梦晨 西风 发自 凹非寺
量子位 | 公众号 QbitAI
OpenAI最新模型曝光了,在2025年国际数学奥林匹克竞赛(IMO)上达到了金牌水平!
IMO被公认为全球最顶尖的数学竞赛,每年只有不到8%的参赛者能够获得金牌。而现在,一个AI模型做到了。
新模型最终成绩:新模型在总共6道题中成功解决了5道,获得35分(满分42分),超过了今年的金牌线。

OpenAI员工Alexander Wei还透露,GPT-5即将发布,但IMO金牌模型是一个实验性研究,在几个月内都没有计划发布。
他特别强调,这次成功并非依靠针对特定任务的狭隘方法,而是在通用强化学习和测试时计算扩展方面取得了新突破。

与此同时,第三方机构的开源代码中被发现GPT-5-reasoning-alpha-2025-07-13的字样。

这段代码被挖出来后很快就被删除或隐藏,结合OpenAI在新模型发布前会找第三方机构进行安全测试的惯例——
种种迹象表明,GPT-5离我们不远了。
35分斩获金牌,解题过程完全模拟人类考试
具体来看OpenAI的实验性新模型,这次评测可不是随便做个题那么简单。
OpenAI团队让模型在与人类选手完全相同的条件下参加考试:两场各4.5小时的考试,不能使用任何工具或联网,只能阅读官方题目陈述,然后用自然语言写出证明过程。

最终成绩出来了:模型在6道题中成功解决了5道,获得35分(满分42分),稳稳超过了今年的金牌线。
今年IMO的金牌分数线正好是35分,这个成绩放在人类选手中也是妥妥的金牌水平。今年约600名参赛者中,只有5人拿到了满分。
更让人印象深刻的是评分过程的严谨性。每道题的解答都由三位前IMO奖牌获得者独立评分,只有在三人达成一致意见后才确定最终分数。
这次突破的意义不止于成绩,正如研究团队所说,IMO问题需要的是一种全新水平的持续创造性思维。
从推理时间跨度来看,AI的进步速度简直让人瞠目结舌:从GSM8K(顶尖人类约需0.1分钟)到MATH基准测试(约1分钟),再到AIME(约10分钟),现在终于攻克了IMO(约100分钟)这个需要长时间深度思考的难题。
更重要的是,IMO的答案是难以验证的多页证明,这与之前那些有明确正确答案的数学题完全不同。OpenAI团队表示,他们突破了传统强化学习中依赖明确可验证奖励的范式,创造出了能够像人类数学家一样构建精巧论证的模型。

唯一没能攻克的是第六题——这道被参赛者称为“最终Boss”的组合数学难题:
有一个2025×2025的单位正方形网格。玛蒂尔达希望在网格上放置一些矩形块,这些块的大小可能不同,使得每个块的每一条边都位于网格线上,并且每个单位正方形最多被一个块覆盖。求玛蒂尔达需要放置的最小块数,使得网格的每一行和每一列都恰好有一个单位正方形未被任何块覆盖。

去年IMO题目中,谷歌用Alphaproof和AlphaGeometry完成了四道题,未完成的两道也属于组合数学。
不过这一次,DeepMind研究员Archit Sharma在OpenAI宣布后回复:“恭喜!抢在我们前面宣布了——第6题是新的基准了吗?”
但这条推文很快就被删除了。
这个小插曲引发了网友们的各种猜测:莫非Google的模型也达到了类似水平。
如果感兴趣的话,还可以进一步查看OpenAI公开的AI解题过程,链接在文末获取。

