不可否认,进入2025年,AI算力的需求已经呈现出爆发的态势,数据显示,几乎平均每7天就会有一版新的大模型诞生。而模型训练是个复杂的系统工程,一个基础大模型,通常在万枚先进AI芯片组成的算力集群上,进行数周甚至数月的不间断训练。与此同时,在万卡集群中,集群规模越大,就意味着故障概率就越高。
这种爆发式的算力需求,也倒逼整个GPU行业加速进化。一方面,单卡算力需要持续突破,以应对万亿参数模型的训练效率要求;另一方面,万卡级集群的协同能力、故障冗余机制成为核心竞争力 —— 毕竟,任何一个节点的中断都可能导致数周训练成果功亏一篑。这不仅意味着对单卡算力的极致追求,更考验着集群协同的稳定性与容错能力。
在WAIC 2025上,摩尔线程亮出了其解题方案——从支撑万卡集群的夸娥智算平台,到边缘AI计算模组与解决方案,这套覆盖 “通用计算+实时图形渲染” 的云边端全栈AI产品和解决方案,直指当下AI算力在规模、精度与可靠性上的多重诉求,也让国产GPU看到了从 “跟跑” 到 “并跑” 的可能性。

此外,摩尔线程也公布了其 “AI工厂”计划。
摩尔线程创始人兼CEO张建中在演讲中提到:“当前,为应对生成式AI的爆发式增长下大模型训练效率瓶颈,单一的算力设施已经无法满足AI的生产速度,它需要的是运行和支持一切模型的基础设施,即大型人工智能计算基础设施,也可以叫它‘AI工厂’,而这个AI工厂的核心便是算力芯片。”
那么,这个承载世界先进模型的超级AI工厂如何打造?
KUAE为核,打造世界先进的AI工厂
在回答这个问题之前,首先需要明确的是,AI工厂由哪些要素组成?
对此,张建中表示:“生产效率决定生产力,要提升生产力,就需要通过软件、硬件、流程、工艺、质量、方法、监控、管理等一系列手段提升。AI工厂也同样如此,它绝不是简单的芯片堆叠,核心在于算力芯片,除此之外,还需要依赖网络拓扑、集群管理、算法工具、算子库等多维度协同。”

在此基础上,摩尔线程给出了一个AI工厂生产效率公式:加速计算通用性×单芯片有效算力×单节点效率×集群效率×集群稳定性。
展开来看,首先是通用性。生成式AI与多模态技术爆发的当下,“通用性” 早已不是 “能做多种任务” 的简单定义,而是能在AI训练、图形渲染、科学计算等复杂场景中无缝切换、高效协同的综合能力 —— 这正是全功能GPU的核心价值。
回溯GPU的发展历程,从早期单一功能的3D加速卡(类似ASIC)到如今的全功能GPU,本质上是一场 “从专用工具到万能平台” 的革命。
摩尔线程对“通用性” 的诠释,首先体现在四大核心引擎的 “全栈覆盖”:
- AI计算加速引擎:支持从FP4到FP64全精度,尤其FP8训练效率提升30%;
- 现代3D图形渲染引擎:兼容DirectX 12等主流标准,支撑高端游戏与数字孪生;
- 物理仿真与科学计算引擎:满足超算、自动驾驶仿真等需求;
- 超高清视频编解码引擎:覆盖从端到云的多媒体处理场景。

这种通用性最终转化为对多元场景的“全适配”:无论是训练一个能写代码的大语言模型,还是开发一款支持实时交互的AIGC应用,抑或是为科研机构搭建气象预测的超算平台,全功能GPU都能成为 “一站式解决方案”。
第二,自研MUSA架构。这套架构的核心突破在于 “多引擎可配置 + 统一编程接口”:

