
本文一次性深扒Yan的仿真-生成-编辑三大内核、400M帧训练数据黑科技,以及对游戏、XR、智能体训练即将带来的冲击。想提前拿到“人人都是造梦师”的门票,从这5000字开始。

最近,腾讯推出了一款互动视频生成系统——Yan,面向游戏、虚拟世界、AIGC等场景,支持高保真、实时、可编辑的互动视频生成(论文地址:
https://arxiv.org/abs/2508.08601v3)。)
本文系统梳理Yan的技术方案,重点解析其在数据采集、AAA级仿真、多模态生成、交互式编辑等方面的核心突破,并展望未来发展方向。
一、什么是互动视频生成(IGV)?
互动视频生成(Interactive Generative Video, IGV [1])是指AI系统能够不断根据用户输入,生成可交互的视频内容。这一范式突破了传统视频生成的静态、单向特性,使内容能够动态响应用户操作,带来个性化、沉浸式的体验。其潜在价值包括:
- 内容创作:极大提升AIGC内容的多样性与可控性,赋能游戏、虚拟世界、影视、教育等领域的创作与交互。
- 智能体训练:为智能体提供无限、可控的仿真环境,推动通用智能体的研究与应用。
- 人机交互:实现更自然、实时的AI-人互动范式,拓展AI在娱乐、社交等场景的边界。
目前主流的互动视频生成方案主要包括:
- 世界模型:如上周新鲜出炉的Genie3 [2],可基于文本/图片生成可交互(可移动探索)环境,支持prompt可控编辑环境内容,但分辨率、交互丰富程度、交互时长等仍有提升空间。
- 基于游戏的互动视频生成:如The-Matrix [3]、Matrix-Game [4]等,聚焦于游戏场景,部分支持实时交互,但在泛化性、高分辨率、复杂物理仿真、内容编辑等方面存在不足。
我们的尝试👇
基于上述背景,我们团队在互动视频生成领域进行了一次系统性尝试,提出了Yan框架。“Yan”(衍)寓意“演化、流变”,象征着内容与现实的不断生成与展开。我们以“高画质、强交互、可编辑”为目标,探索了端到端的互动视频生成新范式,力求推动AIGC迈向下一代开放式、可控的数字内容引擎。
二、技术方案与应用探索
//2.1 总体框架概览