引发圈内热议,陶哲轩发表长评
OpenAI模型斩获IMO金牌的消息一出,AI圈炸开了锅。不过,在一片赞叹声中,也出现了一些不同的声音。
其中最受关注的,当属数学界顶尖学者陶哲轩的表态,他在社交媒体上针对此事发表了长篇评论。
陶哲轩指出,虽然多家AI公司都声称在IMO题目上取得了好成绩,但由于缺乏统一的测试环境和标准,很难进行公平比较。
人们很容易将当前AI的能力视为一个单一的量化指标——要么能搞定某件事,要么就完全不行。但其实不是这样,AI到底有多厉害,这得看给它多少资源、多少辅助手段以及不同的结果呈现方式,种种因素影响下,AI能力能差出好几个量级。
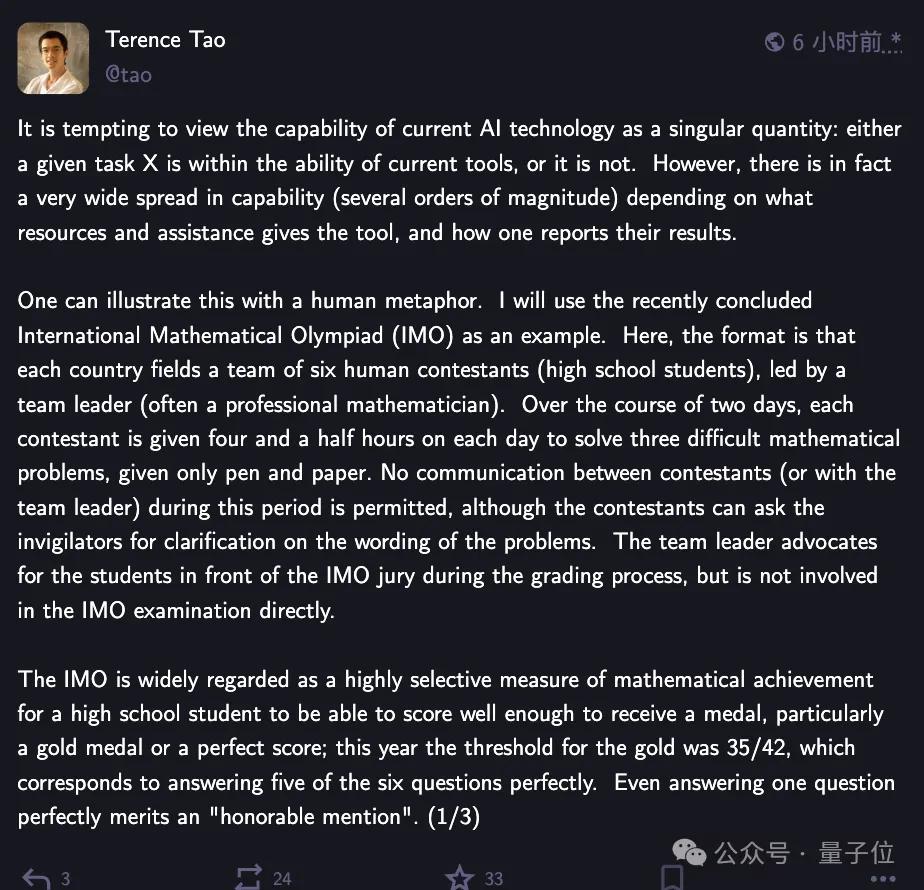
他特别强调:“在没有预先公布方法论的情况下,不会对任何自我报告的AI竞赛表现发表评论。”

陶哲轩用生动的比喻列举了多项AI可能采取的措施:
给学生几天时间来完成每道题,而非用四个半小时解答三道题。(稍微延伸一下:给学生的时间仍只有四个半小时,但领队将他们放入某种昂贵且耗能巨大的时间加速装置,在这段时间里,学生们会经历数月甚至数年的时光。)
考试开始前,领队将题目改写成学生更易理解的形式。
领队让学生可以无限制使用计算器、计算机代数软件、形式化证明辅助工具、教科书,或者拥有上网搜索的权限
领队让6名学生组成的团队共同攻关同一道题,就各自的部分进展和遇到的瓶颈进行交流。
领队给学生提示可行的解题方向,若发现有学生在明知不太可能成功的方向上耗费过多时间,便会进行干预。
团队的6名学生都提交了解答,但领队只挑选出“最佳”解答提交给竞赛,其余的则弃之不用。
若团队中没有任何一名学生得出令人满意的解答,领队就完全不提交任何解答,悄无声息地退出竞赛,且无人知晓他们曾参与过。
而这些措施均改变了竞赛形式从而影响题目难度。

与此同时,数学竞赛评测平台MathArena发布了独立评测结果。
在他们的测试中,即使是表现最好的Gemini 2.5 Pro也只获得了13分(31%),远低于铜牌线19分。

测试使用了best-of-32的选择策略,即对于每个模型的解答,首先生成32份回应,随后借助“大语言模型评审系统”对这些回应进行评估,两两比对选出更优答案。
每份最终的模型答案生成成本至少为3美元,其中Grok-4模型每份答案的成本超过20美元,但即便如此,仍然没有任何模型能达到获奖牌的水平。
MathArena团队也同步更新了OpenAI宣布实验模型拿到IMO金牌的消息:
无法验证这些结果是如何实现,期待该模型的发布以及使用MathArena基准进行独立评估。

虽然OpenAI模型拿金牌的方法论未公开,但也有不少网友表示,不看过程,结果同样具有意义。

OpenAI团队对自己的成果充满信心。
参与此项目的研究员Alexander Wei回忆说:“2021年,我的博士导师让我预测2025年7月AI在数学上的进展,我当时预测MATH基准测试能达到30%(还觉得其他人都太乐观了)。结果现在我们拿到了IMO金牌。”

OpenAI新模型解题过程:
https://github.com/aw31/openai-imo-2025-proofs/
参考链接:
[1]https://twitter.com/alexwei_/status/1946477742855532918
[2]https://x.com/btibor91/status/1946532308896628748
[3]https://social.vivaldi.net/@tao@mathstodon.xyz/114881418791593328
[4]https://www.reddit.com/r/singularity/comments/1m43gar/looks_like_deepmind_has_also_won_imo_gold_but/
[5]https://matharena.ai/imo







