务,却像个「只会蒙答案的学生」,其成功往往依赖于运气和低效的试错,而非真正高效、可泛化的推理能力。一旦环境稍作改变,它们便漏洞百出。
这种「结果正确,但过程混乱」的现象,是当前长程智能体(Long-Horizon Agents)强化学习(RL)范式的一大瓶颈。智能体在探索中,只因最终能完成任务便获得奖励,而其间大量的冗余操作、无效探索,甚至错误的推理路径,都被无意中 「强化」 和固化。这导致了两个核心难题:
1.低效探索难题:智能体容易陷入「无效内卷」,反复尝试无意义的动作,训练成本高,推理效率低下。
2.泛化脆弱难题:靠「蒙对」学会的策略缺乏逻辑基础,在新任务面前不堪一击,难以实现真正的鲁棒性。
如何让智能体不仅「知其然」,更能「知其所以然」?
面对这些难题,腾讯混元 AI 数字人团队提出了 RLVMR (Reinforcement Learning with Verifiable Meta-Reasoning Rewards) 框架。这项工作开创性地将认知科学中的「元认知」(即 「思考自己的思考」)理论引入 RL,通过奖励「好的思考过程」而非仅仅奖励「好的结果」,首次实现了对智能体推理过程的端到端强化学习,成功解决了长程任务中的低效探索与泛化难题。

- 论文地址: [2507.22844] RLVMR: Reinforcement Learning with Verifiable Meta-Reasoning Rewards for Robust Long-Horizon Agents
- 项目代码: digitalhuman/RLVMR at main・Tencent/digitalhuman・GitHub
RLVMR:如何教会智能体「思考」,而不仅是「做事」?
传统方法要么依赖僵化的专家数据(SFT),要么依赖稀疏的结果奖励(RL),都无法有效塑造智能体高质量的「思维习惯」。RLVMR 的破局点在于:为智能体的「思考过程」本身,设计一套可验证、可优化的奖励机制。
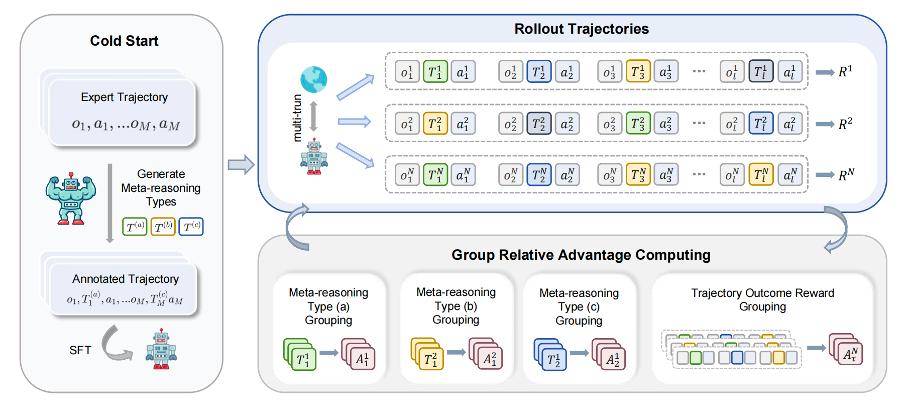
1. 智能体学会「三思而后行」:引入元推理状态
RLVMR 赋予智能体「自我意识」的能力。在行动前,智能体需要先思考并给自己贴上一个「元推理标签」,明确自己当前处于哪个认知阶段:
- 规划(Planning): 我准备做什么?计划是什么?
- 探索(Exploring):我正在执行计划,探索方案。
- 反思(Reflecting):计划出错了?我需要纠正什么?