- 硬件层面:整合张量计算与访存引擎,实现“存算一体”,FP8 Transformer引擎针对性加速大模型;
- 通信层面:独创ACE异步通信引擎,解决传统GPU“计算时无法通信” 的问题,通信效率提升10%-15%;
- 互联层面:MTLink2.0互联技术提供了高出国内行业平均水平60%的带宽,支撑万卡级集群的低延迟互联;
- 编程层面:OneAPI编程接口与共享内存池设计,让开发者可灵活调度多元流水线,无需关注底层硬件差异。
第三是MUSA全栈系统软件。通过驱动优化、算子打磨、生态兼容与工具链支撑,将全功能GPU的硬件潜力转化为可感知的高效算力,实现软硬件协同增效。
其核心优势体现在四个维度:
- 高效驱动:支持单次发布1000个任务,任务延迟远低于国际主流产品,通过即时任务下发、批量任务下发、引擎间依赖解析等技术,大幅提升任务调度效率,同时提供MUPTI性能分析接口与GPU错误转存功能(GCD),助力开发者快速定位问题;
- 算子极致优化:自研muDNN算子库性能较cuDNN领先10%-20%,Flash Attention等关键算子效率拉满,并且推出了开源推理算子库MUSA AI Tensor Engine,提供Python API降低使用门槛,同时MUTLASS线性代数模板库支持自定义算子二次开发,形成“标准算子+模板库+开源推理库”的完整生态;
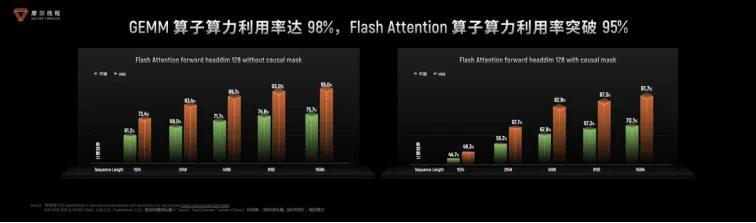
- 生态无缝兼容:全面适配PyTorch、Python等主流框架,提供MUTLASS、ACC等工具,Triton-MUSA支持Triton算子,开发者无需改写代码即可迁移项目,实现 “零门槛适配”;
- 开发者工具链:打造涵盖Torch Profiler、性能监控、调优等功能的 “百宝箱” 套件,支持按需定制工具。
通过全栈系统软件的协同作用,让摩尔线程平湖架构在训练与推理场景中,既能匹配国际顶尖产品的性能覆盖,又能实现更高效率,成为“有效算力” 的核心保障。
想让这个超级AI工厂运行起来,还需要万卡万P的超大算力,所以摩尔线程甩出的第四个武器是——自研KUAE计算集群。
其核心能力体现在三个维度:
- 全场景并行支持:作为大规模训练的基础,KUAE集群全面兼容DP、PP、EP等几乎所有并行策略,不仅能 “跑通” 各类并行模式,更通过深度优化将并行效率做到极致;
- 端到端训练闭环:覆盖从数据预处理、预训练、微调至模型评估的全流程,为开发者提供“一站式训练服务”。配合SIMUMAX性能仿真工具,集群能自动搜索最佳并行策略,像 “智能生产规划系统” 一样为模型训练量身定制优化路线;