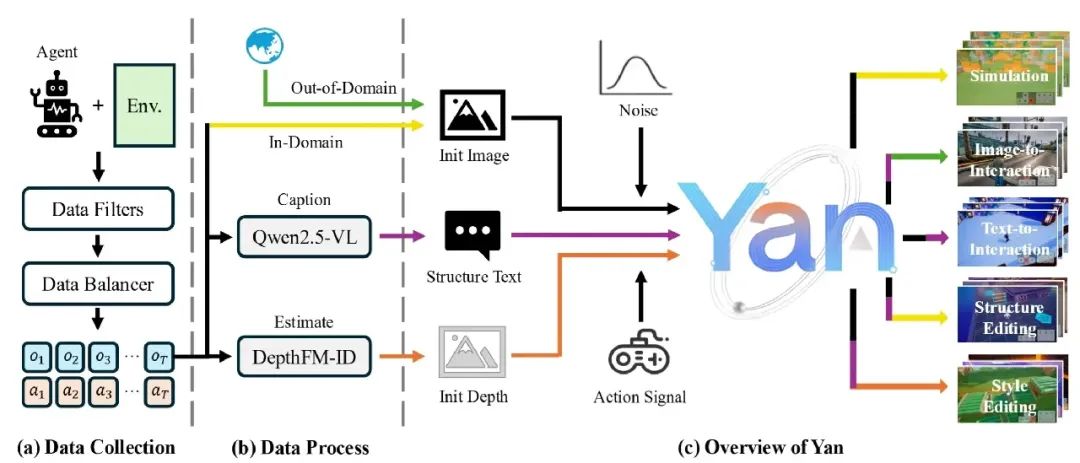
整体框架示意图
Yan整体采用端到端的互动视频生成范式,核心由三大模块组成:Yan-Sim(AAA级仿真)、Yan-Gen(多模态生成)、Yan-Edit(多粒度编辑)。三者均基于从游戏环境(基于元梦之星)中采样而来,大规模高质量互动视频数据集进行训练和协同优化,形成完整的“仿真-生成-编辑”一体化流程。其设计目标是实现高分辨率、低延迟、强交互、可编辑的开放式内容生成。
- Yan-Sim(AAA级仿真):实现高保真、实时的互动视频仿真,精准还原物理机制与用户操作响应,并支持多场景仿真与生成(如草原、城堡、雨林、月球等复杂环境,满足游戏、虚拟世界等高标准需求)。
- Yan-Gen(多模态生成):支持文本、图像等多模态输入,生成多样化、可控的互动内容,能够实现文本驱动的场景生成、跨域融合等多样化内容创作,展现出极强的泛化与可控性。
- Yan-Edit(多粒度编辑):支持结构与风格的实时编辑,用户可通过文本prompt动态修改内容,实现结构与风格的多粒度、实时交互式视频编辑,极大提升了内容创作的灵活性与交互性。
三大模块均依赖于统一的高质量互动视频数据采集与预处理流程,数据集为整个系统提供了坚实的基础。
//2.2 高质量互动视频数据采集
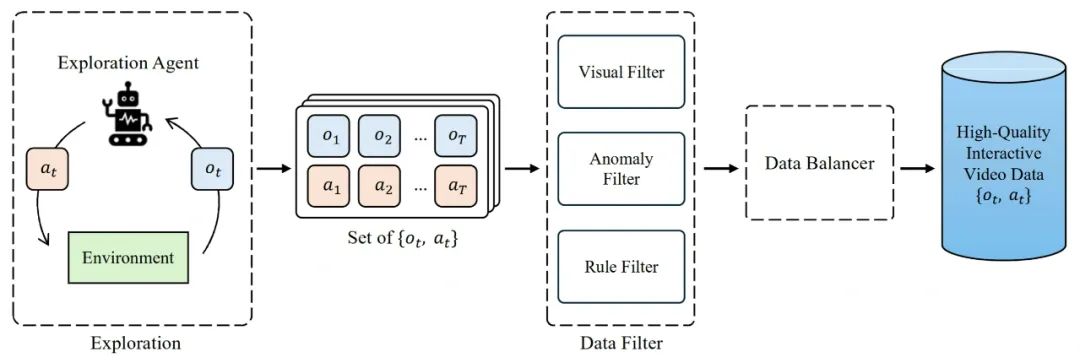
数据采集管线示意图
Yan构建了大规模的高质量互动视频数据集,覆盖90+场景、400M帧(3700小时),具备高分辨率(1080P)、高帧率(30FPS)、高精度动作-图像对齐和丰富动作空间。
- 自动采集管线:基于强化学习与随机策略的探索Agent,自动在现代3D游戏环境中采集多样化互动数据。
- 多重数据过滤:基于视觉、异常、规则三重过滤,剔除渲染失败、卡顿、规则异常等低质样本。
- 均衡采样:对位置、存活、碰撞等属性均衡采样,提升泛化能力。
- 多样动作空间:支持移动、跳跃、俯冲、视角旋转等复杂动作,拓展交互自由度。
数据集对比表:

//2.3 Yan-Sim:AAA级实时仿真及多场景应用
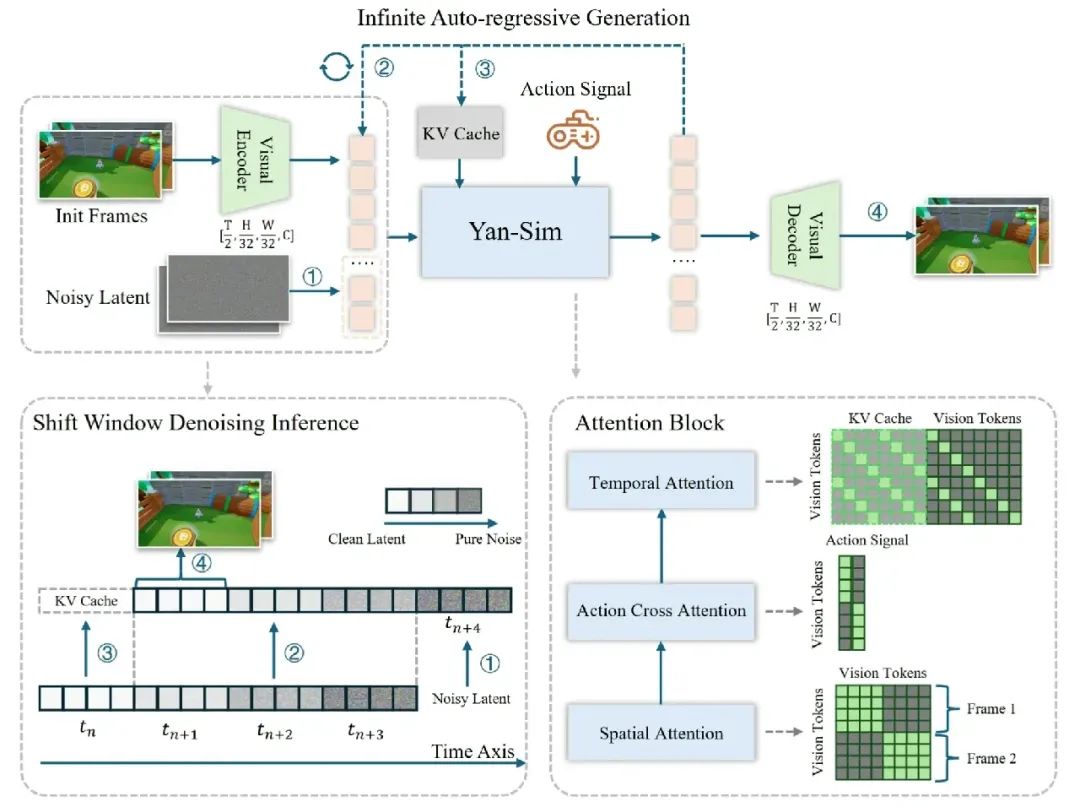
