机器之心报道
编辑:Youli
具身智能「大脑」,更准确地,以「世界模型」为内核的具身智能「大脑」会成为 AI 下一阶段竞争焦点吗?
上世纪九十年代,「世界模型」思想雏形初现,之后几十年被不断强化、延伸,直到 ChatGPT 引爆 AI 新浪潮、Sora 问世、大模型落地成主流、具身智能迎来新纪元……「世界模型」或是通往「类人智能」的解法被视为新的业界共识。
与此同时,在产业界,如果说 2025 年上半年 AI 发展主要围绕 Agent 元年、人形机器人「量产」等关键词展开,那下半年,具身智能「大脑」开始成为整个行业乃至全球 AI 领域的焦点。
于是,当世界模型技术研究曲线与具身智能产业发展路径在某一时刻交汇时,一场围绕具身智能「大脑」的争夺战拉开了序幕。
谷歌推出具身智能 RT-2 模型;AI 教母李飞飞聚焦具身智能创业,认为世界模型是 AI 实现「通用智能」关键一步。
国内,今年 3 月,智源研究院发布开源具身大脑 RoboBrain;6 月,华为云发布 CloudRobo 具身智能平台;7 月,字节跳动 Seed 团队发布通用机器人模型 GR-3;7 月底,京东发布附身智能品牌「JoyInside」;7 月底,商汤科技推出「悟能」具身智能平台;8 月初,腾讯发布 Tairos 具身智能开放平台……
当具身智能的技术演进路线还未收敛,各厂商都在基于以往的技术沉淀,沿着不同路线,朝着 AGI 狂奔。
商汤作为其中一家,优势在于做计算机视觉起家(当前具身智能主流技术路线之一)、多模态大模型已经在多种机器人身上打磨过、在智能驾驶领域沉淀多年(世界模型早期落地应用的场景之一)、有大装置提供强大的端侧和云侧算力支持……
因此,商汤想通过「悟能」具身智能平台,「将多年的沉淀与积累,赋能给整个行业。」商汤科技联合创始人、执行董事、CTO 王晓刚说道。

在王晓刚看来,当前具身智能领域发展迅速,尤其是大模型的到来让大家有了更多想象空间。可与此同时,数据匮乏、采集难、无法批量规模化生产、难以泛化等问题也成为具身智能通用化道路上的绊脚石。
但是当大量做计算机视觉的人进入这一领域就变得不一样了。计算机视觉擅长的是分析客观世界的人、物、场,并进行重建复现,包括世界模型的学习,都会给这个领域带来新动能。
而商汤不仅在计算机视觉领域积累深厚,也早早开始探索世界模型的落地。去年 11 月商汤发布「开悟」世界模型,将其应用在智能汽车上。王晓刚认为,汽车本质上也是一个机器人,从端到端 VLA 到环境计算,都是在引领具身智能的发展,「我们先在汽车的环境里进行探索和尝试,然后扩展到其他方向。」
而这个方向,当下就是具身智能。
基于「开悟」世界模型衍生出来的「悟能」具身智能平台,包含着商汤过去积累的 10 万 3D 资产,提供第一视角、第三视角的视频生成,支持具身智能进行多视角学习,能够保持长达 150s 的时空一致。另外,基于自动驾驶和人机交互流式多模态大模型产生的导航、人机交互等能力也都一并赋能给「悟能」具身智能平台,从而推动具身智能加快从数字空间迈向真实物理世界。
近期,机器之心与商汤科技联合创始人、执行董事、CTO 王晓刚聊了聊,以下为对话实录,在不改变原意的基础上进行了调整:
具身智能来势汹汹,但数据缺乏是「硬伤」
提问:今年被称为「人形机器人量产元年」,在你看来,这主要源于哪些方面,比如技术突破?
