
世界模型是 AGI 的关键拼图,Genie 是 Google 给出的最新答案。这篇文章不仅讲清 Genie 的技术原理,更拆解它在产品形态、交互方式与落地路径上的潜力与挑战,为你提供一份通向未来智能产品的参考坐标。

首先我们了解一下什么是“世界模型”
想象你的大脑如何理解一个房间。你不是简单地”存储”房间里每个物体的位置,而是心理建立了一个完整的房间地图,包括:物体之间的空间关系放在在那里?不同的物体该怎么使用?如果你移动某个物体会发生什么变化?怎么从空间中这里走到那里?
世界模型就是AI系统的这种”心理地图”,通过数学和计算的方式来表示的。
世界模型是人工智能系统对现实世界或虚拟环境的内部表示和理解框架。它不仅仅是对静态信息的存储,更是一个动态的、可预测的系统,能够模拟环境的变化、物理规律的作用,以及不同行为产生的后果。世界模型让AI从“空无猜想”变成“活灵活现”,能够像人一样在脑中“预演”各种可能性。世界模型几个关键特征:

Genie 的起源发家史
首先了解一下Genie的整个产品的发展路线和变换,才能对这个产品品有更深入的理解。
起点:Genie 1 — 生成2D互动环境
Genie 1 是 DeepMind 在 2024 年2月推出的基础“世界模型”,具备通过文本、图像、照片或草图生成可操作虚拟场景的能力,支持逐帧交互。该模型规模达 110 亿参数,通过时空视频编码器、自回归动力学模型和潜在动作模型构建,被视为早期的“Foundation World Model,这为生成和进入虚拟世界的各种新路径开启了大门。
用户只需提供一张纸上的草图、一幅完美的数字艺术作品,甚至是AI生成对2D世界的描述,Genie就会完成剩下的工作,帮用户生成2D游戏。

跃升:Genie 2 — 生成可玩 3D 世界
探索于 2024 年12月,Genie 2 可从单张图像生成多样化、可交互的 3D 世界。其环境结构是一致的,用户或 AI 在穿梭后返回场景中仍然保持不变,并支持人类或 AI 进行动作操作(如跳跃、水中行走、攀爬等)因此这些环境可被用来训练所谓的 embodied agents(具身智能体),让 AI 在虚拟世界中自主探索、决策、执行目标。Genie 2 甚至特别指出可用于训练这类 agent。
飞跃:Genie 3 — 实时交互与世界记忆的突破
2025 年 8 月推出的 Genie 3,是第一个真正支持实时交互的“世界模型”。它可把文本或图像提示转化为 720p、24 FPS 的互动 3D 场景,用户可以实时探索并交互,环境保持一致且反应自然 。可用于游戏原型开发、AI agent 训练、机器人仿真、教育模拟、历史还原、虚拟旅游等