Yan-Sim模型结构示意图
Yan-Sim模块基于高压缩、低延迟3D-VAE与KV-cache shift-window去噪推理,实现1080P/60FPS的高保真实时仿真,支持复杂物理机制与多风格场景。
模型架构:
- 基于自回归扩散模型范式,VAE下采样因子由8提升至32,通道数扩展至16,并在temporal压缩2倍,极大提升推理效率。
- 扩散模型采用空间、动作、时序三重注意力,采用因果时序注意力机制,支持逐帧自回归生成。
推理优化:
- DDIM采样步数降至4,shift-window去噪并行处理不同噪声级帧,KV缓存减少冗余计算,支持每推理一次,就可以出一帧画面。
- 结构剪枝+FP8量化,推理速度提升1.5-2倍,支持多GPU并行推理加速。
特性对比表:

多场景仿真与生成效果:
- 多风格高分辨率场景还原,动作一致性强,物理机制(如惯性、电击、弹跳等)精准模拟。
- 支持无限时长、长视频生成,时空一致性优异。
2.4 Yan-Gen:多模态交互生成与内容扩展
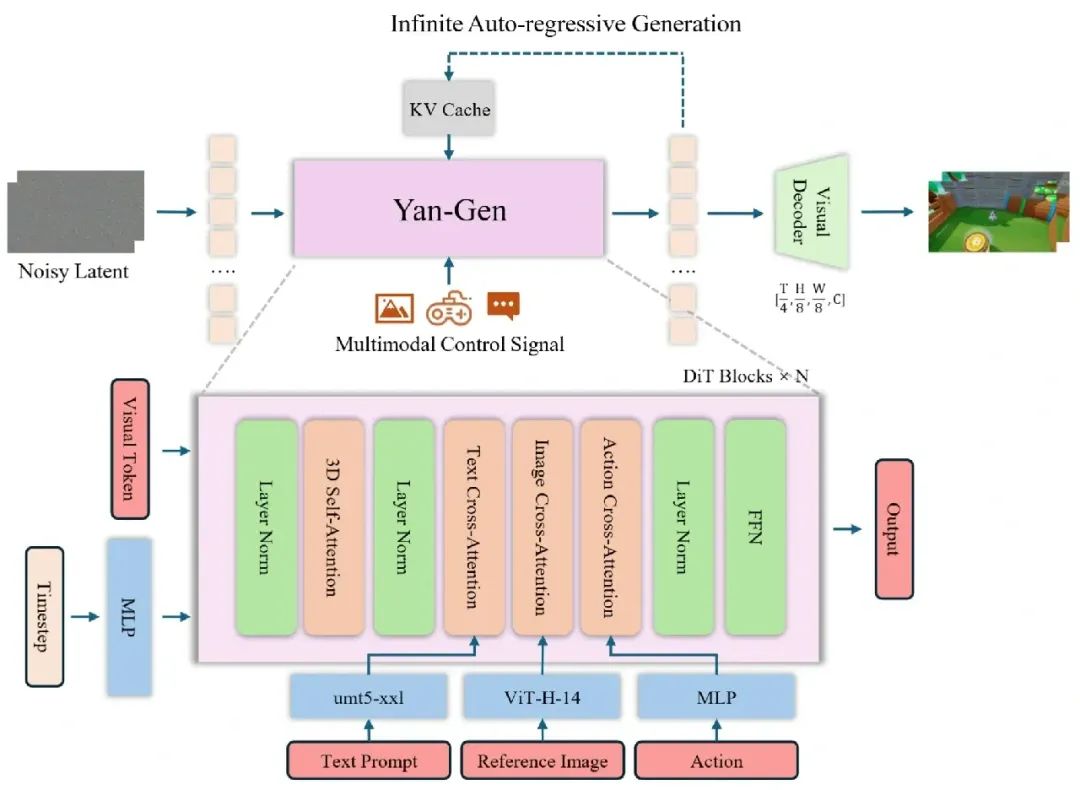
Yan-Gen模型结构示意图
Yan-Gen模块实现了基于文本、图像、动作等多模态输入的实时互动视频生成,具备强泛化与可控性。 能够实现交互场景生成、跨域融合等多样化内容创作。
层次化caption体系:
- 全局caption锚定世界静态属性(布局、风格、光照等),局部caption描述动态事件,防止长时漂移。
- 采用VLM自动标注,98M帧训练数据。
多模态条件注入:
- 文本(umt5-xxl)、图像(ViT-H-14)、动作序列分别编码,通过解耦cross-attention层注入DiT主干。
- 动作条件支持逐帧精准控制,提升交互响应。
自回归与蒸馏优化:
- ODE轨迹采样+block causal attention,训练few-step自回归生成器,DMD蒸馏提升推理效率。
- 单卡12-17FPS,多卡可达30FPS,支持无限时长、实时prompt切换。
多模态内容生成与扩展效果:
2.5 Yan-Edit:多粒度交互编辑与风格创作
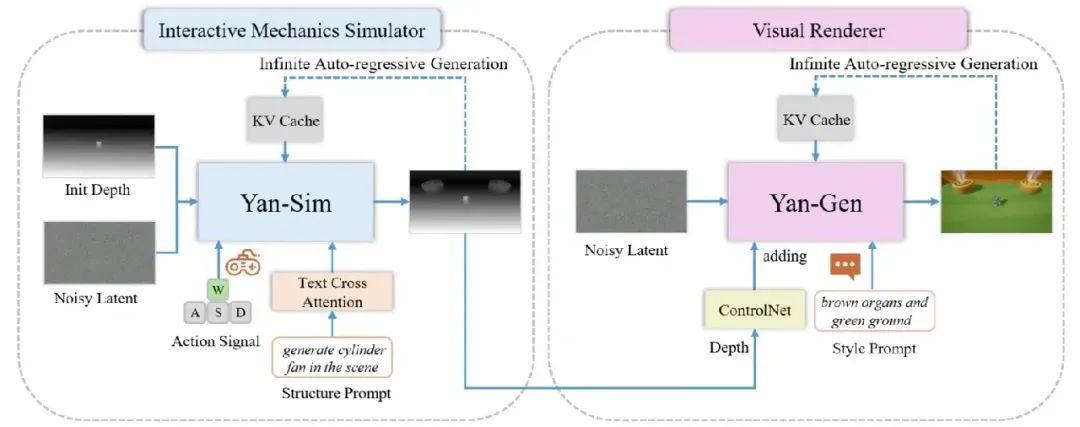
