

这两年,大模型训练几乎成了“高配显卡+大集群”的代名词,动辄上百张 GPU、上万亿参数,普通开发者根本碰不到。但与此同时,很多 AI 爱好者也在琢磨:如果只靠一台手边的笔记本,能不能玩点不一样的?哪怕没法训出 GPT-5 级别的怪兽模型,能不能在有限的时间里看看模型能跑到什么程度?
于是就有人提出了一个看似无聊又挺有意思的问题:“在一台 MacBook Pro 上,用五分钟时间,能训练出的最强 AI 模型是什么?”
接下来这篇实验记录,就是一次从数据选择、模型架构到各种优化尝试的探索过程,也许能给正在本地尝试大模型的开发者们带来一些灵感。
原文链接:
https://www.seangoedecke.com/model-on-a-mbp/
作者 | sean goedecke 编译 | 苏宓
出品 | CSDN(ID:CSDNnews)
“拿着我 2024 款 MacBook Pro(M4 芯片+24GB 内存),在五分钟里能训练出多强的模型?”
先把答案放在前面:我能在五分钟内训出的最佳模型,是一个大约 180 万参数的 GPT 风格 Transformer,用大约2000 万个 TinyStories 语料 token训练出来,在保留的数据集上能做到9.6 的困惑度(perplexity)。
下面是它的一个输出示例:
Once upon a time, there was a little boy named Tim. Tim had a small box that he liked to play with. He would push the box to open. One day, he found a big red ball in his yard. Tim was so happy. He picked it up and showed it to his friend, Jane. “Look at my bag! I need it!” she said. They played with the ball all day and had a great time.
(从前,有一个小男孩叫 Tim。他有一个小盒子,很喜欢拿来玩,总是推来推去想把它打开。一天,他在院子里发现了一个大红球。Tim 高兴极了,把球捡起来拿给他的朋友 Jane 看。Jane 说:“看看我的包!我需要它!” 他们拿着那个球玩了一整天,玩得特别开心。)
好吧,水平确实不算高。但别忘了——这可是只花了五分钟训出来的,效果也不错了!

挑战
这几天我一直在琢磨一个挺“无聊”的问题。说它无聊有两个原因。第一,能买得起 MacBook 的人,大可以直接去租半小时 H100 算力,分分钟就能训练出几个数量级更强的模型。第二,就算你真被迫在笔记本上训练模型,也完全没必要非得限制在五分钟(更别提,想在五分钟里训出一个强模型,本身就几乎不可能)。
一些类似的训练挑战,比如 BabyLM(
https://arxiv.org/html/2412.05149v1#S6),会对训练数据做限制,这其实是有道理的——毕竟在某些领域里,数据本来就稀缺,研究如何在少量数据下最有效地训练模型很有意义。还有人喜欢去探索“最小的强模型”,这也合理,因为小模型可以直接跑在手机或便携设备上。
可对我来说,数据和模型大小都不是问题,我唯一的限制就是时间。
在五分钟里,你根本没法喂进太多 token。也就是说,大模型完全没戏,因为模型越大,每个 token 的训练开销就越高。与其拿 10 亿参数的模型只喂 4000 个 token,不如老老实实训练一个 100 万参数的小模型,用上几百万个 token。
但模型也不能太小。比如说我可以在五分钟里往一个 1 万参数的小模型里灌一大堆 token,但它的容量小到连英语语法都学不会。训练损失在头三十秒就掉到底,然后纹丝不动,最后只能吐出一堆胡话。

提高吞吐量
所以我的第一个目标,就是搞清楚:在这种“袖珍规模”下,哪些性能优化真的有用。
我最初尝试用教科书式的 GPT-2 架构,在 Apple MPS 上的速度大约是 3000 token/秒。有意思的是,那些基于数学的优化要么没啥效果,要么反而更慢——比如 torch.compile、切到 float16 之类。
然而,我还试了梯度累积(把多个 batch 一起更新),想着内存也挺紧张,但结果显而易见:速度直接慢了一个数量级。事实证明,在 MacBook 上训练时,最大的瓶颈其实是“launch”次数(就是 GPU 接收指令、开始干活的过程)。真正适合在笔记本上训练的模型,应该能在内存里直接完成权重更新。
更有意思的是,我从 PyTorch 换到 MLX,性能几乎没什么提升。我本来还期待能有个 2 倍加速,结果完全没有。所以总结一下我的经验:
用 MPS(这是必须的);
不用在意编译或量化,没啥用;
别搞梯度累积,反而拖慢;
选最小能用的模型就行。