总结
Genie3的发展历程体现了世界模型技术的演进:
第一代Genie主要专注于2D游戏环境的生成➡️
第二代Genie2扩展到更复杂的视频生成和简单的3D场景➡️
Genie3则实现了真正意义上的3D世界模拟,具备了前所未有的真实感和交互性~
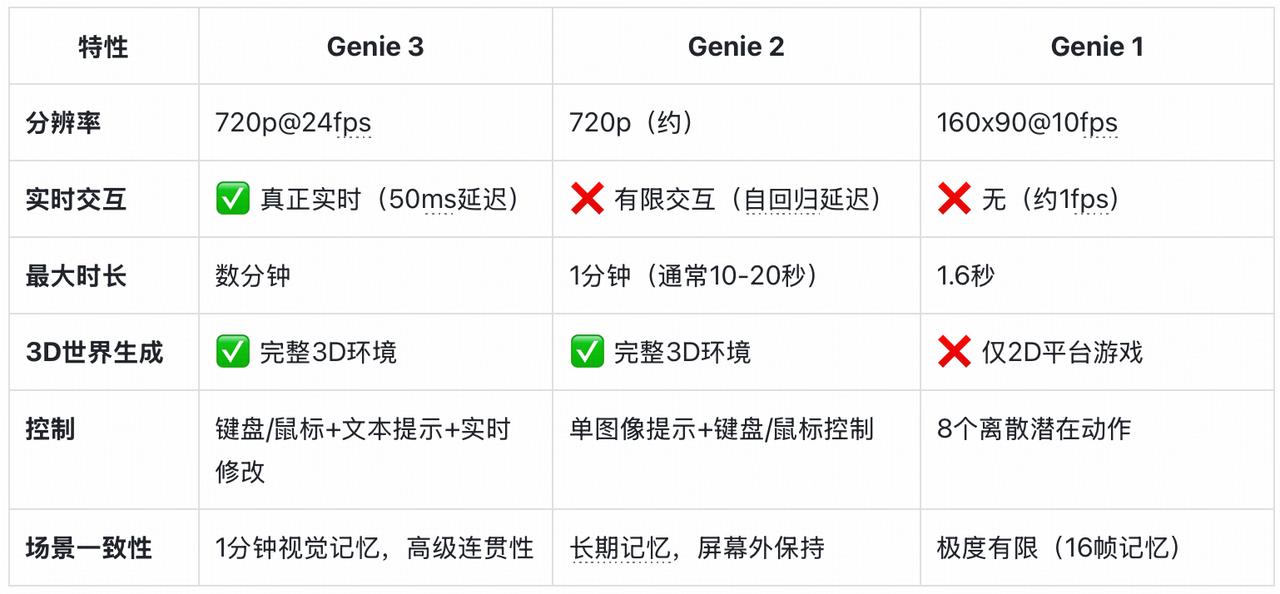
Genie 3 技术特点
1. 实时交互的技术奇迹
Genie 3可以以24fps的速度进行流媒体传输,能够记住物体长达一分钟,实现了真正的实时交互。这不仅是静态视频或一次性模拟,而是实时、可控的世界,用户可以在其中移动、响应、改变,分辨率达到720p,24 FPS,一致性可以保持几分钟。
这种实时性的实现依赖于全新的计算架构设计。模型在处理每一帧时,不仅要考虑当前的用户输入,还要综合分析之前几分钟内积累的所有交互历史。这就像是一位经验丰富的游戏设计师,能够在玩家每次操作后立即构想出下一个场景,同时确保整个体验的连贯性和逻辑性。
可以实现在火山地形上行走,乘坐摩托艇根据你的操作进行拐弯驾驶穿过节日水域,或在深海峡谷中航行

2.长期一致性维护
先进的神经架构通过参考先前的轨迹信息来维持长期一致性 。Genie 3环境在几分钟内保持基本一致,视觉记忆可以追溯到一分钟前。这种一致性是模型的新兴能力,与依赖显式3D表示的NeRFs和Gaussian Splatting等方法不同。
想象一下,模型需要在生成每一帧的同时,在脑海中维持一张不断更新的”世界地图”,这个跟我们之前游戏需要构建一个完整的空间已经搭建好的场景完全不一样,需要有实时生成+强大记忆(一致性)。当用户重新访问之前去过的地方时,模型需要准确地从记忆中提取相关信息,并且需要确保环境的一致性。
如果你在一面墙啊上画一幅画转身离开,回头看看,世界仍然和你离开的一样。Google DeepMind Genie 3可以记住对象、纹理和文本长达一分钟。



3.可提示的世界事件
允许用户和AI代理触发”可提示”事件:比如即时天气变化或新角色但是并而不破坏当前沉浸感 。这种能力使用户能够通过文本指令动态改变生成的世界,如改变天气条件或引入新的物体和角色。每一个指令都会实时反映在画面中,可以立即看到不同创意选择的视觉效果,大大加速了创意探索的过程。
你可以立即改变世界。从晴朗的天空切换到飓风,添加新角色,或创建梦幻般的门户——所有这些都不会打破沉浸感。可以给现有的场景中加各种事件。比如“一只龙从天而降”“一个穿着公鸡玩偶的人跑过”“开始下雨””出现一个穿红衣的神秘女性”、”街灯开始闪烁”、”远处传来警笛声”

4.多样化环境生成
能够模拟从现实景观到奇幻世界的多样化环境 ,与许多依赖预编程物理引擎的系统不同,Genie 3通过观察大量真实世界的视频数据,自主学习了物理规律。水会向下流淌,物体会因重力而下落,光线会投射阴影,所有这些都基于模型对真实物理世界的理解,让AI通过理解其中的规律进行重现。
换句话说,他们并没有为这些行为做专门的训练或设计,而是模型自己「学」出来的。它通过足够丰富的训练数据,掌握了这个「世界」的通用常识。大多数时候,它表现非常不错。
自然现象建模(水和光照效果)和自然世界模拟(生态系统、动物行为、植物生命)