这套机制让智能体的「内心戏」变得明确、可追踪,为奖励其「优质思考」提供了抓手。
2. 奖励「好思路」,惩罚「坏习惯」:可验证的过程奖励
光有标签还不够,RLVMR 设计了一套轻量级的验证规则,实时评估智能体的思考质量,并给予即时奖励:
- 奖励高效思考:当智能体在「反思」后成功纠错,或制定出有效「规划」时,给予正向奖励。
- 惩罚低效行为:当智能体陷入无意义的动作循环或重复犯错时,给予负向奖励。
这种「过程奖励」机制,像一位贴身教练,不断引导智能体优化其思考与决策路径,从根本上杜绝「瞎蒙」行为。
3. 从「结果导向」到「过程与结果并重」
RLVMR 将「过程奖励」与最终的「任务成功奖励」相结合,通过策略梯度方法进行端到端优化。这使得智能体在追求最终目标的同时,必须学会如何更聪明、更高效地达成目标。
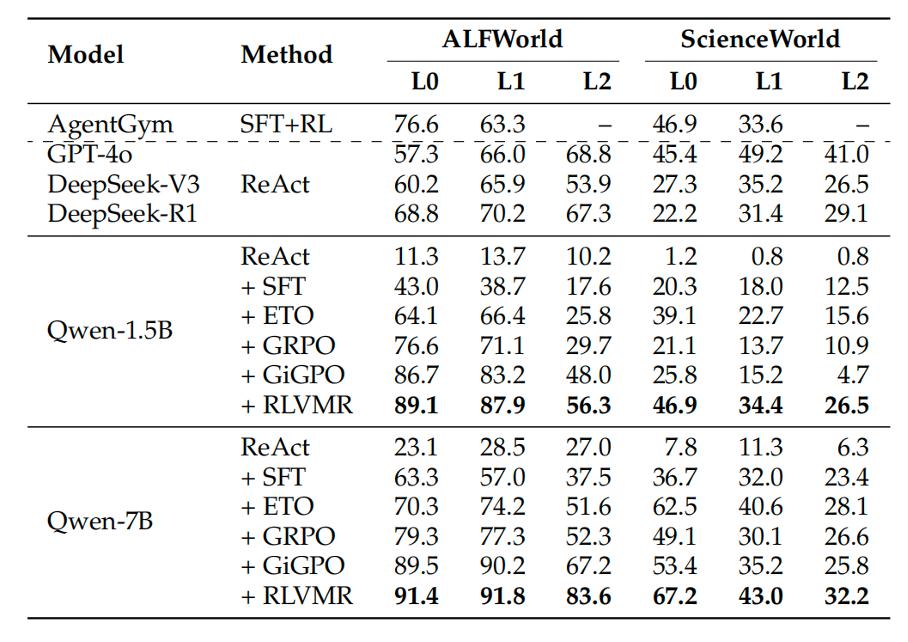
核心实验成果:7B 模型比肩「巨头旗舰」
在极具挑战性的 ALFWorld 和 ScienceWorld 两大长程任务基准上,RLVMR 展现了统治级的性能。经过 RLVMR 训练的 7B 模型,在难度最高、从未见过的任务(L2 泛化等级)上,成功率高达 83.6%,不仅远超此前所有 SOTA 模型,更证明了其强大的泛化能力。