挑选合适的数据集
如果你手里只有一千万个 token 左右能训练,那该从哪里找数据?这大概就是 50MB 的文本:远远不够覆盖整个英语世界。假设其中 10MB 是莎士比亚,10MB 是物理教材……那模型根本学不到足够一致的模式。
我一开始用的是 Simple English Wikipedia,看上去很合理:语法和词汇更简单,对模型来说学习门槛低一些。效果还行,但也暴露出问题。比如下面是模型的输出(加粗部分是提示词):
Paris, France is a city in North Carolina.It is the capital of North Carolina, which is officially major people in Bhugh and Pennhy. The American Council Mastlandan, is the city of Retrea. There are different islands, and the city of Hawkeler: Law is the most famous city in The Confederate. The country is Guate.
说实话,以五分钟的训练时间来说,这已经挺让人惊讶了。它知道城市会在某个地方,城市还能是那个地方的首都。虽然往下就开始走样了,但语法还算正确,主题也还是“城市和国家”。问题是,它显然没有生成连贯的内容,因为它过于执着于专有名词。每句话都在说“名词 X 在名词 Y”。这就是用百科类数据训练的弊端:你更像是在背一堆编造的“事实清单”。
所以像大多数小模型实验一样,最后我还是转向了 TinyStories(
https://arxiv.org/abs/2305.07759),一个合成数据集,里面全是单段的小故事,阅读水平大概相当于 4 岁小孩。它非常适合小模型训练:故事都有完整的因果关系,甚至常常带个寓意;几乎没什么专有名词需要记忆;语言比 Simple English Wikipedia 还简单。TinyStories 的论文里证明过,一个 100 万参数的语言模型就能学得不错(不过他们可不是五分钟训完的)。这种规模的模型,笔记本完全能扛得住!

分词(Tokenization)
顺便说一下分词。我没把分词训练的时间算进那五分钟预算里,但对这种规模的模型来说影响不大。无论怎么优化,五分钟的窗口里你最多也就能喂进几百 MB 的数据,所以只要别犯傻——比如提前把整个 TinyStories 数据集全都分好词,明明只会用其中一小部分——分词只需要几秒钟。
所以我也没在这一步上花太多心思。其实我可以直接尝试用字符级训练而不是多字节 token,但多字节 token 对模型来说显然更容易学。

模型架构
那么,在五分钟的训练时间里,哪种模型架构效果最好?我基本上是随机试了一堆。
Transformer 和 LSTM
最显而易见的选择当然是 GPT-2 风格的 Transformer。它实现简单,支持完善,而且在小参数量下也能工作。我没去折腾什么 Mixture-of-Experts——在 100 万参数的模型上这么做实在太滑稽了。Dropout 我也没用,因为根本不担心过拟合,能“拟合”就谢天谢地了。
我花了大部分时间在调 Transformer 的超参数(当然,后面我也试了些别的模型)。在模型结构上,SwiGLU的效果很明显;而层数在 2-3 层时结果最好。学习率我试了很多,0.001 到 0.002 都挺合适,数值挺高,但你要在五分钟内收敛,就得这么干。我还玩过课程学习(curriculum learning)——先用小序列训练,再逐步加大——但五分钟太短,没啥意义。至于注意力机制,我对比了RoPE和可学习位置嵌入,结果发现后者明显更好。
除此之外,我还试过训练几个规模差不多的 LSTM(长短期记忆)模型,但效果一般。和 Transformer 的表现差不多(这也符合预期),不过困惑度始终不如同规模的 Transformer。
扩散模型(Diffusion)
出于好奇,我还用 D3PM训练了几个小型语言扩散模型。语言扩散模型比较难搞,因为语言 token 是离散的,不像图像的像素值那样连续,所以一旦加入噪声,就可能把一个有效 token 变成无效的。D3PM 的思路是通过“结构化”的噪声来解决这个问题,比如把一个 token 替换成 [MASK] 或者换成别的 token。
结果嘛,完全没戏。下面是模型的输出示例:
upon made The and a Now Tom wore.” and boy.”, see my small burn Max’. from day mouth a. saw. brought pink blew very was b she box a, Max day a and clothes Lily Max Spot put flew. yellow ” rece They ma你能看到,这就是纯粹的随机 token。去噪过程完全没能产出任何有意义的结构。我本来也没指望它能和 Transformer 之类竞争——直观上,一次随机放一个词来拼句子,要比顺序构造难得多——但没想到结果会烂成这样。相对而言,Transformer 和 LSTM 在训练一分钟后就能吐出语法上还算靠谱的句子了。