5.创意产业:想象力的具现化
在创意产业中,Genie 3正在模糊现实与想象之间的界限。谷歌Genie 3引擎在富有想象力的动画世界中也很出色。建造发光的蘑菇森林、异想天开的树屋村庄或充满活力的彩虹桥,有奇妙的生物。无论是游戏、电影还是讲故事,Genie 3世界模型都以完整、可探索的3D将小说带入生活。

6.探索位置和历史设置
Genie 3正在创造一种全新的学习方式。可以让你真正”走进”公元80年的罗马,站在斗兽场的观众席上,观看角斗士的比赛,感受古代观众的欢呼声。Genie 3模型以丰富的纹理、逼真的灯光和互动深度再现了地方和时代,使探索感觉真实而身临其境。
可以沉浸感受不同时期的不同场景,比如可以输入指令“威尼斯的运河”“古罗马斗兽场,公元80年”“赛博朋克城市,2080年”

实现的技术手段
在过去几年里,AI 的生成能力经历了惊人的飞跃:从最初的文本生图(MidJourney、Stable Diffusion),到文生视频(Sora、Pika),再到如今的世界生成。
Genie 3代表着 AI 第一次真正让“虚拟世界”变得可玩、可探索、可修改,能够根据文本或交互指令,实时生成高保真、物理一致的3D虚拟场景。其核心机制可拆分为以下几个模块,每一模块都对应关键的技术挑战。
那么这个世界模型到底是怎么实现的呢?
如何实现了真正意义上的3D世界模拟,具备了前所未有的真实感和交互性?
1. 世界建模(World Modeling)
1.1 内部表示与因果推理
传统的自回归生成面临着一个核心挑战:随着序列长度的增加,累积误差会导致生成质量的快速下降。对于世界模拟而言,这个问题更加严重,因为任何小的不一致都会破坏整个虚拟世界的可信度。
Genie 3 并非逐个像素地拼凑画面,而是维护一个高维抽象的“世界状态”向量,包含场景中所有物体的位置、姿态、物理属性(如质量、摩擦系数)及对象间的因果关系。这一表示需要同时满足:
- 多模态一致性:视觉、物理、语义信息一一对应。
- 可微分渲染兼容:模型输出可用于梯度反向传播,便于端到端训练。
这种技术的优势:
- 用抽象而压缩的结构化表示,代替庞大的逐像素建模,提升泛化性与计算效率。
- 支持可逆可调的物理模拟与画面生成:例如调整光源角度,模型能推断出阴影和亮度变化。
1.2 隐状态更新与记忆
系统利用变分自编码器(VAE)或扩散模型编码当前帧的视觉输入,并结合长短期记忆(LSTM)或自注意力网络(Transformer)维护场景演化的时序隐状态。
技术难点:如何保证记忆网络在长序列(上千帧)下不出现梯度消失/爆炸,并且能够保留远距离因果关系(如前面墙体破损如何影响后续光影)。
2.自回归渲染(Autoregressive Rendering)
2.1 帧间预测
Genie 3 将每一帧的渲染视为条件自回归过程:
1. 输入:上⼀帧图像编码 + 当前世界状态 + 用户操作(如“向前移动”“拾取物体”)。
2. 预测:下⼀帧图像编码。
3. 渲染:解码器将预测编码转换为像素级画面。
技术难点:实时性要求每帧处理时长 < 40>
2.2 物理一致性