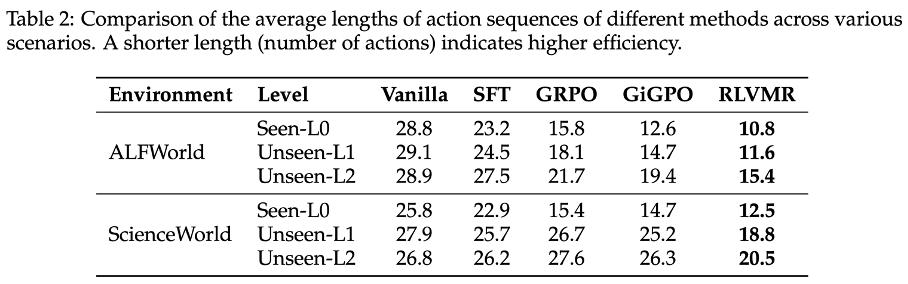
此外,我们的方法训练出的智能体更「聪明」,解决任务的路径更直接,在 ALFWorld 和 ScienceWorld 的 L2 复杂环境中,所需动作数最高减少 28.1%。此外,训练过程本身也告别了「反复横跳」式的低效学习,收敛速度更快、策略更稳定,显著缓解了无效探索问题。
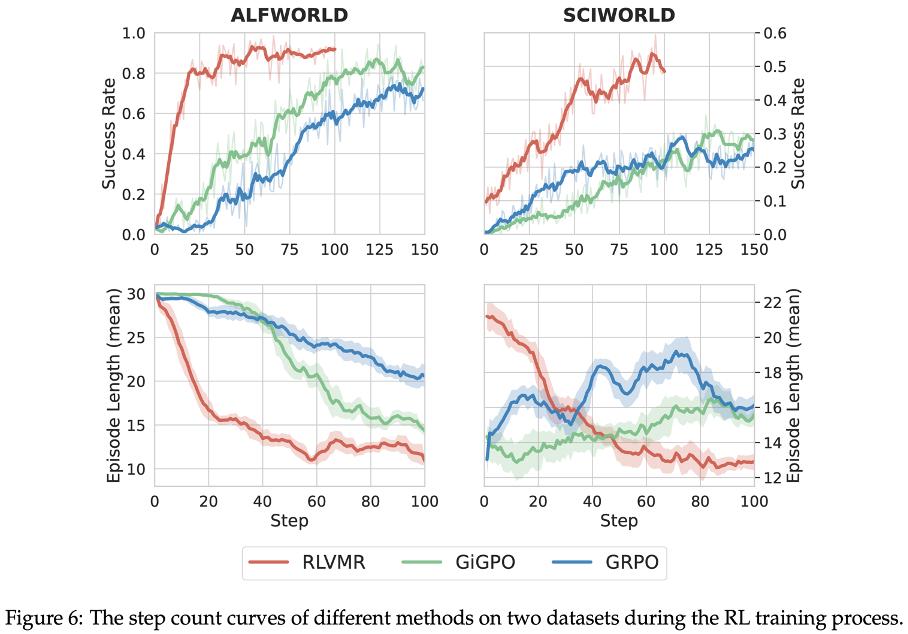
超越分数:RLVMR 实验中的深度洞察
洞察一:智能体学会「反思」,告别「无效内卷」
传统 RL 智能体像一个埋头刷题但从不复盘的学生,容易在错误路径上反复挣扎。RLVMR 的核心贡献在于教会了智能体「反思」(Reflecting)。
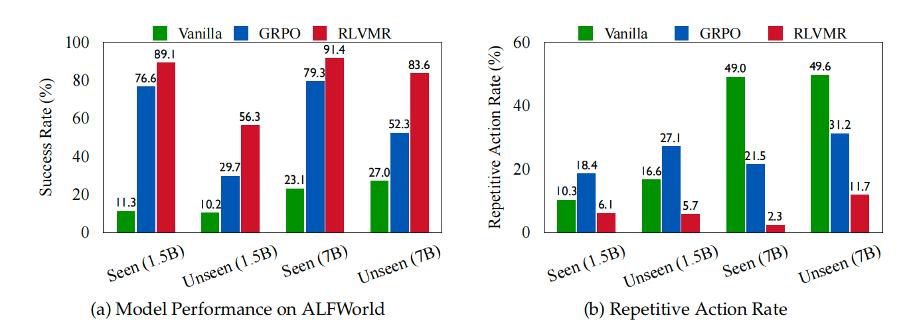
实验数据显示,引入「反思」机制后,智能体在遇到困难时,不再是盲目重试,而是能够主动识别问题、调整策略。这正是其重复动作率大幅降低、任务成功率飙升的根本原因。它揭示了一个关键点:对于复杂任务,教会智能体如何从失败中学习,比单纯「喂」给它成功的经验更重要。
洞察二:好的推理习惯,是泛化能力的基石
为什么 RLVMR 在未见任务上表现如此出色?