王晓刚:我觉得大家看好这个方向主要有几个原因。首先,近几年硬件本体、运控进步很快,有了非常好的基础,像机器人跳舞、翻跟斗、搏击等逐渐走向成熟,但更重要的是,AI 大模型给大家带来了更多想象空间。机器人原本是在特定场景完成单一任务做得比较好,但现在大家期待它有更多通用性,无论是在家庭环境还是生产线上,当任务发生变化的时候它能够像人一样灵活应对。
其中大模型带来的技术突破主要包括三方面 —— 导航、人机交互,以及 VLA 这种端到端复杂操作,给大家提供了新的想象空间。
提问:具体是如何体现的?
王晓刚:导航,现在随着自动驾驶技术不断成熟,让机器人陪伴、巡检,甚至配送等方面的功能变得更好。
人机交互,比如多模态大模型带来的全新交互方式,当然更多的是像 VLA 这种比较复杂的操作带来的想象空间。
我们常常思考智能分几个层次?智能从哪里来?最早大家通过标注数据,采集大量图像、声音,这些都是客观世界的记录,但是依靠人类的感知,之后进行标注,把人对世界的理解通过标注的方式注入智能。
第二个阶段,ChatGPT 出现后通过分析语言进行,语言本身就是人类行为,这是另外一个层次。
但更高的一个层次是人定义的这些规则,比如下围棋,把规则定义好了以后,AlphaGo 机器人在互相博弈过程中产生很多智能。
如今无论是自动驾驶还是机器人领域,有一个很重要的模型 ——「世界模型」,世界模型本身是把物理规律、交通法则这些东西学到以后(去做预测、规划)。人更高层的智能就是定义这些规则,之后自动驾驶或是机器人在世界模型里面依据这些规则进行交互,自动就能产生更多的智能。
提问:在取得进展的同时,具身智能领域在通往更为通用的场景时也面临一些困难与挑战,在你看来有哪些局限性?
王晓刚:问题也是多方面的,比如硬件质量,机器人是一个高度复杂的系统,任何一个零部件出现问题,都会给整个系统带来质量方面的影响,因为它要与物理世界进行交互,交互过程中会进行碰撞。这是它走向大规模量产所面临的硬件问题。
但最核心的还是数据问题,目前具身智能没有办法进行批量规模化的数据生产。虽然有各种数据生产手段,但机器人类型多样,硬件传感器配置千差万别,而且机器人本身数量相对较少,所以整体来看,这一个机器人上采集到的数据难以推广到另外一个机器人上。
另外采集方式,比如智能汽车,开车过程实际就是生产过程,自然而然产生了这些数据,而机器人采集的数据不是在生产过程中,是通过遥操作,人在背后控制机器人刻意采集数据,成本也非常高。
当然也有用仿真得到的数据,但与真实数据之间 gap 较大,因为仿真的技术路线积累还是传统办法,与现实差距大。
我们期待这些 3D 建模与世界模型相结合,通过对物理世界更深入的理解,带来新的思路。尤其是有大量做计算机视觉的人开始进入这个领域,计算机视觉领域擅长的是分析客观世界的人、物、场 3D 模型、环境,并进行重建复现,包括世界模型的学习,都能够给这个领域带来新的动能。
具身智能世界模型<人、物、场>构建4D真实世界
提问:现在有些机器人演示的时候手抖得厉害,这是因为缺乏数据或是训练不到位吗?
王晓刚:这是运控问题,主要是通过小脑对它进行控制,另外大脑也要分析怎么能进行这些行为。
比如 VLA 给出指令,应该往哪个方向运动,而机械手或肢体怎么能够通过局部控制这些关节,达到预测的运动轨迹。这涉及到两个问题,一是自己本身运动的时候要把握比较好,另外预测的运动轨迹得适合机器人硬件本体的运动,如果给它设计一个路线,它走起来很别扭就不行,这就要求大脑 VLA 的预测要与底层的运控有一个比较好的结合。
这也不容易,机器人走路的运控要让它走得好,很多时候也需要通过强化学习去适用不同的环境和地形。为什么有些演示 demo 可以做到,主要是因为它是针对特定的场景调得比较好,换一些通用场景就不行,一旦涉及到规模化,不光大脑要通用,小脑也需要做到通用,否则需要一堆技术售后人员到各个场景里面做调整。
世界模型,加快 AI 从数字空间迈进物理世界
提问:你刚才提到汽车,认为它是从 AI 迈向具身智能的一个关键步骤,那你觉得现在的自动驾驶处于怎样的阶段,具备进一步向具身智能发展的条件吗?