为了防止物体“穿模”或“闪烁”,系统在自回归渲染的同时融入了基于物理引擎的约束计算,最重要的创新是emergent physics understanding(涌现物理理解),Genie 3无需硬编码物理引擎,需要用碰撞检测与力学求解器实时计算下一状态的物理边界。通过观察学习物理:
- 重力和碰撞检测:物体掌落、弹跳和真实交互
- 流体动力学:水流运动、飞溅和反射效果
- 光照效果:动态阴影、反射和照明变化
- 材质物理:不同表面类型的适当响应
技术难点:深度网络与传统物理引擎的耦合瓶颈。如何在保持渲染速度的同时保证求解精度,是架构设计的重点。复杂多对象交互偶有物理不一致, TechCrunch软体物理(布料、绳索)仍有挑战,流体模拟在复杂几何交互中存在瑕疵。
2.3 时间连贯性维护
Genie 3实现了unprecedented temporal coherence(前所未有的时间连贯性),视觉记忆窗口能够满足长达1分钟, 长程记忆解决了自回归生成中的累积误差问题。
连贯性机制:
- 空间关系维护:环境逻辑在不同视点间保持一致
- 对象持久性:树木、建筑等在重访回看时保持一致
- 动作一致性:角色动画和运动的真实表现
- 环境交互:如气球破裂、开门等复杂交互的长期维护
3.文本与交互指令理解
3.1 语义解析与指令映射
Genie 3的文本理解基于修改版T5架构,结合领域特定微调,实现复杂文本提示到3D环境的精确映射。 Cursor IDE系统支持:
- 详细环境描述:天气、光照、地理和交互元素的精确解析
- 复杂叙事提示:场景、角色和动态事件的综合描述处理
- 空间关系理解:展现解释和维护生成环境中空间一致性的能力
指令处理流程:
- 文本到世界生成管道:转换自然语言为交互式3D环境
- 语义空间关系理解:维护生成环境的空间一致性
- 上下文感知场景生成:理解并实现提示中描述的复杂环境交互
- 动态指令执行:处理”可提示世界事件”的实时文本指令
3.2 即时反馈与一致性校正响应生成架构采用自回归帧生成,每帧考虑随时间增长的先前生成轨迹。 记忆引用系统可在用户重访位置时引用1分钟前的相关信息,实现近即时输入响应和立即环境反馈。
指令解析后,系统立即在内部世界状态上应用变换,并触发自回归渲染。为了避免用户“塞入”不合理指令(如把刚投掷的球瞬移到半空),需要:
- 合法性检查:规则或学习出的约束对指令进行过滤与修正。
- 回滚与重试:若渲染结果与物理规则冲突,自动回滚到最近合法状态并尝试次优解。
4.系统架构与硬件优化
4.1 模型并行于流水线帧级并行:使用双缓冲技术,一边渲染当前帧,一边预测下一帧的隐状态。
模型切分:将编码器、物理求解器、解码器拆分到不同加速单元(如编码器在 TPU,渲染在 VPU)。
4.2 低延迟传输与异步计算RPC 与共享内存:各模块间通过高速总线异步交换世界状态,减少等待时间。
动态精度调整:根据场景复杂度自动切换计算精度(如远景用半精度浮点,近景用全精度)。
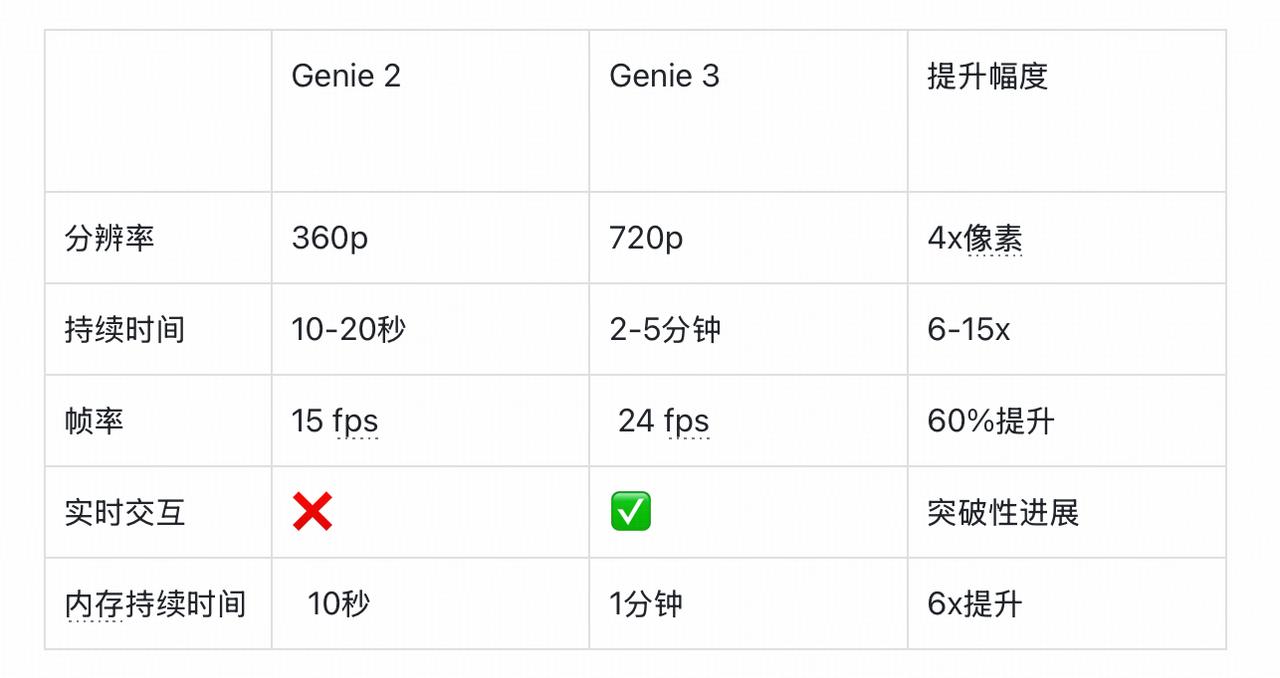
主要技术突破和难点汇总
核心技术突破点