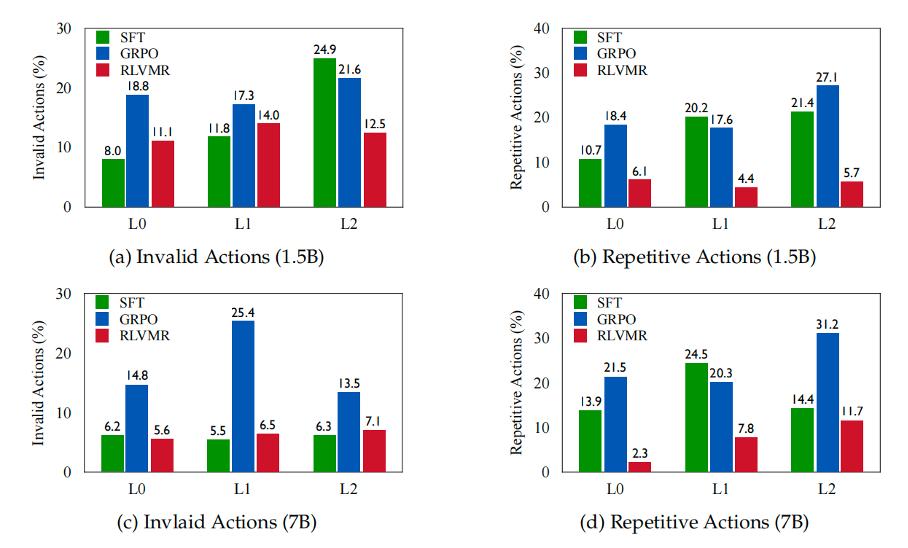
我们发现,通过奖励「好的思考过程」,RLVMR 帮助智能体建立了一套通用的、不依赖于特定任务的「元问题解决框架」(如何规划、如何探索、如何反思)。当面对新环境(L2)时,智能体调用的不再是某个僵化的「解题模板」,而是这套灵活的「思维方法论」。
这证实了一个重要猜想:真正的泛化能力,源自于对问题解决过程的深刻理解,而非对问题答案的机械记忆。 RLVMR 正是通往这条道路的有效路径。
洞察三:先 「冷启动」 再 「强化」—— 智能体的成长阶梯设计
RLVMR 采用了「冷启动 SFT + 强化学习 RL」的两阶段训练流程。这并非简单的流程拼接,而是一种符合认知规律的「成长曲线」设计。
- 冷启动阶段(SFT): 如同基础教育,让智能体先通过模仿学习,快速掌握「规划」「反思」等元推理概念的基本表达方式。
- 强化学习阶段(RL): 如同进入社会实践,让智能体在真实环境中自由探索,通过「过程奖励」的不断反馈,将学到的概念内化为真正的能力。
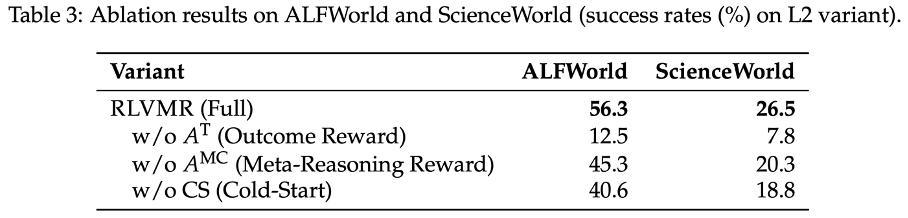
这一策略启示我们:在训练高级智能体时,「先教会它如何思考,再放手让它去犯错成长」,可能是比单一训练范式更高效的路径。
总结与展望
RLVMR 的提出,为智能体训练带来了从「结果导向」到「过程导向」的范式革新。它证明了,通过对智能体「思考过程」的直接建模与奖励,我们能够有效破解长程任务中的「低效探索」与「泛化脆弱」两大难题。
我们对 AGI 的终极期待,是一个能够独立思考、理性决策的伙伴,而不是一个只会寻找捷径的「做题家」。RLVMR 的工作,正是鼓励大模型从偶然涌现的能力,走向特定思维模式的强化,为构建更鲁棒、更高效、更可解释的通用智能体迈出了坚实的一步。
这项研究不仅为长程智能体训练提供了新思路,也为我们探索能真正理解世界、应对未知的下一代 AI 带来了新的曙光。