Yan-Edit模型结构示意图
Yan-Edit模块实现了结构与风格的多粒度、实时交互式视频编辑,支持任意时刻通过文本prompt修改内容。 用户可通过文本prompt动态添加/替换场景元素、切换渲染风格,极大提升了内容创作的灵活性与交互性。
架构设计:
- 采用“交互机制模拟+视觉渲染”解耦架构,以深度图为中间态连接两个模块
- 交互机制模拟模块基于Yan-Sim,结构prompt通过cross-attention注入,支持结构编辑。
- 视觉渲染模块基于Yan-Gen+ControlNet,style prompt控制风格渲染。
训练与推理:
- 深度图VAE+结构/动作联合训练,风格渲染用VACE [9]开源ControlNet权重,DMD蒸馏few-step生成器。
- 支持任意时刻结构/风格prompt切换,保证编辑内容的交互性与时空一致性。
结构与风格实时编辑效果:
- 结构编辑:动态添加/替换场景元素,实时响应用户操作。
- 风格编辑:多风格切换,支持开放域描述,编辑过程无缝衔接。
3 总结与展望
局限性:
- 长时空一致性仍有提升空间,复杂交互场景下偶有漂移。
- 轻量化与边缘部署待优化。
- 动作空间与交互复杂度受限于底层环境,向真实世界扩展仍需探索。
未来方向:
4 参考文献
[1] Jiwen Yu, Yiran Qin, Haoxuan Che, Quande Liu, Xintao Wang, Pengfei Wan, Di Zhang, Kun Gai, Hao Chen, and Xihui Liu. A survey of interactive generative video. arXiv preprint arXiv:2504.21853, 2025a.
[2] Genie 3: A new frontier for world models
[3] Ruili Feng, Han Zhang, Zhantao Yang, Jie Xiao, Zhilei Shu, Zhiheng Liu, Andy Zheng, Yukun Huang, Yu Liu, and Hongyang Zhang. The matrix: Infinite-horizon world generation with real-time moving control. arXiv preprint arXiv:2412.03568, 2024.
[4] Yifan Zhang, Chunli Peng, Boyang Wang, Puyi Wang, Qingcheng Zhu, Zedong Gao, Eric Li, Yang Liu, and Yahui Zhou. Matrix-game: Interactive world foundation model. arXiv, 2025.
[5] Mingyu Yang, Junyou Li, Zhongbin Fang, Sheng Chen, Yangbin Yu, Qiang Fu, Wei Yang, and Deheng Ye. Playable game generation. arXiv preprint arXiv:2412.00887, 2024.
[6] Jiwen Yu, Yiran Qin, Xintao Wang, Pengfei Wan, Di Zhang, and Xihui Liu. Gamefactory: Creating new games with generative interactive videos. arXiv preprint arXiv:2501.08325, 2025b.
[8] Genie 2: A large-scale foundation world model
[9] Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. Vace: All-in-one video creation and editing. arXiv preprint arXiv:2503.07598, 2025.
本文由人人都是产品经理作者【汪仔2301】,微信公众号:【鹅厂技术派】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。