当前技术限制分析

Genie3真的能打开AGI的大门吗?
先说结论
Genie 3 是通往 AGI 的“关键模块节点”,它像是未来 AGI 大脑中的“3D 世界视觉 + 物理理解系统”,具备了构建抽象世界模型的雏形。但若说它已经实现了真正的“通用智能体”,仍然为时尚早,中间还有多个关键跨越点需要攻克。
从“看图生成”到“理解世界”的转变
Genie 3 之所以引发如此大关注,是因为它代表了一种范式转变:从传统的逐帧图像生成,走向对世界状态的构建与演化建模。它不再是“根据输入图片生成下一帧”,而是在内部构建了一个高维的抽象状态向量,用于表达场景中每一个物体的位置、运动状态、物理属性,甚至它们之间的因果关系。这种能力让人类第一次在消费级 AI 模型中,看到了“世界建模(World Modeling)”的真实形态。
这种模型可以模拟“如果灯光关闭,房间会变暗”、“如果球撞到墙,会反弹”等常识性物理推理,并通过自然语言对这些世界状态进行实时操控。这比仅仅会“画画”的扩散模型,更能让我们想象出来未来AGI完全可以为我们构造一个全新世界的愿景。
Genie 的迭代速度远超预期
值得注意的是,从 Genie 第一代模型提出,到如今 Genie 3 发布,仅仅经历了不到一年半的时间。在这短暂的周期内,模型的核心能力从2D视频生成跃迁为3D的可交互、可推理、可操控的实时世界建模系统,其背后的技术进化速度远超我们的想象。
这不仅仅是模型架构的进步,更是底层理念的突变。Genie 3 不再将世界当作一帧帧像素去处理,而是转向模拟“现实演化”的高维潜在空间表达,这种做法本质上更加接近于人类对世界的认知方式。
从某种意义上说,Genie 的这条路线,正在尝试为 AGI 构建“感知+理解+交互”的一整套底层接口。
AGI 的一块“世界模拟器芯片”
尽管 Genie 3 的能力令人兴奋,它依然不具备实现 AGI 所需的通用性和自主性。目前,它的核心优势集中在物理世界的模拟与可控交互,它在跨模态认知能力、自主目标生成能力、长期记忆与规划能力、自我模型认知能力这些方面,目前的 Genie 仍需进一步提升。它更像是未来 AGI 系统中不可或缺的一个“子模块”——一个高度智能、能模拟现实的3D 世界感知和物理交互单元,可能作为通用智能体的“感知中枢”或“虚拟世界引擎”存在。
换句话说,Genie 不是通用智能体,但它让我们看见了通用智能体可以生长的土壤。
结语:世界模型是通向 AGI 的关键钥匙
Genie 3 的出现只是为AGI确指向了一个未来的方向——机器智能不应止步于理解语言或生成图像,更应该具备对世界的感知、建模与推理能力。
它所构建的高维“世界状态”向量、实时可交互的物理模拟能力,以及对因果结构的涌现理解,构成了未来通用智能体“感知-认知-行动”链条中的重要一环。正是通过这种模拟与建模的能力,AI 才可能逐步接近人类的理解方式,拥有“身临其境”的认知体验。
正如 DeepMind 创始人Demis Hassabis所言:
世界模型是智能的核心。如果 AI 无法模拟世界,它就无法真正理解这个世界。

本文由 @LULAOSHI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图由作者提供