模型大小
最后,也是最关键的问题:在五分钟里,能训练出多大的模型才算“有用”?
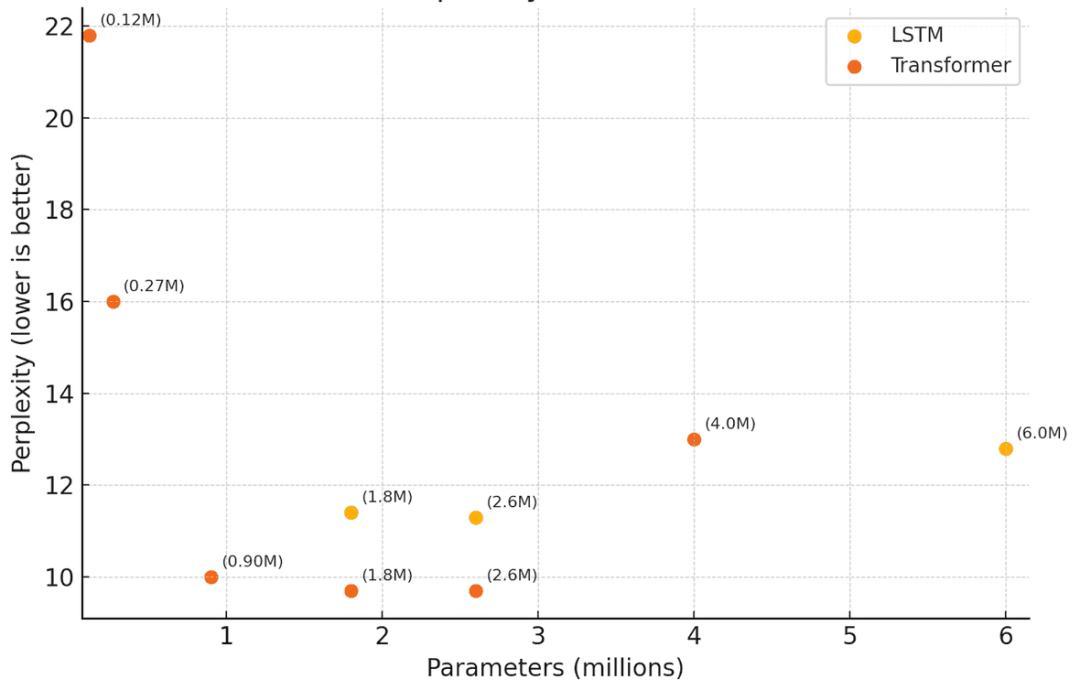
我试了各种规模:
实验证明,最佳参数量在 200 万参数左右。再大一点,五分钟内收敛不了;再小一点,第一分钟后就完全不再提升了(大概是因为参数太少,根本容纳不下训练数据里的模式)。
有意思的是,这大致符合著名的 Chinchilla scaling laws的结论:最佳模型大小 ≈ 训练 token 总数 ÷ 20。
在这个挑战里,训练 token 数量还取决于模型规模(模型越小,五分钟里能过的 token 越多)。
对一个 260 万参数模型,我能跑到56k token/秒,五分钟一共大约1680 万 token,按公式算,最佳模型规模是84 万参数。这说明 2.6M 参数确实超配了,和我的实际结果一致。
对一个 100 万参数模型,速度能到 10 万 token/秒,五分钟大约 3000 万 token,按公式最佳模型规模是 150 万参数——更接近最优,实际结果也确实更好。
我没去精确算 tokens/sec 和参数规模刚好匹配的点,但很明显最佳区间就在 100 万到 150 万参数之间。
看到这些真实的 scaling law 在这种“小挑战”里也成立,真的挺酷!

最后的想法
这次实验挺好玩的,我学到了不少关于如何在极短时间内训练超小模型的知识。每行代码我都努力去理解(之前我也写过 Transformer 的纯手工实现),不过如果没有 LLM 的帮助,我大概不会去尝试扩散模型这种方向。
当然,这个挑战对训练“强模型”并没有什么现实意义。大多数有趣的现象都发生在前五分钟之后。但我还是被惊喜到:没想到这么轻松就能训出一个大体连贯的“讲故事模型”。随着架构和笔记本 GPU 的进步,我很好奇——未来五分钟能训出怎样的模型?
【活动分享】2025 全球机器学习技术大会(ML-Summit)北京站将于 2025 年 10 月 16-17 日在北京威斯汀酒店举办。大会共 12 大主题、50+ 海内外专家,聚焦大模型技术和应用变革。详情参考官网:https://ml-summit.org (或点击原文链接)。