- 大规模集群效能:基于平湖架构的KUAE2智算集群,在千卡乃至更大规模下仍能保持高效性能。对比国外主流产品,其在多场景下的性能与效率均实现领先,且具备持续优化空间,真正做到 “规模越大,效能越优”。
此外,针对大规模集群的稳定性痛点,KUAE集群还通过Checkpoint 加速方案等技术,将备份与恢复时间压缩至 “几乎可忽略”,为长周期训练提供坚实保障。这种 “从单节点到万级集群” 的全栈能力,让KUAE成为支撑 “AI 工厂” 高效运转的 “基础设施核心”。
软硬件基础+超大算力支撑,稳定性和可靠性也必不可少,所以第五件武器便是零中断容错技术。
具体来看,零中断容错技术即故障发生时仅隔离受影响节点组,其余节点继续训练,备机无缝接入,全程无中断。这一方案使KUAE集群有效训练时间占比超99%,大幅降低恢复开销。
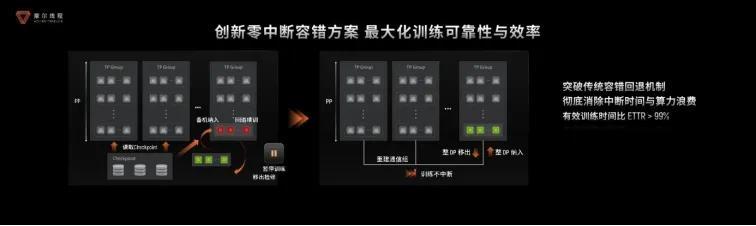
同时,KUAE集群通过多维度训练洞察体系实现动态监测与智能诊断,异常处理效率提升50%;结合集群巡检与起飞检查,训练成功率提高10%,为大规模AI训练提供稳定保障。
至此,摩尔线程的AI工厂雏形已现:即全功能GPU×MUSA架构×MUSA软件栈×KUAE集群×零中断容错技术。

全栈产品矩阵,多场景需求一站式配齐
但事实上,AI工厂也并非摩尔线程首创,英伟达此前也提出了AI工厂的概念。相比之下,摩尔线程“AI工厂”的关注点在于基于全功能GPU通用算力,以系统化创新和工程化的能力提升先进模型生产效率。
据摩尔线程介绍,目前其已构建起覆盖“云边端” 的全栈产品矩阵,从支撑万卡互联的KUAE智算集群、面向大模型训练的全功能GPU OAM模组,到适用于边缘场景的AI计算模组,再到满足桌面级图形需求的图形显卡,可一站式满足大模型训练推理、科学计算、图形渲染、智能制造等多场景需求。而在WAIC现场展示的12大Demo中,其全功能GPU在生命科学、物理仿真、智能驾驶等领域的应用案例,更直观展现了全功能GPU在多领域的落地价值。
但有一说一,要实现AI工厂搭建并非易事,既要突破硬件层面的全精度计算、万卡级集群协同等技术瓶颈,又要攻克软件生态的兼容性难题。
这就不免让人发出疑问,摩尔线程为什么要啃下这个硬骨头?
以先进算力应万难,摩尔线程要造国产算力基建
不同于国内其他GPU厂商,摩尔线程的全功能GPU本质上是用万卡集群、全栈方式,打造一个大模型训练超级加工厂,可以在算力上匹配当下大模型快速更迭的速度。这不仅匹配大模型快速迭代对算力规模的需求,更关键的是满足了其对计算精度日益严苛的要求。
要知道,现在市面上不缺单卡性能亮眼的产品,但能做到万卡集群的GPU,同时搞定软件生态、故障冗余这些 “细活儿” 的国产玩家,仍是少数。更何况,当下的高端算力市场,一边是国际巨头的供应限制,一边是国内大模型玩家的 “算力内卷”,这种供需失衡恰恰给了具备全栈能力的国产厂商机会。摩尔线程要做的,正是在这样的缝隙中,搭建起先进的国产算力基础设施—— 不是简单替代某一款芯片,而是构建从硬件到软件、从单卡到集群、从训练到推理的完整算力生态。
就目前来看,摩尔线程的这条自主化路线已经展现出了清晰路径,从自研MUSA架构到万卡集群的GPU再到覆盖云边端的全栈布局,摩尔线程的每一步都在朝着 “更高效、更好用” 的算力基建进化。
至于最终能否在高端市场占据一席之地,时间会给出答案,但至少此刻,它已经让行业看到了国产GPU的另一种可能。
最后预告一下,摩尔线程将在今年10月举办首届MUSA开发者大会,开发者们可以提前搓手期待一波了。