王晓刚:现在自动驾驶领域还处于技术红利期,基本上每年它的整个体系架构都朝新的方向进一步迭代。比如 2023 年端到端的自动驾驶概念兴起,那时候还很依赖高精度地图,现在已经进化到无图的端到端自动驾驶,技术已经比较成熟。
但因为端到端技术还是对人类行为的模仿,是类人的,所以对数据的依赖比较高,所以当下世界模型已经形成一个行业共识。比如去年 11 月我们发布了「开悟」世界模型,今年,像华为、小鹏等也都在发力世界模型。
有了世界模型以后,一是可以提供大量数据,另外它可以在仿真环境里做很多强化学习的尝试,因为世界模型能做到举一反三、反十、反一百。比如今天遇到一个自动驾驶没有解决好的问题场景,基于这个场景首先对它进行重建,然后就可以改变天气情况、光线、道路情况、各种车型、速度、距离远近等,这几个维度拟相乘能够产生大量类似的场景和视频,从而把这一类问题全都解决干净,极大地降低了数据采集成本。
提问:那是否具备进一步向具身智能发展的条件?
王晓刚:当然,今年我们看到,因为有了端到端,激发人们在机器人领域应用 VLA;因为有了世界模型,具身智能也进入这一领域。另外就是座舱里面的人机交互,现有的是硬件设备加上 APP,将来全新的人机交互叫作「环境计算」,AI 就像空气一样在人们的周围,不需要打开特定的 APP,它主动会找到你,里面核心点就是有计算芯片、有各种传感器还有模型,这不就是汽车中一个非常典型的环境?
车内外有这么多的传感器观察、记录车内外的各种状态、各种活动、人的对话等行为,还要有记忆,了解、知道你的需求,那当你需要的时候就能够主动提供 AI 相关服务,它本质上就是一个机器人。从这个层面来看,它是一个很好的环境计算载体。
所以,从端到端 VLA 到环境计算,汽车都是在引领具身智能的发展,我们最先可能是在汽车的环境里进行索和尝试,然后扩展到其他方向。
提问:说到世界模型,各大厂商都在陆续发布,那在你看来商汤的「开悟」世界模型有哪些技术优势?
王晓刚:首先,「开悟」世界模型的最新进展是不仅覆盖了汽车领域,而且也覆盖了具身智能,同时提供这两个平台。
世界模型的核心是要学到最高层的智能,包括物理规律、交通法则、什么是好的行为和开车的体验等,其中比较关键的几点分别是:
第一,时空一致性。2024 年年初 Sora 生成视频,但它不是针对特定自动驾驶场景,而且产生视频最难的地方在于如何保证时间上的连续,因为生成一幅图像很容易,但是生成一个视频,大家会看到帧与帧之间是不是不连续的,存在各种抖动、跳变。自动驾驶领域难度更高,要求 11 个摄像头保持时空一致性,一个摄像头看到的东西与另外一个摄像头看到的东西,在空间物理上需要一致,不能在这个摄像头看到一条实线,另外的摄像头看的是一条虚线。
另外时间上,我们能够做到 150 秒,时间越长,包含的交通行为更复杂,能够把一些更复杂的博弈体现出来。
第二,内容可编辑,场景生成可控。刚才提到世界模型能够做到举一反三、反十、反一百,就是因为能够任意编辑里面的各种元素,换天气、换光线。
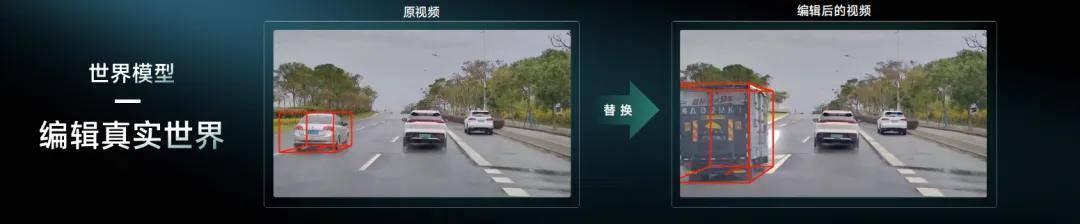
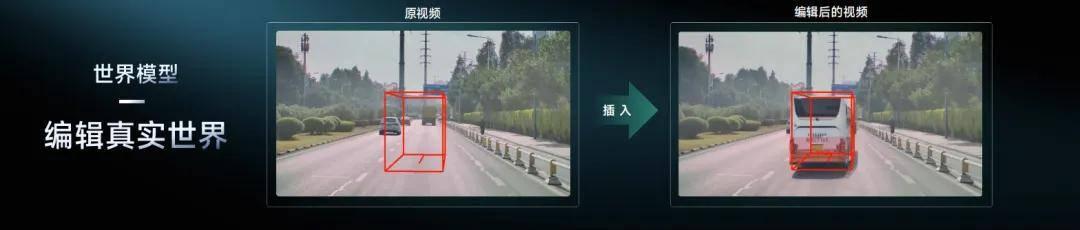
第三,反应速度实时。实时性体现了成本,场景生成实际上是在用 GPU 算力来置换,实时性越高,算力越节省,花的钱越少。另外做到实时性,还可以对它进行实时交互,会产生非常接近真实的视频场景。
发布「悟能」具身智能平台,为行业提供「机器人大脑」
提问:此次商汤发布的「悟能」具身智能平台,就是从「开悟」世界模型衍生出来的,能具体讲讲背后的技术路线以及战略意义吗?
王晓刚:我们为什么要做这个事情,刚才也提到,具身智能领域最大的挑战还是在于缺少数据。
其实大家想了各种办法,比如从互联网上收集,但是这些数据可能与机器人领域遇到的数据相差非常大,而遥操作去采集产生的每一条数据都非常昂贵,泛化性也不好。比如让它拿一个水杯,把瓶子和水杯换了,甚至换一张桌子,都会产生很大影响。而现在我们希望基于之前在世界模型的积累,能够给大家提供各种合成数据。
刚才提到「开悟」世界模型有几个特点,基于此,「悟能」具身智能平台就可以做很多事情。
第一,商汤过去在视觉领域有很多 3D 方面的积累,在基于各种场景、环境的人、物、场积累了 10 万个 3D 资产。另外我们做到了根据第一视角、第三视角来学习。
怎么理解,现在有一些机器人的工作是让机器人跟人学习,人在走动、坐下,捕捉到的这些视频映射到机器人上,它的机械臂应该如何进行操作。现在有了 AI 眼镜,未来会涌现大量第一视角数据,那现在我们把这两个东西结合在一块,就能够产生对应的这方面数据,对大家来说就是一个可用的状态,对行业也会有比较大的推动作用。
具身世界模型构建4D真实世界——指令:生成一段切黄瓜的机器人的视频——第一视角
第三视角
前不久像 Yann LeCun 他们推出来的世界模型也是第一视角的世界模型,就是想通过第一视角预测将来的动作是什么。
现在我们同时提供第一视角和第三视角,这是一个完整的对机器人行为的理解,就可以实现端到端的 VLA。
提问:有没有具体的案例可以分享一下,基于这个平台所带来的具身智能领域的变化?
王晓刚:比如那些机器狗,就可以做到跟着小孩、老人出去,有守护也有陪伴。有了这个导航后可以去任何地方,中间如果遇到异常状况,它也能够及时做出响应和处理。
另外家庭里面的陪伴型机器人,能够与我们进行对话聊天、产生记忆、建立情感上的连接。最近也可以看到,当下各种 AI 陪伴式提供情绪价值的机器人落地应用都是比较快的。
提问:刚才也提到,机器人的类型、功能、大小不同,难以泛化,那如何基于一个具身智能平台去实现?
王晓刚:这是将来要解决的问题,现在大家都解决不好这个问题。首先最重要的是我们要先解决行业里目前匮乏的数据问题,针对具体的一个机器人去采集数据,去微调、去适用它。这是首要解决的。
提问:当前业界关于「机器人大脑」的平台也有很多,比如前段时间智源研究院发布具身大脑 RoboBrain,「悟能」与之的区别是什么?
王晓刚:而「悟能」这个平台提供的是世界模型,这是比较新的一块。另外像导航、人机交互这些能力都是基于我们自动驾驶和人机交互流式多模态大模型产生的,这些与复杂操作还是有区别的。
提问:那基于「悟能」平台,商汤与各大机器人厂商的合作形式是怎样的?
王晓刚:首先在这个平台上,这些都是 SDK 软件功能,比如导航、人机交互、世界模型等,可以调用这个 API,需要产生什么样的数据,世界模型就能够把这些数据提供过来。可以想象我们做一个「机器人的大脑」。
而我们与机器人厂商的合作属于强强结合,因为机器人是一个软硬一体方案,将来想要在竞争中胜出,必须得具备足够多的壁垒。在这一块,商汤本身也投了一些机器人上下游公司,包括硬件、本体、或者零部件等企业,所以将来我们会有一个比较好的结合。
比如傅利叶,我们已经把流式多模态大模型提供给他们,能够进行人机交互,另外其他的一些机器人公司我们也提供了基础设施、算力等方面能力。
将来要提供整体方案,对硬件要求非常高,一旦在某一场景实现了软硬一体方案的交付,进行批量化的生产,就需要做到第一成本、第二质量,以及稳定的供应链,甚至售后,这些都离不开硬件。
具身智能是具像化的智能体
提问:当下具身智能爆火,技术层、应用层不断取得突破,那在你看来,当具身智能更为成熟的时候,人们的生活会发生怎样的变化?
王晓刚:我觉得可想象空间非常大。具身智能本身就是机器人,也是一个比较具象化的智能体,之前我们看到的都是人与人之间的联系,将来可以看到人与机器人、机器人与机器人之间的联系,将来我们的社交群体里可能会发现有机器人的存在,形成各种社交网络。因为机器人不光是一个工具,它有记忆、有情感载体。
另外,随着机器人通用化能力的增加,它的想象力和价值也会发生变化。当前家庭里用的各种电器和设备都是能够完成某一项功能,比如空调、洗衣机等,而当机器人走进家庭场景后,它能够完成多项功能,这些潜在的价值非常大。
当然,即便我们没有要求机器人能够实现完全的通用性,把各种事情都能完成,它只要每往前走一步,就能多做一些事情,都会给市场带来巨大的想象空间。
提问:如今商汤发布了「悟能」具身智能平台,那接下来在具身智能领域还有怎样的规划,或者希望扮演一个怎样的角色?
王晓刚:我们希望能够给这个行业提供「机器人大脑」,这是我们最擅长也是最强的,这个大脑里包含了眼睛、声音的交互、导航,以及操作。
商汤本身有很多这方面前期的技术积累,比如自动驾驶的积累能够用到具身智能的导航、交互。
另外,我们通过世界模型助力打造 VLA 相应的大脑算法,这对于商汤自身的发展来说,也是把我们从原有的在数字空间的积累,进入到物理世界时,实现物理与数字空间的连接。不光如此,将来还能够实现家庭、工作场所、汽车,这三个人类常用空间的连接。其中的核心就是机器人,因为机器人可以共享很多数据、记忆,能够把人的生活整个连接在一起。
而实现这些的基础就是商汤多年的积累,除了上面这些,还有「大装置」等。过去我们的云端、超算集群已经在给很多机器人公司赋能,包括数据闭环、端侧芯片等,我们希望基于这些综合能力赋能整个行业。
视频链接:
https://mp.weixin.qq.com/s/5PUSRIrwEYTwZmamJMD_ig